对 【Evaluation methods for unsupervised word embeddings 】 的理解
零、背景介绍
- Evaluation methods for unsupervised word embeddings介绍无监督学习场景下的词向量评估方法。词嵌入Embedding 的评估方法主要分两个方向,内在评估和外在评估。
- 外在评估是以Embedding 向量作为下游任务的特征输入,并从任务的具体表现来衡量该Embedding的好坏。如词性标注和命名实体识别,外在评估仅提供一种方式来评估Embedding的好坏,且不清楚如何于其他评估方法联系。
- 内在评估是直接评估Word Embedding的语法和语义相关性。
一、Embedding介绍
- 词嵌入可视为对词\(V\)到\(D\)维实数空间的映射, \(V\rightarrow \mathbb{R}^D : \omega \to \overrightarrow{\omega}\) , 单词\(\omega\)是词表\(V\)里的单词,被映射为\(D\)维的\(\overrightarrow{\omega}\)的Embedding.
- 本文使用余弦相似度计算不同词嵌入间的距离,算式为\(similarity\left ( \omega _1 ,\omega_2 \right ) = \frac{\overrightarrow{\omega_1}\cdot\overrightarrow{\omega_2} }{\left \| \overrightarrow{\omega_1} \right \|\left \| \overrightarrow{\omega_2} \right \|}\),词\(\omega\)的最近邻单词\(v \epsilon V\setminus \left \{ \omega \right \}\)不包括词表中的\(\omega\)本身. 以\(\omega\)作为查询词降序排列与单词\(v\)的相似度\(similarity\left ( \omega ,v \right )\)
- 本文所有实验均以流行的六大无监督场景词嵌入方法为对比参照,包括连续词袋模型CBOW、C&W、GloVe、Hellinger PCA(H-PCA)、TSCCA(CCA)和稀疏随机映射。词嵌入应该能从概率矩阵中捕获大量相关信息。
- 为了尽可能的使各对比实验结果公平,鉴于C&W算法只能获取于2007年的维基百科语料库,因此使用2008-03-01的维基百科语料库训练其他5种词嵌入。 本文使用词嵌入的维度空间\(D\)为50,最后使用103647个单词做最近邻实验。
二、内在评估
内在评估分为绝对内在评估和相对内在评估,绝对内在评估使用相同的数据集和相同的下游任务
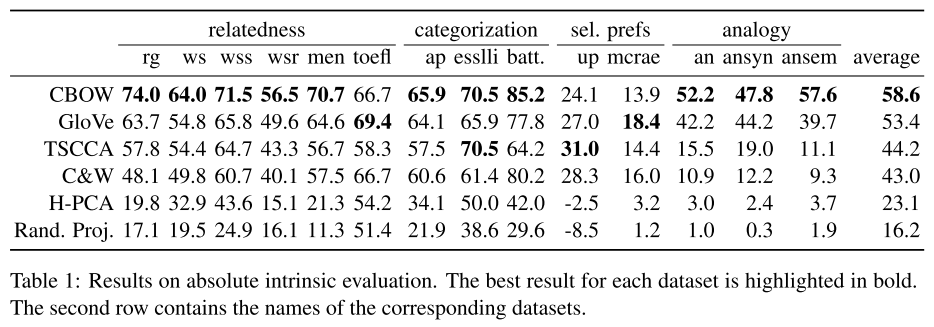
- 绝对内在评估,从四个方面来比较:
a. 相关性(Relatedness):对于一组词,相关性评价就是计算词的余弦相似度,它们的相关性得分由人类主观评价给出,通常为Spearman或 Person相关系数。
b. 类比性(Analogy):类比性的评估目标旨在找出已知一组词(a,b), 在给定(x,) 的情况下,能否映射出对应的y。
举例:(中国,北京) , (日本,y) y若为东京则表示具有较好类比性, 因为每组词的第二个词是第一个词的首都。
d. 分类(Categorization):对所有大量不同的词将其聚类并分类到不同类别,每个词都有其对应的类别标签,根据计算分类准确性来计算score得分。
d. 选择偏好(Selected Preference):评估目标是判断一个名词是更倾向做一个动词的主语还是宾语,如 人吃xxx 更多出现,而非 吃人xxx.
- 6种embedding方法的内在评估方法结果如下图(标粗为最优):
![]()
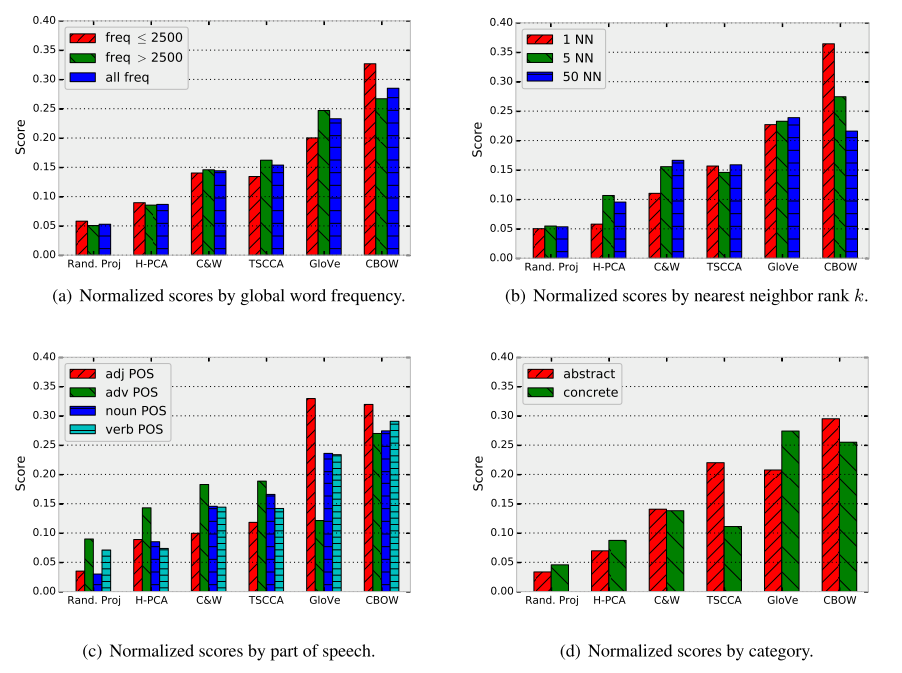
- 相对内在评估
本部分评估使用了100个不同的query word,并从词频、词性、是否为抽象词方面来衡量评估,同时使用KNN(k=1,5,50)来评估score。人为的选取与queryword最相似的词,来计算每个模型词向量表示得分
例子实验结果分别如下图:
![]()
![]()

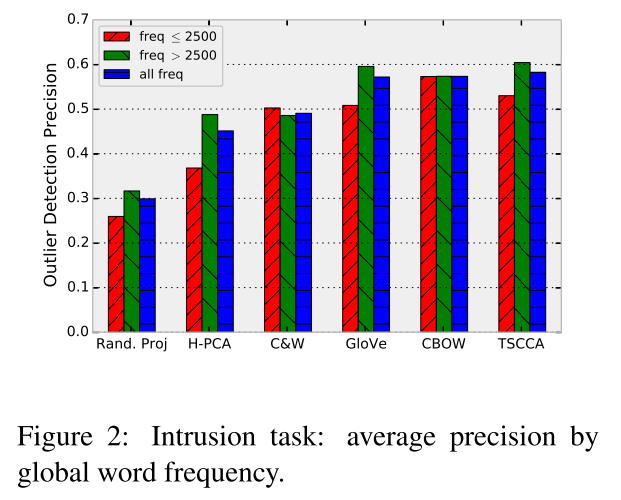
三、一致性评估(Coherence)
本部分考虑对于一个query word,人为选择2个语义相似度最高的单词以及一个语义不相关的干扰词,看上述6种embedding方法能否从4个词中找出不相关词,数据集使用相对内在评估使用的100个query word。
例子和实验结果分别如下图:

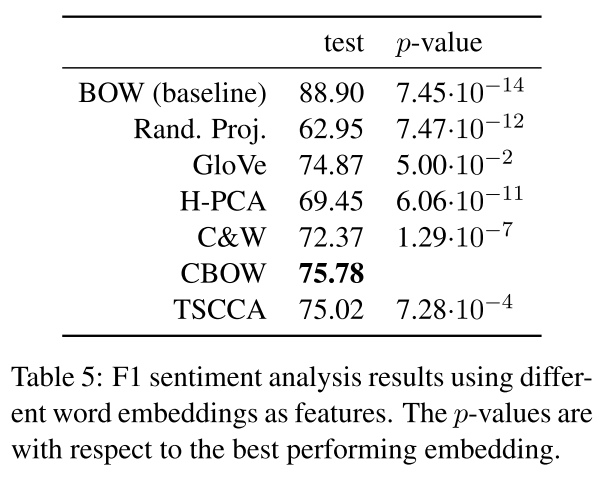
四、外在评估
该评估方法有一个隐含假设:对于任何下游任务,都有一个全局一致的好的embedding表示,然鹅该假设不成立,即不同的下游任务有各自不同最适合的embedding。 emmmm..
论文实验了2个任务:Noun phrase chunking 和 Sentiment classification 得出了上述结论。
实验结果如下图:

五、讨论
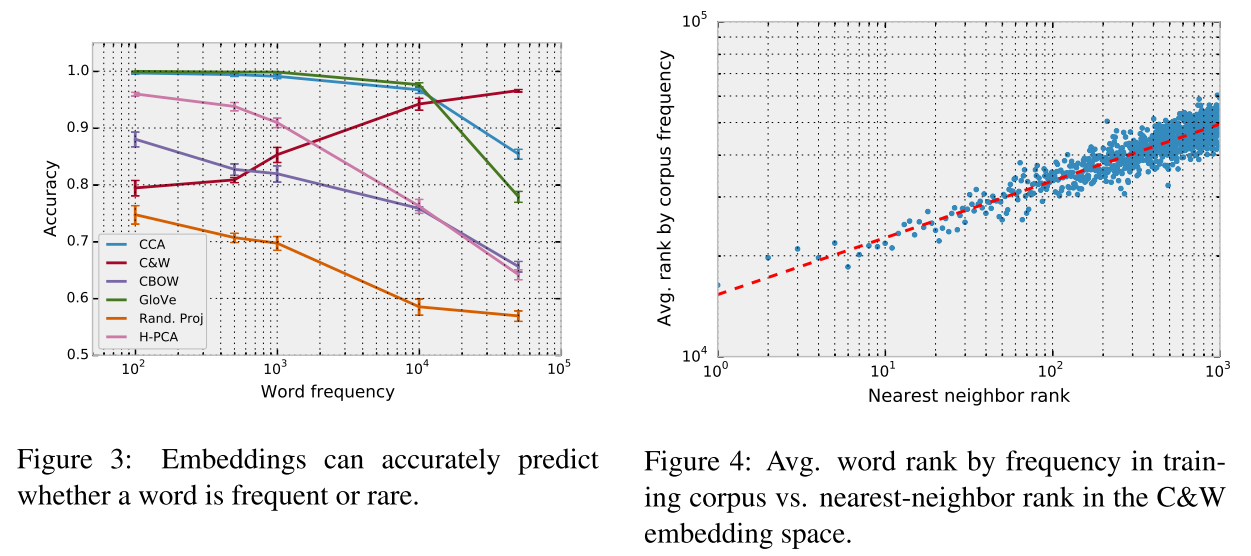
词embedding原本只是表示词语的语义信息,而作者在文中表示上述的embedding 方法或多或少的包含了词频信息,且query word的最近邻词和词频有关,同时质疑了余弦相似度作为衡量词语义相似性的合理性。
实验结果如下图:
六、个人感悟
- 该论文方向很新颖,选择了一个小众但又不得不深思的方向(评估方法)来研究,拓宽了NLP(word embedding)领域研究范围。
- 部分观点和实验结果有待进一步严谨论证.
- 沿着某些思路深挖或能有新的发现,如如何更好的做word embedding, 使其不包含词频信息且能涵盖一次多意? 前路甚远啊.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号