Java 并发性和多线程
阅读目录
- 一、介绍
- 二、多线程的优点
- 三、多线程的代价
- 四、如何创建并运行 java 线程
- 五、竞态条件与临界区
- 六、线程安全与共享资源
- 七、线程安全及不可变性
- 八、Java 内存模型
- 九、Java同步块
- 十、线程通信
- 十一、死锁
- 十二、避免死锁
一、介绍
在过去单 CPU 时代,单任务在一个时间点只能执行单一程序。之后发展到多任务阶段,计算机能在同一时间点并行执行多任务或多进程。虽然并不是真正意义上的“同一时间点”,而是多个任务或进程共享一个 CPU,并交由操作系统来完成多任务间对 CPU 的运行切换,以使得每个任务都有机会获得一定的时间片运行。
随着多任务对软件开发者带来的新挑战,程序不在能假设独占所有的 CPU 时间、所有的内存和其他计算机资源。一个好的程序榜样是在其不再使用这些资源时对其进行释放,以使得其他程序能有机会使用这些资源。
再后来发展到多线程技术,使得在一个程序内部能拥有多个线程并行执行。一个线程的执行可以被认为是一个 CPU 在执行该程序。当一个程序运行在多线程下,就好像有多个 CPU 在同时执行该程序。
多线程比多任务更加有挑战。多线程是在同一个程序内部并行执行,因此会对相同的内存空间进行并发读写操作。这可能是在单线程程序中从来不会遇到的问题。其中的一些错误也未必会在单 CPU 机器上出现,因为两个线程从来不会得到真正的并行执行。然而,更现代的计算机伴随着多核 CPU 的出现,也就意味着不同的线程能被不同的 CPU 核得到真正意义的并行执行。
如果一个线程在读一个内存时,另一个线程正向该内存进行写操作,那进行读操作的那个线程将获得什么结果呢?是写操作之前旧的值?还是写操作成功之后的新值?或是一半新一半旧的值?或者,如果是两个线程同时写同一个内存,在操作完成后将会是什么结果呢?是第一个线程写入的值?还是第二个线程写入的值?还是两个线程写入的一个混合值?因此如没有合适的预防措施,任何结果都是可能的。而且这种行为的发生甚至不能预测,所以结果也是不确定性的。
Java 是最先支持多线程的开发的语言之一,Java 从一开始就支持了多线程能力,因此 Java 开发者能常遇到上面描述的问题场景。
该系列主要关注 Java 多线程,但有些在多线程中出现的问题会和多任务以及分布式系统中出现的存在类似,因此该系列会将多任务和分布式系统方面作为参考,所以叫法上称为“并发性”,而不是“多线程”。
二、多线程的优点
尽管面临很多挑战,多线程有一些优点使得它一直被使用。这些优点是:
- 资源利用率更好
- 程序设计在某些情况下更简单
- 程序响应更快
## 资源利用率更好
想象一下,一个应用程序需要从本地文件系统中读取和处理文件的情景。比方说,从磁盘读取一个文件需要 5 秒,处理一个文件需要 2 秒。处理两个文件则需要:
5秒读取文件A 2秒处理文件A 5秒读取文件B 2秒处理文件B --------------------- 总共需要14秒
从磁盘中读取文件的时候,大部分的 CPU 时间用于等待磁盘去读取数据。在这段时间里,CPU 非常的空闲。它可以做一些别的事情。通过改变操作的顺序,就能够更好的使用 CPU 资源。看下面的顺序:
5秒读取文件A 5秒读取文件B + 2秒处理文件A 2秒处理文件B --------------------- 总共需要12秒
CPU 等待第一个文件被读取完。然后开始读取第二个文件。当第二文件在被读取的时候,CPU 会去处理第一个文件。记住,在等待磁盘读取文件的时候,CPU大 部分时间是空闲的。
总的说来,CPU 能够在等待 IO 的时候做一些其他的事情。这个不一定就是磁盘 IO。它也可以是网络的 IO,或者用户输入。通常情况下,网络和磁盘的 IO 比 CPU 和内存的 IO 慢的多。
## 程序设计更简单
在单线程应用程序中,如果你想编写程序手动处理上面所提到的读取和处理的顺序,你必须记录每个文件读取和处理的状态。相反,你可以启动两个线程,每个线程处理一个文件的读取和操作。线程会在等待磁盘读取文件的过程中被阻塞。在等待的时候,其他的线程能够使用 CPU 去处理已经读取完的文件。其结果就是,磁盘总是在繁忙地读取不同的文件到内存中。这会带来磁盘和 CPU 利用率的提升。而且每个线程只需要记录一个文件,因此这种方式也很容易编程实现。
## 程序响应更快
将一个单线程应用程序变成多线程应用程序的另一个常见的目的是实现一个响应更快的应用程序。设想一个服务器应用,它在某一个端口监听进来的请求。当一个请求到来时,它去处理这个请求,然后再返回去监听。
服务器的流程如下所述:
while(server is active){
listen for request
process request
}
如果一个请求需要占用大量的时间来处理,在这段时间内新的客户端就无法发送请求给服务端。只有服务器在监听的时候,请求才能被接收。另一种设计是,监听线程把请求传递给工作者线程(worker thread),然后立刻返回去监听。而工作者线程则能够处理这个请求并发送一个回复给客户端。这种设计如下所述:
while(server is active){
listen for request
hand request to worker thread
}
这种方式,服务端线程迅速地返回去监听。因此,更多的客户端能够发送请求给服务端。这个服务也变得响应更快。
桌面应用也是同样如此。如果你点击一个按钮开始运行一个耗时的任务,这个线程既要执行任务又要更新窗口和按钮,那么在任务执行的过程中,这个应用程序看起来好像没有反应一样。相反,任务可以传递给工作者线程(word thread)。当工作者线程在繁忙地处理任务的时候,窗口线程可以自由地响应其他用户的请求。当工作者线程完成任务的时候,它发送信号给窗口线程。窗口线程便可以更新应用程序窗口,并显示任务的结果。对用户而言,这种具有工作者线程设计的程序显得响应速度更快。
三、多线程的代价
从一个单线程的应用到一个多线程的应用并不仅仅带来好处,它也会有一些代价。不要仅仅为了使用多线程而使用多线程。而应该明确在使用多线程时能多来的好处比所付出的代价大的时候,才使用多线程。如果存在疑问,应该尝试测量一下应用程序的性能和响应能力,而不只是猜测。
设计更复杂、上下文切换的开销、增加资源消耗。
## 设计更复杂
虽然有一些多线程应用程序比单线程的应用程序要简单,但其他的一般都更复杂。在多线程访问共享数据的时候,这部分代码需要特别的注意。线程之间的交互往往非常复杂。不正确的线程同步产生的错误非常难以被发现,并且重现以修复。
## 上下文切换的开销
当 CPU 从执行一个线程切换到执行另外一个线程的时候,它需要先存储当前线程的本地的数据,程序指针等,然后载入另一个线程的本地数据,程序指针等,最后才开始执行。这种切换称为“上下文切换”(“context switch”)。CPU 会在一个上下文中执行一个线程,然后切换到另外一个上下文中执行另外一个线程。
上下文切换并不廉价。如果没有必要,应该减少上下文切换的发生。
你可以通过维基百科阅读更多的关于上下文切换相关的内容:
https://zh.wikipedia.org/wiki/%E4%B8%8A%E4%B8%8B%E6%96%87%E4%BA%A4%E6%8F%9B
## 增加资源消耗
线程在运行的时候需要从计算机里面得到一些资源。除了CPU,线程还需要一些内存来维持它本地的堆栈。它也需要占用操作系统中一些资源来管理线程。我们可以尝试编写一个程序,让它创建 100 个线程,这些线程什么事情都不做,只是在等待,然后看看这个程序在运行的时候占用了多少内存。
四、如何创建并运行 java 线程
Java 线程类也是一个 object 类,它的实例都继承自 java.lang.Thread 或其子类。 可以用如下方式用 java 中创建一个线程:
Tread thread = new Thread();
执行该线程可以调用该线程的 start()方法:
thread.start();
在上面的例子中,我们并没有为线程编写运行代码,因此调用该方法后线程就终止了。
编写线程运行时执行的代码有两种方式:一种是创建 Thread 子类的一个实例并重写 run 方法,第二种是创建类的时候实现 Runnable 接口。接下来我们会具体讲解这两种方法:
## 创建 Thread 的子类
创建 Thread 子类的一个实例并重写 run 方法,run 方法会在调用 start()方法之后被执行。例子如下:
public class MyThread extends Thread {
public void run(){
System.out.println("MyThread running");
}
}
可以用如下方式创建并运行上述 Thread 子类:
MyThread myThread = new MyThread(); myTread.start();
一旦线程启动后 start 方法就会立即返回,而不会等待到 run 方法执行完毕才返回。就好像 run 方法是在另外一个 cpu 上执行一样。当 run 方法执行后,将会打印出字符串 MyThread running。
你也可以如下创建一个 Thread 的匿名子类:
Thread thread = new Thread(){
public void run(){
System.out.println("Thread Running");
}
};
thread.start();
当新的线程的 run 方法执行以后,计算机将会打印出字符串”Thread Running”。
## 实现 Runnable 接口
第二种编写线程执行代码的方式是新建一个实现了 java.lang.Runnable 接口的类的实例,实例中的方法可以被线程调用。下面给出例子:
public class MyRunnable implements Runnable {
public void run(){
System.out.println("MyRunnable running");
}
}
为了使线程能够执行 run()方法,需要在 Thread 类的构造函数中传入 MyRunnable 的实例对象。示例如下:
Thread thread = new Thread(new MyRunnable()); thread.start();
当线程运行时,它将会调用实现了 Runnable 接口的 run 方法。上例中将会打印出”MyRunnable running”。
同样,也可以创建一个实现了 Runnable 接口的匿名类,如下所示:
Runnable myRunnable = new Runnable(){
public void run(){
System.out.println("Runnable running");
}
}
Thread thread = new Thread(myRunnable);
thread.start();
## 创建子类还是实现 Runnable 接口?
对于这两种方式哪种好并没有一个确定的答案,它们都能满足要求。就我个人意见,我更倾向于实现 Runnable 接口这种方法。因为线程池可以有效的管理实现了 Runnable 接口的线程,如果线程池满了,新的线程就会排队等候执行,直到线程池空闲出来为止。而如果线程是通过实现 Thread 子类实现的,这将会复杂一些。
有时我们要同时融合实现 Runnable 接口和 Thread 子类两种方式。例如,实现了 Thread 子类的实例可以执行多个实现了 Runnable 接口的线程。一个典型的应用就是线程池。
## 常见错误:调用 run()方法而非 start()方法
创建并运行一个线程所犯的常见错误是调用线程的 run()方法而非 start()方法,如下所示:
Thread newThread = new Thread(MyRunnable()); newThread.run(); //should be start();
起初你并不会感觉到有什么不妥,因为 run()方法的确如你所愿的被调用了。但是,事实上,run()方法并非是由刚创建的新线程所执行的,而是被创建新线程的当前线程所执行了。也就是被执行上面两行代码的线程所执行的。想要让创建的新线程执行 run()方法,必须调用新线程的 start 方法。
## 线程名
当创建一个线程的时候,可以给线程起一个名字。它有助于我们区分不同的线程。例如:如果有多个线程写入 System.out,我们就能够通过线程名容易的找出是哪个线程正在输出。例子如下:
MyRunnable runnable = new MyRunnable(); Thread thread = new Thread(runnable, "New Thread"); thread.start(); System.out.println(thread.getName());
需要注意的是,因为 MyRunnable 并非 Thread 的子类,所以 MyRunnable 类并没有 getName()方法。可以通过以下方式得到当前线程的引用:
Thread.currentThread();
因此,通过如下代码可以得到当前线程的名字:
String threadName = Thread.currentThread().getName();
## 线程代码举例
这里是一个小小的例子。首先输出执行main()方法线程名字。这个线程 JVM 分配的。然后开启 10 个线程,命名为 1~10。每个线程输出自己的名字后就退出。
public class ThreadExample {
public static void main(String[] args){
System.out.println(Thread.currentThread().getName());
for(int i=0; i<10; i++){
new Thread("" + i){
public void run(){
System.out.println("Thread: " + getName() + "running");
}
}.start();
}
}
}
需要注意的是,尽管启动线程的顺序是有序的,但是执行的顺序并非是有序的。也就是说,1 号线程并不一定是第一个将自己名字输出到控制台的线程。这是因为线程是并行执行而非顺序的。Jvm 和操作系统一起决定了线程的执行顺序,他和线程的启动顺序并非一定是一致的。
五、竞态条件与临界区
在同一程序中运行多个线程本身不会导致问题,问题在于多个线程访问了相同的资源。如,同一内存区(变量,数组,或对象)、系统(数据库,web services 等)或文件。实际上,这些问题只有在一或多个线程向这些资源做了写操作时才有可能发生,只要资源没有发生变化,多个线程读取相同的资源就是安全的。
多线程同时执行下面的代码可能会出错:
public class Counter {
protected long count = 0;
public void add(long value){
this.count = this.count + value;
}
}
想象下线程 A 和 B 同时执行同一个 Counter 对象的 add()方法,我们无法知道操作系统何时会在两个线程之间切换。JVM 并不是将这段代码视为单条指令来执行的,而是按照下面的顺序:
从内存获取 this.count 的值放到寄存器
将寄存器中的值增加 value
将寄存器中的值写回内存
观察线程 A 和 B 交错执行会发生什么:
this.count = 0;
A: 读取 this.count 到一个寄存器 (0)
B: 读取 this.count 到一个寄存器 (0)
B: 将寄存器的值加 2
B: 回写寄存器值(2)到内存. this.count 现在等于 2
A: 将寄存器的值加 3
A: 回写寄存器值(3)到内存. this.count 现在等于 3
两个线程分别加了 2 和 3 到 count 变量上,两个线程执行结束后 count 变量的值应该等于 5。然而由于两个线程是交叉执行的,两个线程从内存中读出的初始值都是 0。然后各自加了 2 和 3,并分别写回内存。最终的值并不是期望的 5,而是最后写回内存的那个线程的值,上面例子中最后写回内存的是线程 A,但实际中也可能是线程 B。如果没有采用合适的同步机制,线程间的交叉执行情况就无法预料。
当两个线程竞争同一资源时,如果对资源的访问顺序敏感,就称存在竞态条件。导致竞态条件发生的代码区称作临界区。上例中 add()方法就是一个临界区,它会产生竞态条件。在临界区中使用适当的同步就可以避免竞态条件。
六、线程安全与共享资源
允许被多个线程同时执行的代码称作线程安全的代码。线程安全的代码不包含竞态条件。当多个线程同时更新共享资源时会引发竞态条件。因此,了解 Java 线程执行时共享了什么资源很重要。
## 局部变量
局部变量存储在线程自己的栈中。也就是说,局部变量永远也不会被多个线程共享。所以,基础类型的局部变量是线程安全的。下面是基础类型的局部变量的一个例子:
public void someMethod(){
long threadSafeInt = 0;
threadSafeInt++;
}
## 局部的对象引用
对象的局部引用和基础类型的局部变量不太一样。尽管引用本身没有被共享,但引用所指的对象并没有存储在线程的栈内。所有的对象都存在共享堆中。如果在某个方法中创建的对象不会逃逸出(译者注:即该对象不会被其它方法获得,也不会被非局部变量引用到)该方法,那么它就是线程安全的。实际上,哪怕将这个对象作为参数传给其它方法,只要别的线程获取不到这个对象,那它仍是线程安全的。下面是一个线程安全的局部引用样例:
public void someMethod(){
LocalObject localObject = new LocalObject();
localObject.callMethod();
method2(localObject);
}
public void method2(LocalObject localObject){
localObject.setValue("value");
}
样例中 LocalObject 对象没有被方法返回,也没有被传递给 someMethod()方法外的对象。每个执行 someMethod()的线程都会创建自己的 LocalObject 对象,并赋值给 localObject 引用。因此,这里的 LocalObject 是线程安全的。事实上,整个 someMethod()都是线程安全的。即使将 LocalObject 作为参数传给同一个类的其它方法或其它类的方法时,它仍然是线程安全的。当然,如果 LocalObject 通过某些方法被传给了别的线程,那它就不再是线程安全的了。
## 对象成员
对象成员存储在堆上。如果两个线程同时更新同一个对象的同一个成员,那这个代码就不是线程安全的。下面是一个样例:
public class NotThreadSafe{
StringBuilder builder = new StringBuilder();
public add(String text){
this.builder.append(text);
}
}
如果两个线程同时调用同一个 NotThreadSafe 实例上的 add()方法,就会有竞态条件问题。例如:
NotThreadSafe sharedInstance = new NotThreadSafe();
new Thread(new MyRunnable(sharedInstance)).start();
new Thread(new MyRunnable(sharedInstance)).start();
public class MyRunnable implements Runnable{
NotThreadSafe instance = null;
public MyRunnable(NotThreadSafe instance){
this.instance = instance;
}
public void run(){
this.instance.add("some text");
}
}
注意两个 MyRunnable 共享了同一个 NotThreadSafe 对象。因此,当它们调用 add()方法时会造成竞态条件。
当然,如果这两个线程在不同的 NotThreadSafe 实例上调用 call()方法,就不会导致竞态条件。下面是稍微修改后的例子:
new Thread(new MyRunnable(new NotThreadSafe())).start(); new Thread(new MyRunnable(new NotThreadSafe())).start();
现在两个线程都有自己单独的 NotThreadSafe 对象,调用 add()方法时就会互不干扰,再也不会有竞态条件问题了。所以非线程安全的对象仍可以通过某种方式来消除竞态条件。
## 线程控制逃逸规则
线程控制逃逸规则可以帮助你判断代码中对某些资源的访问是否是线程安全的。
如果一个资源的创建,使用,销毁都在同一个线程内完成,
且永远不会脱离该线程的控制,则该资源的使用就是线程安全的。
资源可以是对象,数组,文件,数据库连接,套接字等等。Java 中你无需主动销毁对象,所以“销毁”指不再有引用指向对象。
即使对象本身线程安全,但如果该对象中包含其他资源(文件,数据库连接),整个应用也许就不再是线程安全的了。比如 2 个线程都创建了各自的数据库连接,每个连接自身是线程安全的,但它们所连接到的同一个数据库也许不是线程安全的。比如,2 个线程执行如下代码:
检查记录 X 是否存在,如果不存在,插入 X
如果两个线程同时执行,而且碰巧检查的是同一个记录,那么两个线程最终可能都插入了记录:
线程 1 检查记录 X 是否存在。检查结果:不存在
线程 2 检查记录 X 是否存在。检查结果:不存在
线程 1 插入记录 X
线程 2 插入记录 X
同样的问题也会发生在文件或其他共享资源上。因此,区分某个线程控制的对象是资源本身,还是仅仅到某个资源的引用很重要。
七、线程安全及不可变性
当多个线程同时访问同一个资源,并且其中的一个或者多个线程对这个资源进行了写操作,才会产生竞态条件。多个线程同时读同一个资源不会产生竞态条件。
我们可以通过创建不可变的共享对象来保证对象在线程间共享时不会被修改,从而实现线程安全。如下示例:
public class ImmutableValue{
private int value = 0;
public ImmutableValue(int value){
this.value = value;
}
public int getValue(){
return this.value;
}
}
请注意 ImmutableValue 类的成员变量 value 是通过构造函数赋值的,并且在类中没有 set 方法。这意味着一旦 ImmutableValue 实例被创建,value 变量就不能再被修改,这就是不可变性。但你可以通过 getValue()方法读取这个变量的值。
(译者注:注意,“不变”(Immutable)和“只读”(Read Only)是不同的。当一个变量是“只读”时,变量的值不能直接改变,但是可以在其它变量发生改变的时候发生改变。比如,一个人的出生年月日是“不变”属性,而一个人的年龄便是“只读”属性,但是不是“不变”属性。随着时间的变化,一个人的年龄会随之发生变化,而一个人的出生年月日则不会变化。这就是“不变”和“只读”的区别。(摘自《Java 与模式》第 34 章))
如果你需要对 ImmutableValue 类的实例进行操作,可以通过得到 value 变量后创建一个新的实例来实现,下面是一个对 value 变量进行加法操作的示例:
public class ImmutableValue{
private int value = 0;
public ImmutableValue(int value){
this.value = value;
}
public int getValue(){
return this.value;
}
public ImmutableValue add(int valueToAdd){
return new ImmutableValue(this.value + valueToAdd);
}
}
请注意 add()方法以加法操作的结果作为一个新的 ImmutableValue 类实例返回,而不是直接对它自己的 value 变量进行操作。
## 引用不是线程安全的!
重要的是要记住,即使一个对象是线程安全的不可变对象,指向这个对象的引用也可能不是线程安全的。看这个例子:
public void Calculator{
private ImmutableValue currentValue = null;
public ImmutableValue getValue(){
return currentValue;
}
public void setValue(ImmutableValue newValue){
this.currentValue = newValue;
}
public void add(int newValue){
this.currentValue = this.currentValue.add(newValue);
}
}
Calculator 类持有一个指向 ImmutableValue 实例的引用。注意,通过 setValue()方法和 add()方法可能会改变这个引用。因此,即使 Calculator 类内部使用了一个不可变对象,但 Calculator 类本身还是可变的,因此 Calculator 类不是线程安全的。换句话说:ImmutableValue 类是线程安全的,但使用它的类不是。当尝试通过不可变性去获得线程安全时,这点是需要牢记的。
要使 Calculator 类实现线程安全,将 getValue()、setValue()和 add()方法都声明为同步方法即可。
八、Java 内存模型
Java 内存模型把 Java 虚拟机内部划分为线程栈和堆。
堆和栈的知识补漏:
Java把内存分成两种,一种叫做栈内存,一种叫做堆内存
在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配。当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用。
堆内存用于存放由new创建的对象和数组。在堆中分配的内存,由java虚拟机自动垃圾回收器来管理。在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,在栈中的这个特殊的变量就变成了数组或者对象的引用变量,以后就可以在程序中使用栈内存中的引用变量来访问堆中的数组或者对象,引用变量相当于为数组或者对象起的一个别名,或者代号。
引用变量是普通变量,定义时在栈中分配内存,引用变量在程序运行到作用域外释放。而数组&对象本身在堆中分配,即使程序运行到使用new产生数组和对象的语句所在地代码块之外,数组和对象本身占用的堆内存也不会被释放,数组和对象在没有引用变量指向它的时候,才变成垃圾,不能再被使用,但是仍然占着内存,在随后的一个不确定的时间被垃圾回收器释放掉。这个也是java比较占内存的主要原因,实际上,栈中的变量指向堆内存中的变量,这就是 Java 中的指针!
具体文章参见:Java中的堆和栈的区别
这张图演示了 Java 内存模型的逻辑视图。
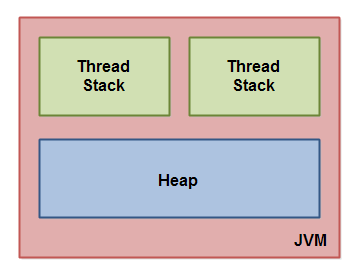
每一个运行在 Java 虚拟机里的线程都拥有自己的线程栈。这个线程栈包含了这个线程调用的方法当前执行点相关的信息。一个线程仅能访问自己的线程栈。一个线程创建的本地变量对其它线程不可见,仅自己可见。即使两个线程执行同样的代码,这两个线程任然在在自己的线程栈中的代码来创建本地变量。因此,每个线程拥有每个本地变量的独有版本。
所有原始类型的本地变量都存放在线程栈上,因此对其它线程不可见。一个线程可能向另一个线程传递一个原始类型变量的拷贝,但是它不能共享这个原始类型变量自身。
堆上包含在 Java 程序中创建的所有对象,无论是哪一个对象创建的。这包括原始类型的对象版本。如果一个对象被创建然后赋值给一个局部变量,或者用来作为另一个对象的成员变量,这个对象任然是存放在堆上。
下面这张图演示了调用栈和本地变量存放在线程栈上,对象存放在堆上。

具体分析可详见文章:http://wiki.jikexueyuan.com/project/java-concurrent/java-memory-model.html
九、Java同步块
Java 同步块(synchronized block)用来标记方法或者代码块是同步的。Java 同步块用来避免竞争。本文介绍以下内容:
- Java 同步关键字(synchronzied)
- 实例方法同步
- 静态方法同步
- 实例方法中同步块
- 静态方法中同步块
- Java 同步示例
## Java 同步关键字(synchronized)
Java 中的同步块用 synchronized 标记。同步块在 Java 中是同步在某个对象上。所有同步在一个对象上的同步块在同时只能被一个线程进入并执行操作。所有其他等待进入该同步块的线程将被阻塞,直到执行该同步块中的线程退出。
有四种不同的同步块:
- 实例方法
- 静态方法
- 实例方法中的同步块
- 静态方法中的同步块
上述同步块都同步在不同对象上。实际需要那种同步块视具体情况而定。
### 实例方法同步
下面是一个同步的实例方法:
public synchronized void add(int value){
this.count += value;
}
注意在方法声明中同步(synchronized )关键字。这告诉 Java 该方法是同步的。
Java 实例方法同步是同步在拥有该方法的对象上。这样,每个实例其方法同步都同步在不同的对象上,即该方法所属的实例。只有一个线程能够在实例方法同步块中运行。如果有多个实例存在,那么一个线程一次可以在一个实例同步块中执行操作。一个实例一个线程。
### 静态方法同步
静态方法同步和实例方法同步方法一样,也使用 synchronized 关键字。Java 静态方法同步如下示例:
public static synchronized void add(int value){
count += value;
}
同样,这里 synchronized 关键字告诉 Java 这个方法是同步的。
静态方法的同步是指同步在该方法所在的类对象上。因为在 Java 虚拟机中一个类只能对应一个类对象,所以同时只允许一个线程执行同一个类中的静态同步方法。
对于不同类中的静态同步方法,一个线程可以执行每个类中的静态同步方法而无需等待。不管类中的那个静态同步方法被调用,一个类只能由一个线程同时执行。
### 实例方法中的同步块
有时你不需要同步整个方法,而是同步方法中的一部分。Java 可以对方法的一部分进行同步。
在非同步的 Java 方法中的同步块的例子如下所示:
public void add(int value){
synchronized(this){
this.count += value;
}
}
示例使用 Java 同步块构造器来标记一块代码是同步的。该代码在执行时和同步方法一样。
注意 Java 同步块构造器用括号将对象括起来。在上例中,使用了“this”,即为调用 add 方法的实例本身。在同步构造器中用括号括起来的对象叫做监视器对象。上述代码使用监视器对象同步,同步实例方法使用调用方法本身的实例作为监视器对象。
一次只有一个线程能够在同步于同一个监视器对象的 Java 方法内执行。
下面两个例子都同步他们所调用的实例对象上,因此他们在同步的执行效果上是等效的。
public class MyClass {
public synchronized void log1(String msg1, String msg2){
log.writeln(msg1);
log.writeln(msg2);
}
public void log2(String msg1, String msg2){
synchronized(this){
log.writeln(msg1);
log.writeln(msg2);
}
}
}
在上例中,每次只有一个线程能够在两个同步块中任意一个方法内执行。
如果第二个同步块不是同步在 this 实例对象上,那么两个方法可以被线程同时执行。
### 静态方法中的同步块
和上面类似,下面是两个静态方法同步的例子。这些方法同步在该方法所属的类对象上。
public class MyClass {
public static synchronized void log1(String msg1, String msg2){
log.writeln(msg1);
log.writeln(msg2);
}
public static void log2(String msg1, String msg2){
synchronized(MyClass.class){
log.writeln(msg1);
log.writeln(msg2);
}
}
}
这两个方法不允许同时被线程访问。
如果第二个同步块不是同步在 MyClass.class 这个对象上。那么这两个方法可以同时被线程访问。
## Java同步实例
在下面例子中,启动了两个线程,都调用 Counter 类同一个实例的 add 方法。因为同步在该方法所属的实例上,所以同时只能有一个线程访问该方法。
public class Counter{
long count = 0;
public synchronized void add(long value){
this.count += value;
}
}
public class CounterThread extends Thread{
protected Counter counter = null;
public CounterThread(Counter counter){
this.counter = counter;
}
public void run() {
for(int i=0; i<10; i++){
counter.add(i);
}
}
}
public class Example {
public static void main(String[] args){
Counter counter = new Counter();
Thread threadA = new CounterThread(counter);
Thread threadB = new CounterThread(counter);
threadA.start();
threadB.start();
}
}
创建了两个线程。他们的构造器引用同一个 Counter 实例。Counter.add 方法是同步在实例上,是因为 add 方法是实例方法并且被标记上 synchronized 关键字。因此每次只允许一个线程调用该方法。另外一个线程必须要等到第一个线程退出 add()方法时,才能继续执行方法。
如果两个线程引用了两个不同的 Counter 实例,那么他们可以同时调用 add()方法。这些方法调用了不同的对象,因此这些方法也就同步在不同的对象上。这些方法调用将不会被阻塞。如下面这个例子所示:
public class Example {
public static void main(String[] args){
Counter counterA = new Counter();
Counter counterB = new Counter();
Thread threadA = new CounterThread(counterA);
Thread threadB = new CounterThread(counterB);
threadA.start();
threadB.start();
}
}
注意这两个线程,threadA 和 threadB,不再引用同一个 counter 实例。CounterA 和 counterB 的 add 方法同步在他们所属的对象上。调用 counterA 的 add 方法将不会阻塞调用 counterB 的 add 方法。
十、线程通信
线程通信的目标是使线程间能够互相发送信号。另一方面,线程通信使线程能够等待其他线程的信号。
例如,线程 B 可以等待线程 A 的一个信号,这个信号会通知线程 B 数据已经准备好了。本文将讲解以下几个 JAVA 线程间通信的主题:
- 通过共享对象通信
- 忙等待
- wait(),notify()和 notifyAll()
- 丢失的信号
- 假唤醒
- 多线程等待相同信号
- 不要对常量字符串或全局对象调用 wait()
文章地址:http://wiki.jikexueyuan.com/project/java-concurrent/thread-communication.html
十一、死锁
死锁是两个或更多线程阻塞着等待其它处于死锁状态的线程所持有的锁。死锁通常发生在多个线程同时但以不同的顺序请求同一组锁的时候。
例如,如果线程 1 锁住了 A,然后尝试对 B 进行加锁,同时线程 2 已经锁住了 B,接着尝试对 A 进行加锁,这时死锁就发生了。线程 1 永远得不到 B,线程 2 也永远得不到 A,并且它们永远也不会知道发生了这样的事情。为了得到彼此的对象(A 和 B),它们将永远阻塞下去。这种情况就是一个死锁。
文章地址:http://wiki.jikexueyuan.com/project/java-concurrent/deadlock.html
十二、避免死锁
在有些情况下死锁是可以避免的。本文将展示三种用于避免死锁的技术:
- 加锁顺序
- 加锁时限
- 死锁检测
## 加锁顺序
当多个线程需要相同的一些锁,但是按照不同的顺序加锁,死锁就很容易发生。
如果能确保所有的线程都是按照相同的顺序获得锁,那么死锁就不会发生。看下面这个例子:
Thread 1: lock A lock B Thread 2: wait for A lock C (when A locked) Thread 3: wait for A wait for B wait for C
如果一个线程(比如线程 3)需要一些锁,那么它必须按照确定的顺序获取锁。它只有获得了从顺序上排在前面的锁之后,才能获取后面的锁。
例如,线程 2 和线程 3 只有在获取了锁 A 之后才能尝试获取锁 C(译者注:获取锁 A 是获取锁 C 的必要条件)。因为线程 1 已经拥有了锁 A,所以线程 2 和 3 需要一直等到锁 A 被释放。然后在它们尝试对 B 或 C 加锁之前,必须成功地对 A 加了锁。
按照顺序加锁是一种有效的死锁预防机制。但是,这种方式需要你事先知道所有可能会用到的锁(译者注:并对这些锁做适当的排序),但总有些时候是无法预知的。
文章地址:http://wiki.jikexueyuan.com/project/java-concurrent/deadlock-prevention.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号