1.3 浅层神经网络
概览
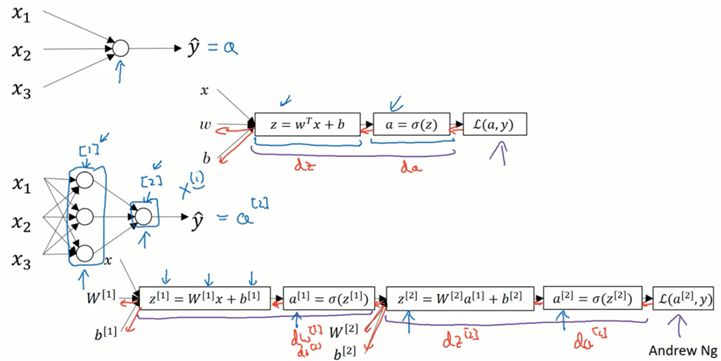
首先将一个逻辑回归拓展为神经网络大概如上图所示,需要说明上标用方括号的表示不同层,区别于之前的用圆括号表示的上标(表示不同的样本)。反向传播同理往回传就行。
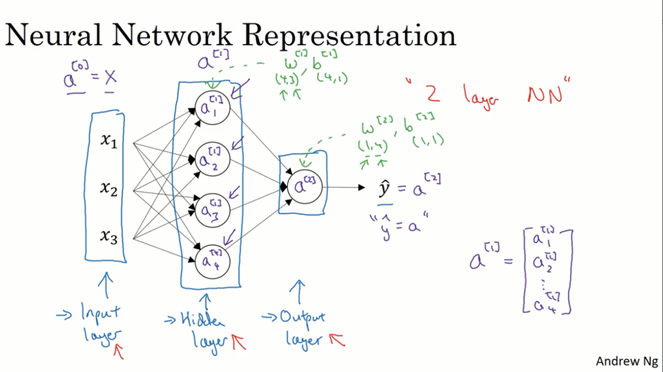
x的那一层被称为输入层,中间都是隐藏层,最后只有一个节点的是输出层。隐藏层在神经网络学习过程中,其具体数值我们是不知道的,所以称为隐藏层。
之前输入层的样本特征我们都用X表示,现在也可以用a[0]来表示,这个a也表示激活的意思,它意味着网络中不同层的值,将传递给后面的层。实际上,由于神经网络一层一层向后传递,每一层都是后一层的输入,所以直接用一个字母加上标表示各个层更统一。图中第二层(隐藏层)是a[1],并且用下标表示不同的单元,它是一个四维列向量,或称这一层有四个单元。输出层a[2]就是y^。图中的网络称为双层网络,输入层不算,隐藏层和输出层各算一层。不正式地,输入层也可以称为第零层。图中绿色字体还说了一个每一层参数维数的问题,这和上一层的输入有关,非常好理解。
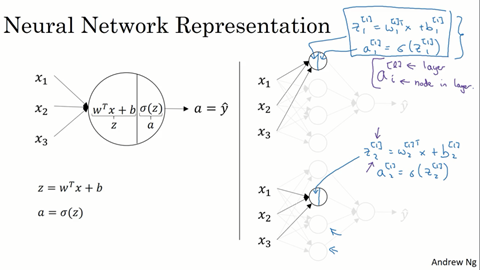
这张图简单的说就是每一个单元都算出一个z继而算出它的a来,然后作为下一个节点的输入。需要注意的是,同一层的每个单元所用的参数w和常数b都不一样。
神经网络的输出(正向传播)
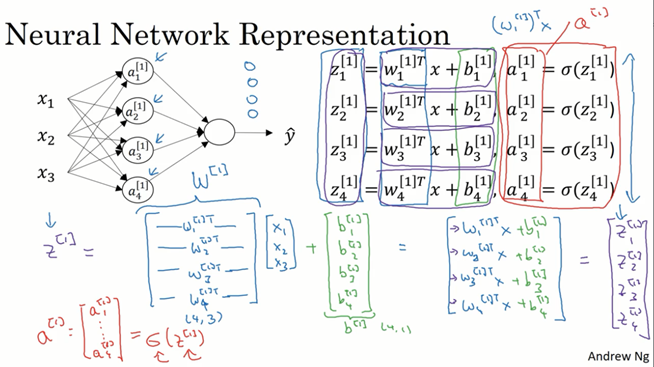
右上角为隐藏层中四个单元计算的公式,同样的,我们还是想让这些运算向量化。当我们向量化时有一条经验法则,一层中的不同节点,一般纵向的堆叠起来,如图中计算的z[1]就堆叠为一个列向量(x,w,b都一样)。
从上一节到这一节,首先考虑的问题可能是增加神经元后,计算上哪一部分扩充了?实际上上一部分的输入特征X已经是一个非常大的二维矩阵(特征数量,样本数量),而参数w是一个一维列向量(其中每个元素只是对应不同样本,参数 w值是一样的)。现在隐藏层扩充到了多个单元,其实X是没变的,特征数量和样本数量和之前一样,都可以为多个。变的是参数w的维数,因为隐藏层从一个单元变成多个单元,实际上就是将原先的一组学习变成各种不同的参数去学习同一组样本,从而组成一个大的神经网络。
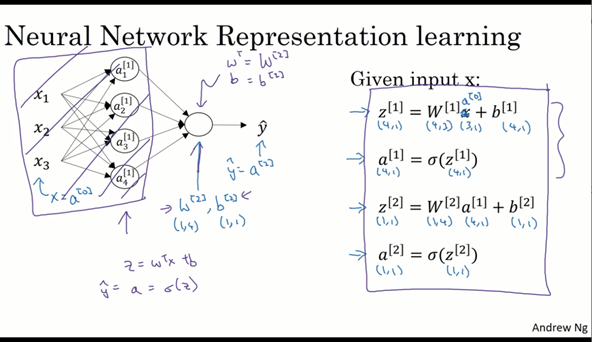
右边是该神经网络正向传播完整的四行公式(对应向量化的四行代码),其中上角标对应层,每个单元都计算z和a,以及蓝色字体标出的参数维数都在上文中提到过。
多个样本的向量化
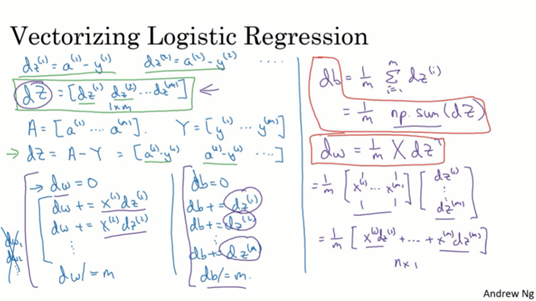

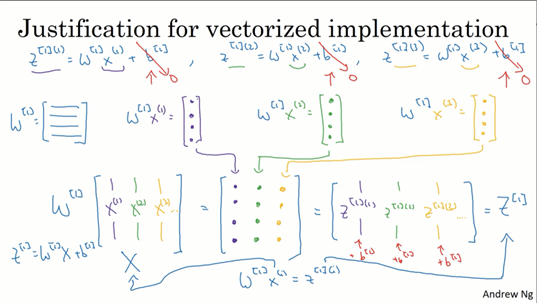
上面红字也提供到过,对比上一节和这一节的内容不难发现,上一节的参数和计算的结果z和a都是一维的,现在扩充了隐藏层的单元后在隐藏层的计算上将w,z,a都变成了二维。我们一般同一层的不同节点纵向堆叠起来(对于X来说是不同特征,但对下一层来说就是不同节点,X也可以是A[0]其实是一回事),而对于不同样本的计算结果横向的堆叠起来。
激活函数
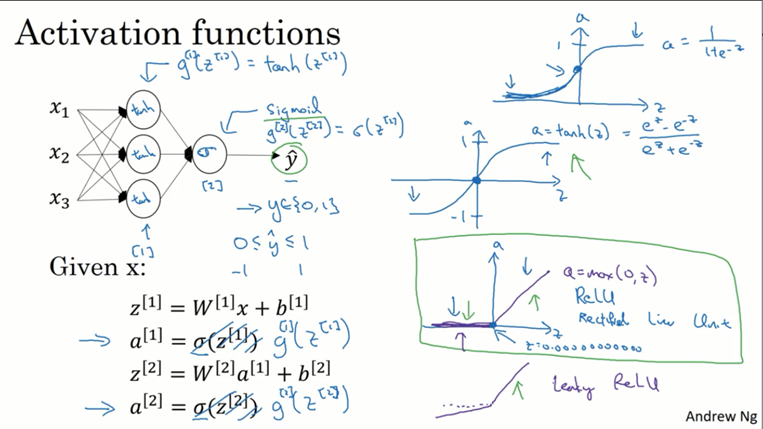
激活函数常用g()表示,在前面的课程中,我们都选择了sigmoid作为激活函数g(),其实我们还有相当多的选择。有一个叫tanh()的函数总是比sigmoid表现的更好,它在(-1,1)之间,使数据的平均值更接近0,可以让下一层学习的更好。所以在隐藏层也可以选择tanh作为激活函数,但由于在二元分类问题的输出层我们希望它表示的是概率,也就是说更希望它在(0,1)上,所以这个时候大多数选择sigmoid。由此可见在同一个神经网络上,不同层的激活函数可以不同,根据需要选择,可以用方括号的上标加以区分。
但sigmoid和tanh都有一个缺点就是当输入比较大或比较小时,曲线趋于水平,导数趋近于0,这会拖慢梯度下降的速度。
在机器学习中,还有一个非常受欢迎的激活函数是修正线性单元(ReLU),a=max(0,z),该函数左半边都是0,右半边是一个一次函数,但这个函数z=0时导数是没有定义的(因为不连续有尖),但实际中所有z都为0的概率非常低所以忽略不考虑,保险起见还可以给z=0时的导数赋值为0或1。当隐藏层不确定使用哪个激活函数时就可以使用修正线性单元,今天大多数人都在使用。它的优点在于其斜率是1,不会出现上面所说拖慢梯度下降速度的问题,这使得选择它以后学习速度会快很多。
总结:sigmoid用在二元分类问题的输出层,其他情况时可以选择更优秀的tanh,还有最常用的默认激活函数ReLU。当然,事实上很难确定什么样的选择是适合你的应用的,机器学习中还有许许多多这样的选择,例如隐藏层中选择多少个单元,参数使用什么样的权重。如果你实在不确定,你可以在先测试一下哪个效果更好。
为什么使用非线性激活函数
如果不用非线性激活函数,或使a直接等于z,那么其实我们称其为线性激活函数,那么不管神经网络有多少层,其实一直在做线性运算,最终的结果也只是参数和特征的线性组合,那么不如取消所有的隐藏层,因为复杂度并没有改变。所以除非你引入非线性,否则无法计算更有趣的函数,网络层数再多也不行。
当然,线性回归是可以使用线性激活的。翻译不精准,吴恩达的意思好像是线性回归的隐藏层也必须用非线性激活,只有输出层可以使用线性激活?
激活函数的导数
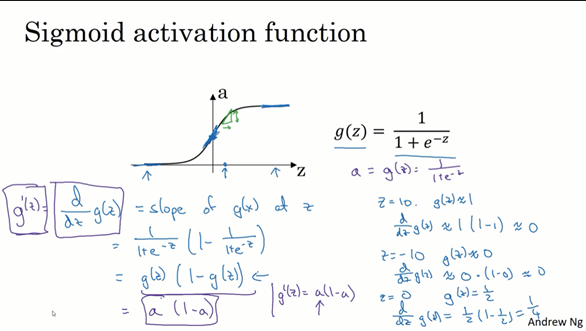
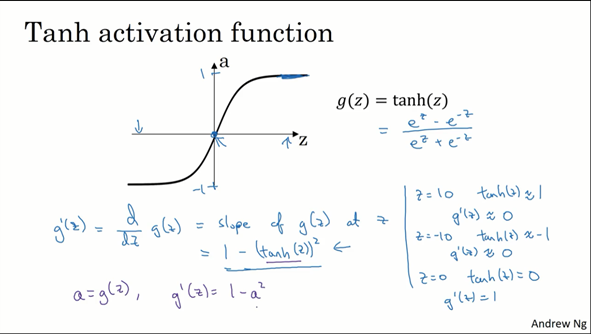
这一节介绍了各个激活函数导数如何算出来,代入a,并验证了一下数值
sigmoid:g对z的导数为什么等于a(1-a)
tanh:1-a2
ReLU的导数就是0和1比较简单不贴图了
神经网络的梯度下降

这是正向传播和反向传播的算法详细公式。
反向传播的推导过程较为复杂,后期如确有需要可以再学一遍。
随机初始化
随机初始化参数w尤为重要,在逻辑回归(隐藏层单元只有一个)中将参数初始化为0是可行的,但在神经网络中(隐藏层单元有多个),如果将参数数组w全都初始化为0,那么每个单元实际上做的都是同样的运算,失去了神经网络的意义。当w不同时,b是无所谓的,可以初始化为0。
所以在初始化参数时,应当借助python numpy使用随机数。并且通常在初始化时再×0.01,因为如果你使用sigmoid或者tanh作为激活函数,输入的z要尽可能的靠近0,否则z将落在激活函数的平滑的部分,那么学习效率将会非常非常慢。
编程
np.dot np.multiply * 三者区别
1. np.multiply()函数
函数作用:数组和矩阵对应位置相乘,输出与相乘数组/矩阵的大小一致
2. np.dot()函数
函数作用:对于秩为1的数组,执行对应位置相乘,然后再相加;
对于秩不为1的二维数组,执行矩阵乘法运算;超过二维的可以参考numpy库介绍。
3. 星号(*)乘法运算
作用:对数组执行对应位置相乘,对矩阵执行矩阵乘法运算

 浙公网安备 33010602011771号
浙公网安备 33010602011771号