leetcode648.字典树记录
题目
在英语中,我们有一个叫做 词根(root) 的概念,可以词根后面添加其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典 dictionary 和一个用空格分隔单词形成的句子 sentence。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
你需要输出替换之后的句子。
示例 1:
输入:dictionary = ["cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
示例 2:
输入:dictionary = ["a","b","c"], sentence = "aadsfasf absbs bbab cadsfafs"
输出:"a a b c"
提示:
1 <= dictionary.length <= 1000
1 <= dictionary[i].length <= 100
dictionary[i] 仅由小写字母组成。
1 <= sentence.length <= 10^6
sentence 仅由小写字母和空格组成。
sentence 中单词的总量在范围 [1, 1000] 内。
sentence 中每个单词的长度在范围 [1, 1000] 内。
sentence 中单词之间由一个空格隔开。
sentence 没有前导或尾随空格。
1.Map解法
解题思路
使用map存储所有字典里的词根,逐个枚举sentence里的单词,并枚举单词的所有可能词根,一旦出现就结束枚举
代码
class Solution {
public String replaceWords(List<String> dictionary, String sentence) {
String[] sentences = sentence.split(" ");
Map<String,Boolean> map = new HashMap<>();
for(int i = 0;i < dictionary.size();i++){
map.put(dictionary.get(i),true);
}
for(int i = 0;i < sentences.length;i++){
String word = sentences[i];
for(int j = 0;j < word.length();j++){
String sub = word.substring(0,j+1);
if(map.containsKey(sub)){
sentences[i] = sub;
break;
}
}
}
return String.join(" ",sentences);
}
}
2.字典树
解题思路
与方法一类似,但是存储前缀的结构由hash变为字典树。这样我们就不用枚举一个单词的所有前缀了,而是可以直接将单词的每个字母在字典树中进行搜索。
字典树如图所示:
1.每个结点具有children[26]的指针数组,每个指针对应一个字母。指针为null则相当于没存字母,指针不为null则视为存储该位置对应的字母
2.在代表最后一个字母的指针指向的结点处存储词根的值
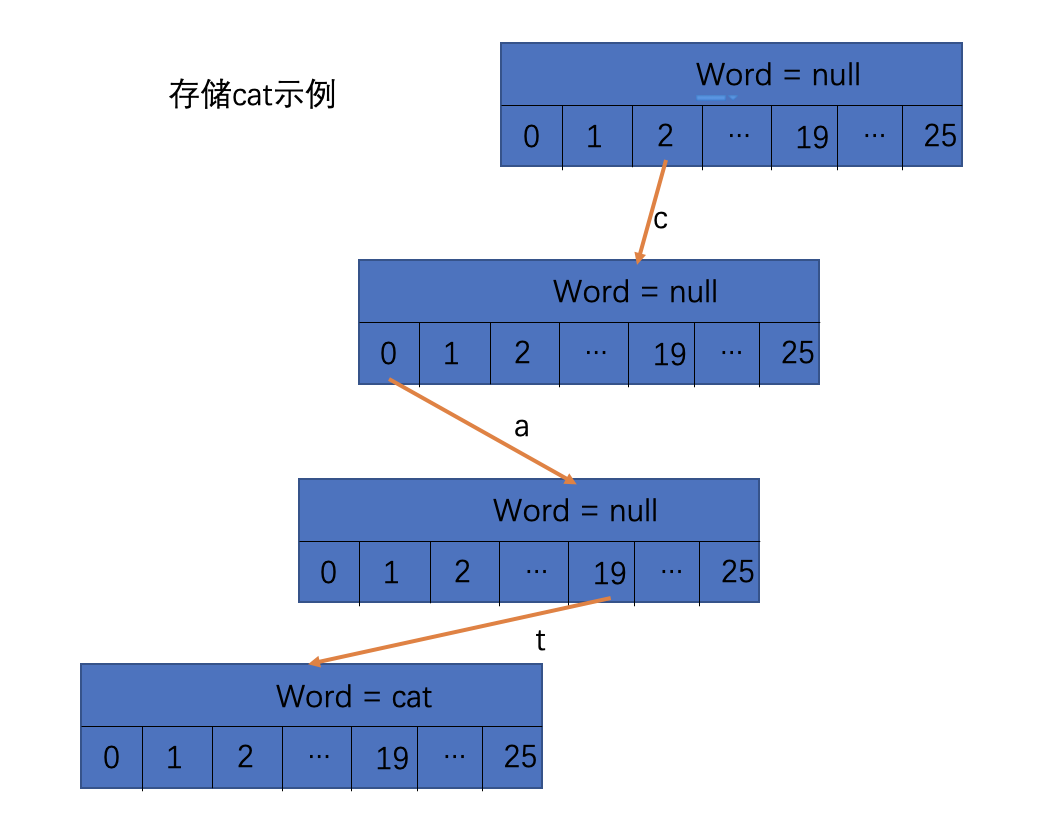
在方法1中需要枚举单词的前缀长度,再进行截取前缀长度的子串。在使用字典树之后直接在字典树中搜索单词的字母即可。
时间由方法1的200s提高到10s。
代码
public class Solution {
// 字典树解法
public String replaceWords(List<String> dictionary, String sentence) {
// 初始化字典树:把词根用字典树存储
TrieNode trie = new TrieNode();
for(int i = 0;i < dictionary.size();i++){
TrieNode p = trie;
String prefix= dictionary.get(i);
for(int j = 0;j < prefix.length();j++){
char temp = prefix.charAt(j);
if(p.childerns[temp - 'a'] == null){
p.childerns[temp - 'a'] = new TrieNode();
}
p = p.childerns[temp - 'a'];
}
// 存储完一个词根,记录词根完结点
p.word = prefix;
}
// 使用字典树进行查询
List<String> ans = new ArrayList<>();
String[] sentences = sentence.split(" ");
for(int i = 0;i < sentences.length;i++){
String word = sentences[i];
TrieNode p = trie;
// 在字典树中查找word的最短词根
// 枚举word的每个字母
for(int j = 0;j < word.length();j++){
char letter = word.charAt(j);
// 当前字母没在字典树中存 || 已经找到了一个词根
if(p.childerns[letter-'a'] == null || p.word != null) break;
p = p.childerns[letter - 'a'];
}
ans.add(p.word == null ? word : p.word);
}
return String.join(" ",ans);
}
}
class TrieNode {
String word;
TrieNode[] childerns;
public TrieNode() {
childerns = new TrieNode[26];
}
}
C++版本
struct Trie {
unordered_map<char, Trie *> children;
};
class Solution {
public:
string replaceWords(vector<string>& dictionary, string sentence) {
Trie *trie = new Trie();
for (auto &word : dictionary) {
Trie *cur = trie;
for (char &c: word) {
if (!cur->children.count(c)) {
cur->children[c] = new Trie();
}
cur = cur->children[c];
}
cur->children['#'] = new Trie();
}
vector<string> words = split(sentence, ' ');
for (auto &word : words) {
word = findRoot(word, trie);
}
string ans;
for (int i = 0; i < words.size() - 1; i++) {
ans.append(words[i]);
ans.append(" ");
}
ans.append(words.back());
return ans;
}
vector<string> split(string &str, char ch) {
int pos = 0;
int start = 0;
vector<string> ret;
while (pos < str.size()) {
while (pos < str.size() && str[pos] == ch) {
pos++;
}
start = pos;
while (pos < str.size() && str[pos] != ch) {
pos++;
}
if (start < str.size()) {
ret.emplace_back(str.substr(start, pos - start));
}
}
return ret;
}
string findRoot(string &word, Trie *trie) {
string root;
Trie *cur = trie;
for (char &c : word) {
if (cur->children.count('#')) {
return root;
}
if (!cur->children.count(c)) {
return word;
}
root.push_back(c);
cur = cur->children[c];
}
return root;
}
};

 浙公网安备 33010602011771号
浙公网安备 33010602011771号