J2EE--常见面试题总结 -- ( 一)
StringBuilder和StringBuffer的区别:
String 字符串常量 不可变 使用字符串拼接时是不同的2个空间
StringBuffer 字符串变量 可变 线程安全 字符串拼接直接在字符串后追加
StringBuilder 字符串变量 可变 非线程安全 字符串拼接直接在字符串后追加
1.StringBuilder执行效率高于StringBuffer高于String.
2.String是一个常量,是不可变的,所以对于每一次+=赋值都会创建一个新的对象, StringBuffer和StringBuilder都是可变的,当进行字符串拼接时采用append方 法,在原来的基础上进行追加,所以性能比String要高,又因为StringBuffer 是 线程安全的而StringBuilder是线程非安全的,所以StringBuilder的效率高于 StringBuffer.
3.对于大数据量的字符串的拼接,采用StringBuffer,StringBuilder.
Vector,ArrayList,LinkedList之间的区别:
一、同步性
ArrayList,LinkedList是不同步的,而Vestor是同步的。所以如果不要求线程安全的话,可以使用ArrayList或LinkedList,可以节省为同步而耗费的开销。但在多线程的情况下,有时候就不得不使用Vector了。当然,也可以通过一些办法包装ArrayList,LinkedList,使他们也达到同步,但效率可能会有所降低。
二、数据增长
从内部实现机制来讲ArrayList和Vector都是使用Objec的数组形式来存储的。当你向这两种类型中增加元素的时候,如果元素的数目超出了内部数组目前的长度它们都需要扩展内部数组的长度,Vector缺省情况下自动增长原来一倍的数组长度,ArrayList是原来的50%,所以最后你获得的这个集合所占的空间总是比你实际需要的要大。所以如果你要在集合中保存大量的数据那么使用Vector有一些优势,因为你可以通过设置集合的初始化大小来避免不必要的资源开销。
三、检索、插入、删除对象的效率
ArrayList和Vector中,从指定的位置(用index)检索一个对象,或在集合的末尾插入、删除一个对象的时间是一样的,可表示为O(1)。但是,如果在集合的其他位置增加或移除元素那么花费的时间会呈线形增长:O(n-i),其中n代表集合中元素的个数,i代表元素增加或移除元素的索引位置。为什么会这样呢?以为在进行上述操作的时候集合中第i和第i个元素之后的所有元素都要执行(n-i)个对象的位移操作。
LinkedList中,在插入、删除集合中任何位置的元素所花费的时间都是一样的—O(1),但它在索引一个元素的时候比较慢,为O(i),其中i是索引的位置。
HashTable HashMap TreeMap之间的区别:
HashMap不是线程安全的,HashTable是线程安全。
HashMap允许空(null)的键和值(key),HashTable则不允许。
HashMap性能优于Hashtable。
TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)
http报文包含哪些部分:
请求首行;
请求头信息;
空行;
请求体;

post请求协议格式:
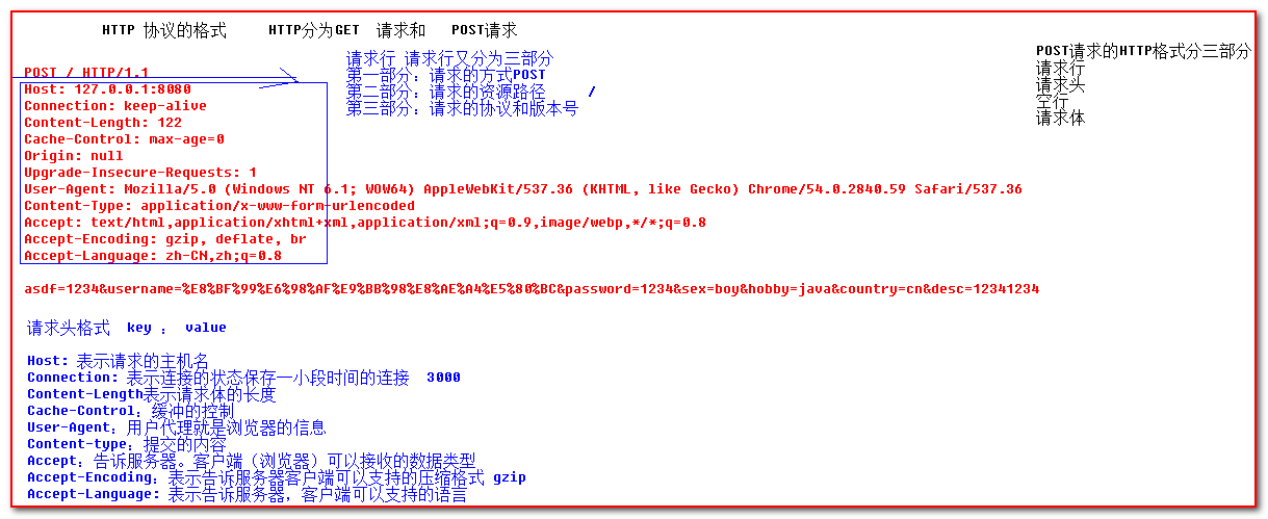
GET /Hello/index.jsp HTTP/1.1:GET请求,请求服务器路径为Hello/index.jsp,协议为1.1;
Host:localhost:请求的主机名为localhost;
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0…:与浏览器和OS相关的信息。有些网站会显示用户的系统版本和浏览器版本信息,这都是通过获取User-Agent头信息而来的;
Accept: */*:告诉服务器,当前客户端可以接收的文档类型, */*,就表示什么都可以接收;
Accept-Language: zh-CN:当前客户端支持的语言,可以在浏览器的工具à选项中找到语言相关信息;
Accept-Encoding: gzip, deflate:支持的压缩格式。数据在网络上传递时,服务器会把数据压缩后再发送;
Connection: keep-alive:客户端支持的链接方式,保持一段时间链接。
什么是Sql注入?如何防止sql注入?
所谓SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。具体来说,它是利用现有应用程序,将(恶意)的SQL命令注入到后台数据库引擎执行的能力,它可以通过在Web表单中输入(恶意)SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句。
怎么防止SQL注入,使用存储过程来执行所有的查询;检查用户输入的合法性;将用户的登录名、密码等数据加密保存。
Redirect和Forwod之间的区别?
1、从数据共享上
Forword是一个请求的延续,可以共享request的数据
Redirect开启一个新的请求,不可以共享request的数据
2、从地址栏
Forword转发地址栏不发生变化
Redirect转发地址栏发生变化
谈谈线程同步,乐观锁,悲观锁的实现?
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。
实现过程
2.悲观锁:悲观锁的实现采用的数据库内部的锁机制,一个典型的倚赖数据库的悲观锁调用:
select * from account where name=”张三” for update
这条sql 语句锁定了account 表中所有符合检索条件(name=”Erica”)的记录。本次事务提交之前(事务提交时会释放事务过程中的锁),外界无法修改这些记录。也就是我们可以在查询数据的时候先用for update把这条数据锁住,然后更改完这条数据再提交。这样别的线程没法更新这条数据,也就保证了不会丢失更新。
2.1.悲观锁带来的性能问题。我们试想一个场景:如一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进行修改时(如更改用户帐户余额),如果采用悲观锁机制,也就意味着整个操作过程中(从操作员读出数据、开始修改直至提交修改结果的全过程),数据库记录始终处于加锁状态,可以想见,如果面对几百上千个并发,这样的情况将导致怎样的后果?所以我们这个时候可以使用乐观锁。
1.乐观锁:乐观锁的实现可以通过在表里面加一个版本号的形式,下面是一个实例。

讲解:也就是每个人更新的时候都会判断当前的版本号是否跟我查询出来得到的版本号是否一致,不一致就更新失败,一致就更新这条记录并更改版本号。
Sql查询语句的优化?DB索引使用场景?
1、在表中建立索引,优先考虑where、group by使用到的字段。
2、尽量避免使用select *,返回无用的字段会降低查询效率。如下:
SELECT * FROM t
优化方式:使用具体的字段代替*,只返回使用到的字段。
3、尽量避免使用in 和not in,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE id IN (2,3)
SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3
如果是子查询,可以用exists代替。如下:
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t1.username = t2.username)
4、尽量避免使用or,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3
(PS:如果or两边的字段是同一个,如例子中这样。貌似两种方式效率差不多,即使union扫描的是索引,or扫描的是全表)
5、尽量避免在字段开头模糊查询,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE username LIKE '%li%'
优化方式:尽量在字段后面使用模糊查询。如下:
SELECT * FROM t WHERE username LIKE 'li%'
6、尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
7、尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t2 WHERE score/10 = 9
SELECT * FROM t2 WHERE SUBSTR(username,1,2) = 'li'
优化方式:可以将表达式、函数操作移动到等号右侧。如下:
SELECT * FROM t2 WHERE score = 10*9
SELECT * FROM t2 WHERE username LIKE 'li%'
8、当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE 1=1
优化方式:用代码拼装sql时进行判断,没where加where,有where加and。
Spring在项目中怎么用 ioc Aop实现原理 功能 使用场景?
ioc依赖注入的思想是通过反射机制实现的,在实例化一个类时,它通过反射调用类中set方法将事先保存在HashMap中的类属性注入到类中。 总而言之,在传统的对象创建方式中,通常由调用者来创建被调用者的实例,而在Spring中创建被调用者的工作由Spring来完成,然后注入调用者,即所谓的依赖注入or控制反转。 注入方式有两种:依赖注入和设置注入; IoC的优点:降低了组件之间的耦合,降低了业务对象之间替换的复杂性,使之能够灵活的管理对象。
AOP利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了 多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的 逻辑或责任封装起来,比如日志记录,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。
实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
AOP使用场景:
Authentication 权限检查
Caching 缓存
Context passing 内容传递
Error handling 错误处理
Lazy loading 延迟加载
Debugging 调试
logging, tracing, profiling and monitoring 日志记录,跟踪,优化,校准
Performance optimization 性能优化,效率检查
Persistence 持久化
Resource pooling 资源池
Synchronization 同步
Transactions 事务管理
异步编程的理解 :
异步编程提供了一个非阻塞的,事件驱动的编程模型。 这种编程模型利用系统中多核执行任务来提供并行,因此提供了应用的吞吐率。此处吞吐率是指在单位时间内所做任务的数量。 在这种编程方式下, 一个工作单元将独立于主应用线程而执行, 并且会将它的状态通知调用线程:成功,处理中或者失败。
我们需要异步来消除阻塞模型。其实异步编程模型可以使用同样的线程来处理多个请求, 这些请求不会阻塞这个线程。想象一个应用正在使用的线程正在执行任务, 然后等待任务完成才进行下一步。 log框架就是一个很好的例子:典型地你想将异常和错误日志记录到一个目标中, 比如文件,数据库或者其它类似地方。你不会让你的程序等待日志写完才执行,否则程序的响应就会受到影响。 相反,如果对log框架的调用是异步地,应用就可以并发执行其它任务而无需等待。这是一个非阻塞执行的例子。
为了在Java中实现异步,你需要使用Future 和 FutureTask, 它们位于java.util.concurrent包下. Future是一个接口而FutureTask是它的一个实现类。实际上,如果在你的代码中使用Future, 你的异步任务会立即执行, 并且调用线程可以得到结果promise。
下面的代码片段定义了一个包含两个方法的接口。 一个是同步方法,另外一个是异步方法。
import java.util.concurrent.Future; public interface IDataManager { // synchronous method public String getDataSynchronously(); // asynchronous method public Future<String> getDataAsynchronously(); }
值得注意的是回调模型的弊端就是当回调嵌套时很麻烦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号