详解数据挖掘与机器学习的区别与联系
1、大数据 (海量数据的存取,会设计到数据库技术)
大数据就是许多数据的聚合;
大数据的特征:
1、数据量大
2、结构复杂
3、数据更新速度快
2、机器学习 (理论和工具)
机器学习是人工智能的核心,要对大数据进行发掘,靠人工肯定是做不到的,要通过一个模型让计算机按照模型去执行,就是机器学习。
3、数据挖掘 (用机器学习对大数据进行分析,挖掘出有用的知识)
机器学习方法在大型数据库中的应用称为数据挖掘(Data Mining)
数据挖掘就是把大数据的价值发掘出来,比如根据过去30年的气象数据,通过数据挖掘,几乎可以预测明天的天气是怎么样的,有较大概率是正确的;
相关应用如:
零售业分析历史数据,来构建市场应用模型,预测产品的销售情况;
制造业的学习模型用于故障检测,来完善产品;
物理学、天文学、生物学的海量数据分析;
0、为什么写这篇博文
最近有很多刚入门AI领域的小伙伴问我:数据挖掘与机器学习之间的区别与联系。为了不每次都给他们长篇大论的解释,故此在网上整理了一些资料,整理成此篇文章,下次谁问我直接就给他发个链接就好了。
本篇文章主要阐述我个人在数据挖掘、机器学习等方面的学习心得,并搜集了网上的一些权威解释,或许不太全面,但应该会对绝大多数入门者有一个直观地解释。
本文主要参照周志华老师的:机器学习与数据挖掘 一文。有兴趣的可以自行百度,其文对人工智能、数据挖掘、机器学习等演变历程,有详细介绍。
1、概念定义
首先,第一步,我们对机器学习和数据挖掘的定义做一下总结,看看大家有没有一点体会:
机器学习:广泛的定义为 “利用经验来改善计算机系统的自身性能。”,事实上,由于“经验”在计算机系统中主要是以数据的形式存在的,因此机器学习需要设法对数据进行分析,这就使得它逐渐成为智能数据分析技术的创新源之一,并且为此而受到越来越多的关注。
数据挖掘:一种解释是“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程”,顾名思义,数据挖掘就是试图从海量数据中找出有用的知识。
2、关系与区别
2.1 关系
数据挖掘可以认为是数据库技术与机器学习的交叉,它利用数据库技术来管理海量的数据,并利用机器学习和统计分析来进行数据分析。其关系如下图:
数据挖掘受到了很多学科领域的影响,其中数据库、机器学习、统计学无疑影响最大。粗糙地说,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。由于统计学界往往醉心于理论的优美而忽视实际的效用,因此,统计学界提供的很多技术通常都要在机器学习界进一步研究,变成有效的机器学习算法之后才能再进入数据挖掘领域。从这个意义上说,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑技术。
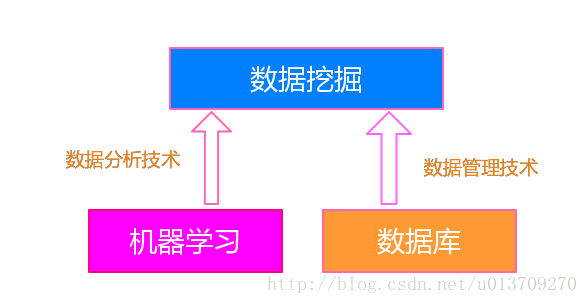
2.2 区别
数据挖掘并非只是机器学习在工业上的简单应用,他们之间至少包含如下两点重要区别:
1.传统的机器学习研究并不把海量数据作为处理对象,因此,数据挖掘必须对这些技术和算法进行专门的、不简单的改造。
2.作为一个独立的学科,数据挖掘也有其独特的东西,即:关联分析。简单地说,关联分析就是希望从数据中找出“买尿布的人很可能会买啤酒”这样看起来匪夷所思但可能很有意义的模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号