RuoYi-Vue学习笔记-分析
一,还原论
还原论或还原主义(英语:Reductionism,又译化约论),是一种哲学思想,认为复杂的系统、事物、现象可以将其化解为各部分之组合来加以理解和描述。
为了防止掉入过度还原的陷阱,我们可以将系统的功能从前端到后端依次分析拆分,最后再拼接起来。在web系统中一个请求天然的可以将前后端串联起来,跟踪一个请求的流转即可还原出系统的内部处理逻辑;微服务中的 Sleuth+Zipkin等等链路追踪的系统的思想也是基于“完整服务一个请求”来处理的。
二,功能列表
从RuoYi的官网摘抄了它的特性以及功能,比较感兴趣相关的落地实践的功能如下:
|
功能/特性
|
备注
|
|
在线用户:当前系统中活跃用户状态监控。
|
如何识别用户在线?
|
|
定时任务:在线(添加、修改、删除)任务调度包含执行结果日志。
|
实时的任务调度,可以从某种程度上实现对ETL服务器的管理 |
|
代码生成:前后端代码的生成(java、html、xml、sql)支持CRUD下载。
|
CURDBoy福音
|
|
服务监控:监视当前系统CPU、内存、磁盘、堆栈等相关信息。
|
通过JVM监控操作系统参数?
|
|
完全响应式布局(支持电脑、平板、手机等所有主流设备)
|
|
|
支持多数据源,简单配置即可实现切换。
|
|
|
支持按钮及数据权限,可自定义部门数据权限。
|
数据权限如何实现
|
|
完善的XSS防范及脚本过滤,彻底杜绝XSS攻击
|
相比常见的xss完善了什么?
|
|
Maven多项目依赖,模块及插件分项目,尽量松耦合,方便模块升级、增减模块。
|
多模的项目结构参考 |
三,在线用户
通过系统监控->在线用户功能入口访问对应的页面,因为请求通过了视图层的转发,这里就不使用浏览器地址栏的URL作为请求追踪依据了,查看对应的请求如下图。通过其中的“monitor/online”定位到对应的控制器。
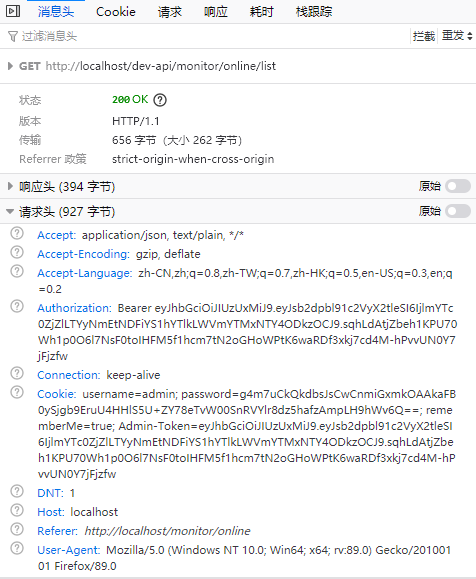
查看对应控制器的逻辑是从Redis以及MySQL数据库中查询到指定的数据而后输出到页面,其中关键点在查询Redis上登录TokenID对应的键值。逆向思考一下就可以想到,向Redis中设置这个值并更新对应值的方法就是用户识别用户是否在线以及强退的关键。顺着这个思路就可以找到TokenService这个处理用户票据的类,如下图所示:
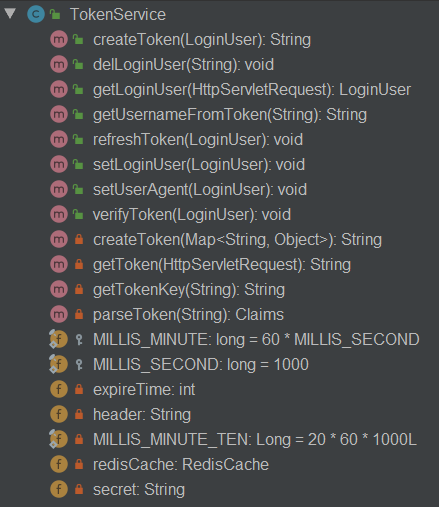
可以看到Token的生成以及刷新的方法,查看各个方法的调用关系树后发现,登录时会生成对应用户的Token,而后将其存储在每个请求的Header中,每次访问系统的时候都会通过过滤器检查该Token的有效性,从而实现了在线用户的列表获取,以及强退指定的用户。要想理清这部分逻辑需要对当前请求在RuoYi中的流转过程进行如下两个方向的梳理。
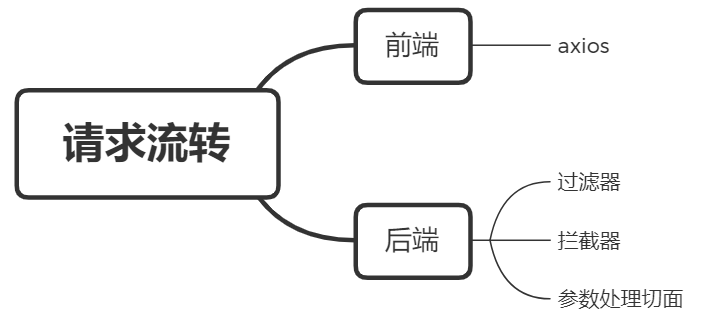
从axios处可以找到每个请求都通过config.headers['Authorization'] = 'Bearer ' + getToken()设置了token到登录的请求头中,从后端的角度查看过滤器有JwtAuthenticationTokenFilter该过滤器通过继承Spring Security提供的OncePerRequestFilter过滤器对每个请求进行一次过滤,从而实现对每个请求都进行在线状态管理的能力。至于强制退出,只需要删除用户对应的Redis上的记录即可,这里就不再赘述,感兴趣的朋友可以去阅读TokenService的源码。
四,定时任务
一般定时任务的使用场景有以下几种场景ETL每月跑数据的任务,清理冗余数据,生成报表。比较常见的定时任务都是通过注解的方式固定cron表达式来确定执行的周期以及时间,RuoYi可以动态触发以及实时的修改是否执行,这点可以深入的拆解分析下。参考“在线用户”功能的分析方案,通过前端创建任务入口@click="handleRun(scope.row)"对应调用的api地址是url: '/monitor/job/run',映射到后端的入口如下图所示:
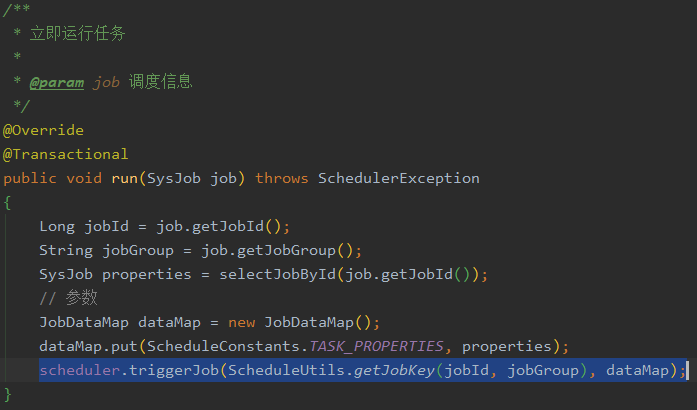
核心功能的实现和Scheduler以及ScheduleUtils相关,具体分析这两个类的方法。分析对应方法可知,前者提供了定时任务的操作接口,后者主要是对前者提供接口接口包装实现一些具体的功能,例如获取定时任务的id或获取任务的执行状态等。
五,代码生成
大部分项目里其实有很多代码都是重复的,几乎每个基础模块的代码都有增删改查的功能,而这些功能都是大同小异, 如果这些功能都要自己去写,将会大大浪费我们的精力降低效率。所以这种重复性的代码可以使用代码生成。
通过官网摘抄对应的功能描述,分解其中的技术点可以得出,要想能够根据表格生成代码需要解决以下几个技术问题:通过数据库获取表列表以及表结构,通过表结构生成模板类型的代码(包括Java代码,xml代码,sql语句,vue视图,js脚本)。
表中的信息提取可以通过如下两个sql获取:
1.获取指定数据库下的表列表,带有数据库注释
2.获取指定表的所有列

各类源码的模板文件的生成就简单了,使用Velocity模板引擎就可以在编写了模板后生成指定格式的文件了。
六,服务监控
通过分析com.ruoyi.framework.web.domain下的Server源码发现调用了com.sun.jna包下的一些方法。Java具有“一次编写,处处运行”的特性,是因为在运行时的时候,程序是运行在JVM上的,而JVM又是建立在操作系统之上的,所以通过Java来直接操作硬件或是获取硬件信息这个需求还是有点难度的。不过还好,Sun公司提供了JNI的机制,让Java使用者可以通过JNI的方式调用其他语言的程序例如通过Java调用C++。这里的服务监控就是通过OSHI实现的( OSHI is a free JNA-based (native) Operating System and Hardware Information library for Java. It does not require the installation of any additional native libraries and aims to provide a cross-platform implementation to retrieve system information, such as OS version, processes, memory and CPU usage, disks and partitions, devices, sensors, etc. 详见:https://github.com/oshi/oshi),它的原理就是通过JNA(包装过的JNI)的方式调用C的方法从而获取对应的硬件信息。
七,前端的完全响应式布局
这部分归功于集成了ElementUI的Vue,在这就不再赘述了。(毕竟不是专业的前端工程师,也说不出个一二三,哈哈哈)
八,多数据源的支持
这里其实是对SpringBoot已经支持的多数据源进行了一个切面的包装,我们从使用的方式入手分析一下底层的原理。
使用步骤:
1.在需要切换数据源Service或Mapper方法上添加@DataSource注解@DataSource(value = DataSourceType.MASTER),其中value用来表示数据源名称
2.在application-druid.yml配置从库数据源,这一步主要是为了提供连接数据库相关的信息。
3.在DataSourceType类添加数据源枚举,全局统一的数据源名称,防止错误的引用。
4.在DruidConfig配置读取数据源,这一步才将数据源装配到Spring提供的IOC容器中。
5.在DruidConfig类dataSource方法添加数据源,这里通过AbstractRoutingDataSource实现了一个能够切换数据源的Bean:DynamicDataSource
这一步可以进一步深挖,再进一步分析源码可以看到,使用的数据源都是通过DynamicDataSourceContextHolder提供的。至此,数据源的切换逻辑已经可以梳理出来了。通过给每个数据源全局唯一的一个name,然后将数据源以及这个name放置在线程池中。其中的关键点在,Spring提供的AbstractRoutingDataSource类提供了能够通过一个key来实现在多个数据源之间路由的机制。
6.在需要使用多数据源方法或类上添加@DataSource注解,其中value用来表示数据源。这里是对方法上添加注解实现对方法级别或是service级别打标签,从而实现在方法执行的时候切面DataSourceAspect能够根据标签决定使用哪一个数据库执行对应的sql。
九,数据权限
一般后端框架比较常见的权限体系大多是 基于角色的访问控制( RBAC),而这种授权体系有一个弊端就是没有职位,岗位之间的数据权限区分。
例如这个应用场景,A和B分别是不同团队的leader,要想A能够看到A团队所有人的数据,但是不能看到B团队成员的数据,一般的思路都是建立对应的角色后根据角色来实现。但是日常的情况是两个团队又是同一个部门下的,这时就需要用到数据权限了。RuoYi提供的使用场景描述如下:
在实际开发中,需要设置用户只能查看哪些部门的数据,这种情况一般称为数据权限。例如对于销售,财务的数据,它们是非常敏感的,因此要求对数据权限进行控制, 对于基于集团性的应用系统而言,就更多需要控制好各自公司的数据了。如设置只能看本公司、或者本部门的数据,对于特殊的领导,可能需要跨部门的数据, 因此程序不能硬编码那个领导该访问哪些数据,需要进行后台的权限和数据权限的控制。
数据权限的实现比较直接(框架级别的SpringSecurity的整合就不再赘述),是通过注解(@DataScope)+切面(DataScopeAspect)+超类参数绑定(BaseEntity)实现的。
值得一提的是,这个超类的参数绑定是比较有意思的,用户的数据权限在用户发起请求的时候,切面会根据注解的标签识别到这个请求,然后根据不同的用户,以及数据权限类型拼接动态sql并放置到超类的冗余参数字段,最后ORM框架则会从超类中取出对应的参数执行查询。这个处理流程很好的体现了作者对里氏代换原则以及迪米特法则的使用,所有的子类都可以用超类替换,切面并不知晓实际执行的sql。
十,完善的XSS机制
日常我们比较常见的Web安全漏洞大多都是XSS攻击导致的,通俗一点的表现就是用户在需要提交的表单中提交了一些可以由浏览器执行或渲染的脚本,导致应用的功能或数据的损坏以及泄露。一般的处理方案都是通过一个全局的过滤器,然后通过关键字匹配实现不安全的参数的过滤。方法是比较简单,方案也通俗易懂,但是总是会有一些这样或那样的特例漏掉,这里使用了“HTMLFilter”来防止出现遗漏的问题,另外这里有一个比较难以察觉的坑,request的流式读取只允许一次,也就是说如果在过滤器或是切面中对request的流进行了读取,那么后续处理请求就无法获取到对应的流中的信息了。通用的解决方案是扩展HttpServletRequestWrapper这一J2ee提供的包装类,在其中设置一个公共成员,把流中的信息存储在这里就可以避免流的一次读取导致的问题了。
十一,Maven多模项目结构
以往的巨石项目大多是“一个项目,一个模块,一个框架,一把梭”,项目结构大多是常见的J2EE那一套,src目录下放源码,webapp下方静态资源以及未分离的前端页面。
RuoYi的前后端分离的项目结构,首先将前后端分离,后端只提供接口的校验以及数据的提供,前端提供页面以及业务的交互,路由的控制。(虽然这让后端开发的我无比狂喜,但是也让全栈的我心在滴血,毕竟巨石项目的前端是比较简单的,分离之后就意味着全新的技术栈)
下面这个表格列出了分包以及源码的依赖度的优先级(越是底层,优先级越高),可以看出来,应用分包这块是按照领域以及业务来区分的。
|
分包名称
|
功能
|
优先级
|
备注
|
|
ruoyi-admin
|
web服务入口
|
1
|
通过功能参考具体实现
|
|
ruoyi-common
|
通用工具
|
3
|
|
|
ruoyi-framework
|
framework框架核心
|
2
|
通用性解决方案
|
|
ruoyi-generator
|
代码生成
|
|
|
|
ruoyi-quartz
|
quartz定时任务
|
|
|
|
ruoyi-system
|
系统模块:系统bo的CRUD
|
|
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号