对【Attention is all your need!!】的理解
0、背景
Transformer是2018年谷歌大佬们联手出品的用于替代RNN的模型,单单使用注意力机制,在该文中使用了多头自注意力,仅用线性变换来提取特征信息,能够极大程度提升并行性,且准确性也有大幅提升。
Transformer被提出用于机器翻译领域,但后续在基于Transformer或BERT也被表示在其他任务中都有不错表现。
这篇论文的名字也很拉风,同时本人表示该名字极具有启示性,我非常喜欢,本文简单梳理下对它的理解。
是的,Attention Is All Your Need就是Transformer的原文出处。
1、模型详解
1.1模型架构
Transformer模型基于自编码器AutoEncoder,分为Encoder和Decocer,每部分各6层。Transformer借鉴了Seq2Seq的思想,Encoder用于提取语义特征,并层层堆叠,但只使用最后一层所提取的特征信息。 并将最后一层Encoder中的内容(Key和Value)连接输出到每一层Decoder中,Decoder同时依然层层堆叠,并在Decoder第一层开始输入Embedding信息。先甩一张经典的模型架构图:
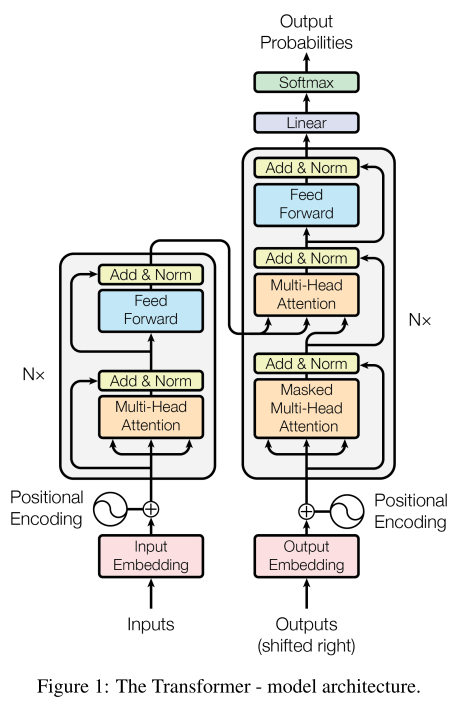
-
Encoder
上图中左侧是Encoder,输入采用了word Embedding + 位置编码Position Embedding(PE). 每个Block使用多头注意力处理Embeddings, 再接残差Add、层归一化Layer Norm, 之后再通过一层全连接网络(或叫前馈网络FFN,MLP)及残差Add,Layer Norm。 -
Decoder
上图右侧是Decoder,输入同样是用word Embedding + PE,Block基本相似,不同之处有:
1. 采用了Masked多头注意力
2. 采用句间注意力,计算Q K V相似性时,用Decoder的Q, 用Encoder的K V
需注意:Transformer在做机器翻译时是用监督学习场景下的带标注数据。如英法翻译,知道每一句话的英文和发文表述。
1.2自注意力
注意力机制自提出以来就一直被广泛使用,它的出现有效解决了长句子语义依赖问题。探究注意力的本质,就是线性加权,在NLP领域常用文本语义相似度来表示在注意力中的权重大小。
自注意力从名字理解就是自己注意自己,这一理念在机器翻译中尤为适合,因为每一个词都有依赖的语境和指代关系,通过自注意力来编码源领域语言的依赖关系,并解码转换为目标领域的词表示即完成了机器翻译。
在注意力机制中有三个变量:Query(Q)、Key(K)、Value(V),需要解释一下:
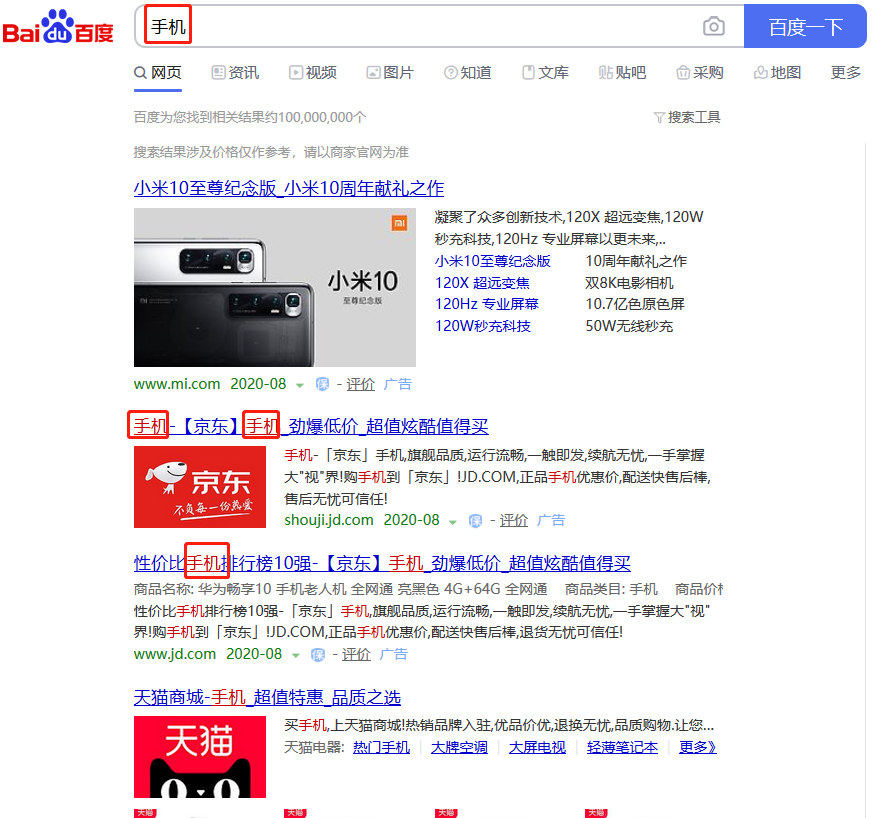
其实这三个变量是具有相同shape的向量,来源于信息检索领域,比如在Baidu中搜索:手机
- Query就是输入在搜索框的内容(通常为关键词),
- Key就是命中和Query高度相似的内容(通常为网页标题并经预处理后的关键词,只是搜索后显示的结果依然是标题),
- Value就是对应标题连接跳进去的内容 (可见K-V之间是有映射关系的)
如下图所示:
说到Transformer的自注意力其实是使用缩放点积注意力(Scaled Dot-Product Attention)
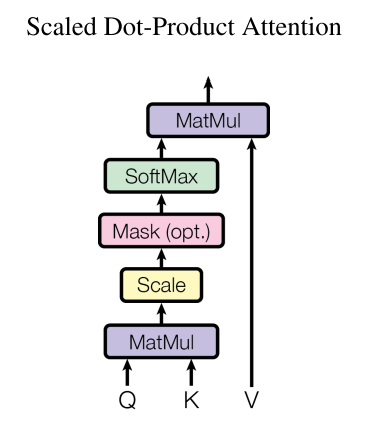
输入X(词embedding + PE)经线性变换映射成三个相同shape的向量: Q K V , 通过当前时间步的Q与该句中所有位置的K进行点乘,并经Softmax映射出Attention权重,结果再乘以V
而在实际使用中除了 Q (或K V) 向量的维度 \(\sqrt {d_k}\), 目的是避免梯度消失或梯度爆炸
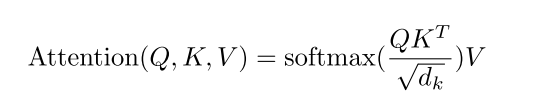
1.3多头注意力(multi-head Attention)
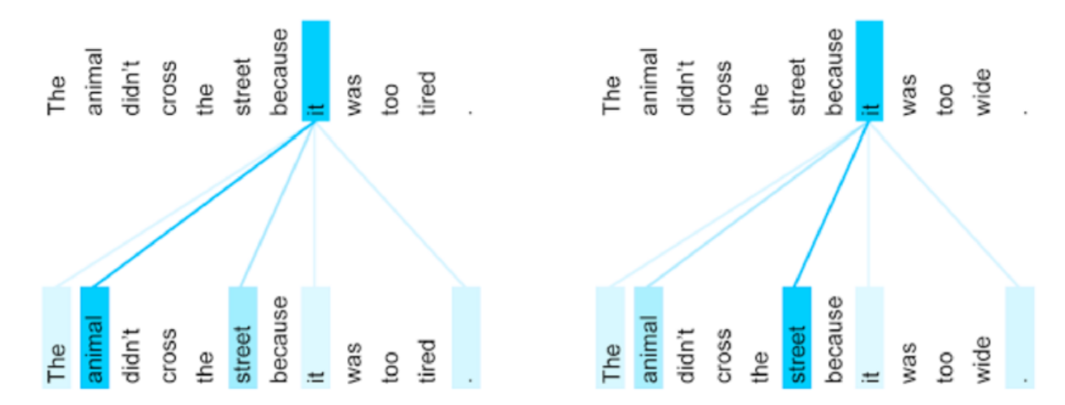
同一个词通常会注意多个不同词,而使用多头注意力则从多个角度来表示该词在整句语义信息中所对其他词的注意力,最后将多个头的结果进行拼接,如下图所示:

举例: The animal didn't cross the street because it was too tired。 其中代词it,所注意到的词会有多个,且权重不同,用multi-head 捕捉效果更好:
1.4 位置编码
原文使用sin cos函数来对每个词进行位置编码(Position Embedding PE),PE的shape和词embedding相同, 在输入模型计算时,把每个位置的PE 相加于 对应位置的词Embedding,
如下式:pos表示每个词在该句中的位置, i表示PE的维度
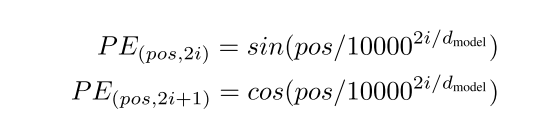
之所以为什么用sin cos函数来编码位置,据分析说是这样容易得出词在句子中的绝对位置,以及词与词之间的相对位置,相对位置可以经一次线性变换得到(使用sin cos的 和、差角公式)
这样可把一句话里不同词间的距离转为1,有效解决长依赖问题。
2、实验结果
模型刚一出,就刷新各种SOTA, 在机器翻译领域胜过了emsemble其他。

同时其并行性可以充分加速训练,时间复杂度如下图:

3、个人总结
Transformer很经典, 个人感觉原文还需详读, 先留2篇大佬的blog吧
- 需补充完善:
- embedding dropout: 避免过拟合, noisy input https://github.com/keras-team/keras/issues/7290

 浙公网安备 33010602011771号
浙公网安备 33010602011771号