11.Python使用Scrapy爬虫小Demo(新手入门)
1.前提:已安装好scrapy,且已新建好项目,编写小Demo去获取美剧天堂的电影标题名
2.在项目中创建一个python文件
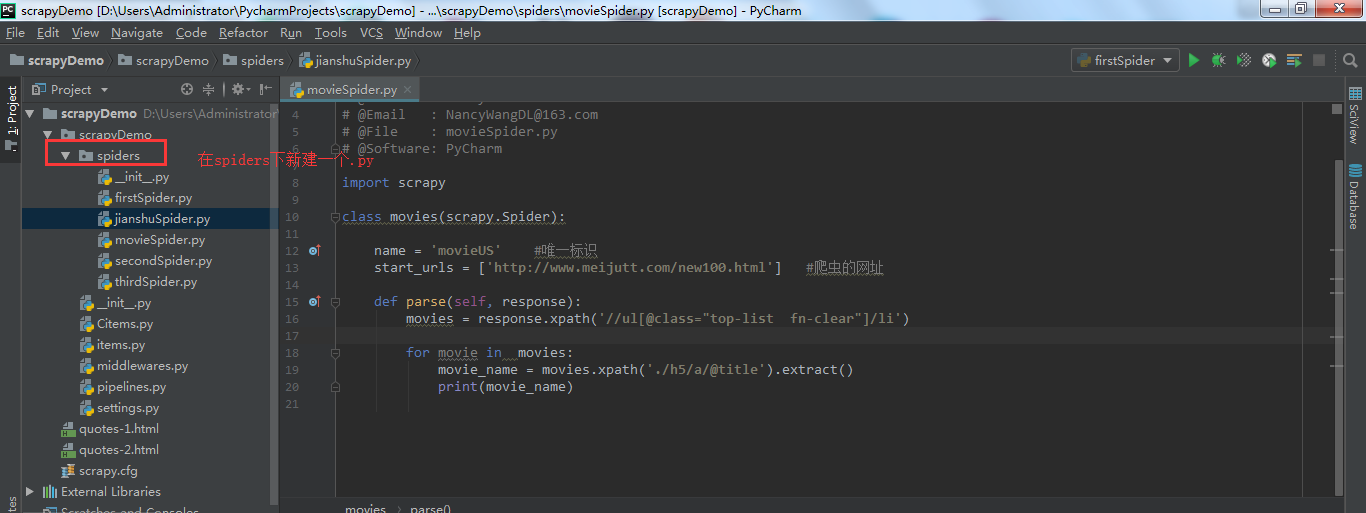
3.代码如下所示:
import scrapy
class movies(scrapy.Spider):
name = 'movieUS' #唯一标识
start_urls = ['http://www.meijutt.com/new100.html'] #爬虫的网址
def parse(self, response):
movies = response.xpath('//ul[@class="top-list fn-clear"]/li')
for movie in movies:
movie_name = movies.xpath('./h5/a/@title').extract()
print(movie_name)
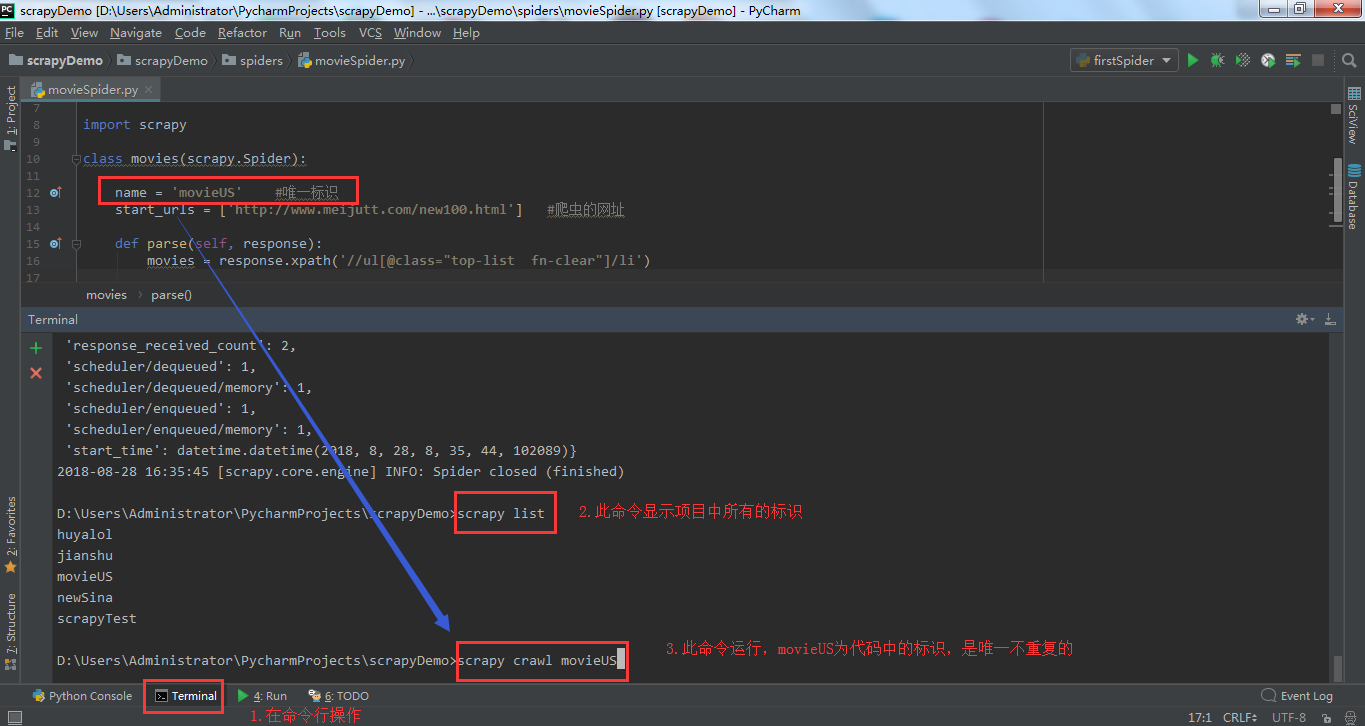
4.运行操作截图如下所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号