Android解析XML三种方式(PULL、SAX、DOM)
本篇博客重点介绍Android中三种解析XML的方式,包括PULL、SAX、DOM,当然不止这些,还可以用第三方的jar包提供的解析,只是这三种在Android中比较常用吧。再顺便介绍一下AndroidTestCase的用法,用来测试所写的解析业务逻辑是否正确。
本篇博客使用的xml文件如下:
student.xml
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student id="1003">
<name>ZhangSan</name>
<age>23</age>
<score>89</score>
</student>
<student id="1004">
<name>LiSi</name>
<age>24</age>
<score>72</score>
</student>
<student id="1005">
<name>WangWu</name>
<age>25</age>
<score>79</score>
</student>
</students>
各字体属性应该很清楚了,这里不再介绍,也不是重点。
此xml文件放在Android工程下面的assets目录下面,等待解析。。。
再建一个类Student.java
package com.and.xml;
public class Student {
private int id;
private String name;
private int age;
private float score;
public Student() {
super();
}
public Student(int id, String name, int age, float score) {
super();
this.id = id;
this.name = name;
this.age = age;
this.score = score;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public float getScore() {
return score;
}
public void setScore(float score) {
this.score = score;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return "Id:" + this.id + ",Name:" + this.name + ",Age" + this.age
+ ",Score:" + this.score;
}
}
下面分别介绍三种解析方式。
第一种:PULL解析
PullParseService.java
至此,PULL解析的核心业务完成了,怎样来测试有没有问题呢?一般情况下,都是在Activity输出调试日志,根据调试日志判断是否解析成功。这里换一种方式,用Android的测试用例来测试一下。
TestParseService.java
package com.and.test;
import java.io.InputStream;
import java.util.List;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.InputSource;
import org.xml.sax.XMLReader;
import com.and.xml.DomParseService;
import com.and.xml.PullParseService;
import com.and.xml.SaxParserService;
import com.and.xml.Student;
import android.test.AndroidTestCase;
import android.util.Log;
/**
* 测试三种解析方式(Pull、SAX、Dom)
*
* @author And 2012-02-29
*/
public class TestParseService extends AndroidTestCase {
private static final String TAG = "testService";
InputStream input;
List<Student> students;
public void init() throws Exception {
input = this.getContext().getAssets().open("students.xml");
}
// 测试Pull解析方式
public void testPull() throws Exception {
init();
students = PullParseService.getStudents(input);
for (Student stu : students) {
Log.i(TAG, stu.toString());
}
}
// 测试SAX解析方式
public void testSAX() throws Exception {
init();
SAXParserFactory fac = SAXParserFactory.newInstance();
XMLReader reader = fac.newSAXParser().getXMLReader();
SaxParserService saxHandler = new SaxParserService();
reader.setContentHandler(saxHandler);
reader.parse(new InputSource(input));
students = saxHandler.getParseData();
for (Student stu : students) {
Log.i(TAG, stu.toString());
}
}
// 测试DOM解析方式
public void testDom() throws Exception {
init();
students = DomParseService.getPersonsByParseXml(input);
for (Student stu : students) {
Log.i(TAG, stu.toString());
}
}
}
注意一定要继承自AndroidTestCase这个类。这个文件中写了所有三种解析的测试方法,其它的忽视吧,只看testPull方法,它是用来测试上面所写的PULL解析业务的 。
那么怎样测试呢?
鼠标选中testPull方法名——>右键——>Run As——>Anroid JUnit Test
会提示以下错误:
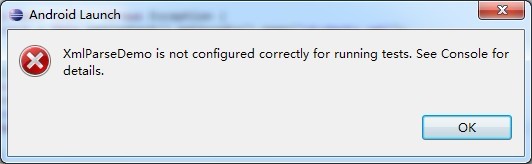
大概意思就是没有配置running tests.控制台输出:
XmlParseDemo does not specify a android.test.InstrumentationTestRunner instrumentation or does not declare uses-library android.test.runner in its AndroidManifest.xml
从上面的提示信息可知,需要在AndroidManifest.xml中作一些配置,包括instrumentation和uses-library的配置
在AndroidManifest.xml文件中添加如下两行
<instrumentation android:targetPackage="com.and.xml" android:name="android.test.InstrumentationTestRunner"></instrumentation>
<uses-library android:name="android.test.runner"/>
注意添加位置:
第一句跟application节点同级。
第二句跟activity同级。
上面介绍的方法是手动代码添加,下面介绍一种图形化的方式,只需要点击鼠标就可以搞定。
打开AndroidManifest.xml文件
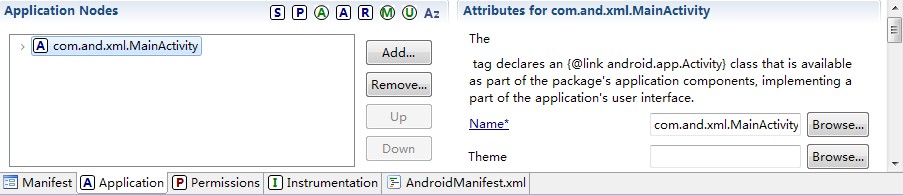
点击Add...
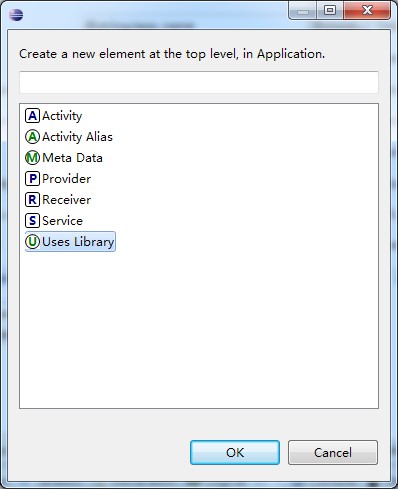

这样,use-library就添加好了
同样的方法添加instrumentation属性
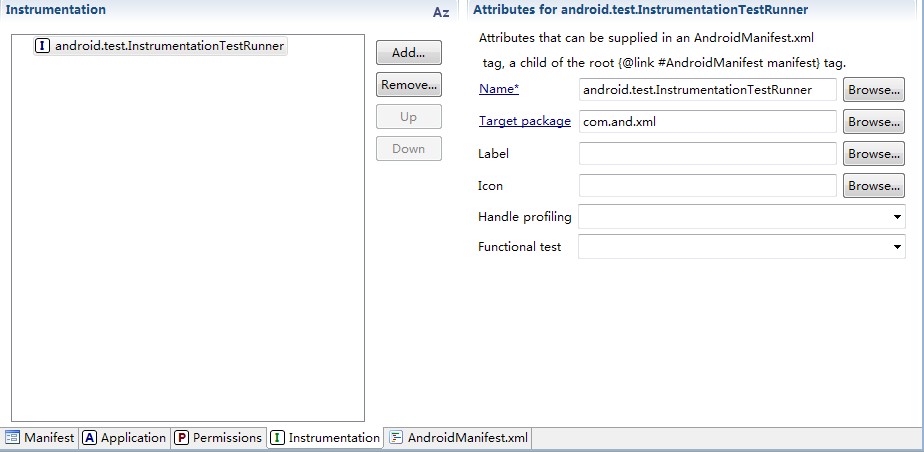
注意Target package后面的内容:com.and.xml包
整个工程目录结构如图:
然后查看一下AndroidManifest.xml的内容,已经包含了刚才添加的那两句了:
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.and.xml"
android:versionCode="1"
android:versionName="1.0" >
<uses-sdk android:minSdkVersion="7" />
<instrumentation android:targetPackage="com.and.xml" android:name="android.test.InstrumentationTestRunner"></instrumentation>
<application
android:icon="@drawable/ic_launcher"
android:label="@string/app_name" >
<activity
android:label="@string/app_name"
android:name="com.and.xml.MainActivity" >
<intent-filter >
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
<uses-library android:name="android.test.runner"/>
</application>
</manifest>
OK,然后继续之前的操作“鼠标选中testPull方法名——>右键——>Run As——>Anroid JUnit Test”

如果出现类似这样的页面,就表示测试用例建立成功,并且测试方法通过
左上角的绿色条,表示测试方法通过,右下角的调试日志输出,通过判断可以知道解析成功。
第二种:SAX解析
SaxParserService.java
package com.and.xml;
import java.util.ArrayList;
import java.util.List;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
/**
* SAX解析示例
*
* @author Administrator
*
*/
public class SaxParserService extends DefaultHandler {
List<Student> data = null;
Student stu = null;
String tag = "";
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
if (stu != null) {
String str = new String(ch, start, length);
if (tag.equals("name")) {
stu.setName(str);
} else if (tag.equals("age")) {
stu.setAge(Integer.parseInt(str));
} else if (tag.equals("score")) {
stu.setScore(Float.parseFloat(str));
}
}
}
@Override
public void endDocument() throws SAXException {
super.endDocument();
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
super.endElement(uri, localName, qName);
if (localName.equals("student") && stu != null) {
data.add(stu);
stu = null;
}
tag = "";
}
@Override
public void startDocument() throws SAXException {
super.startDocument();
data = new ArrayList<Student>();
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
tag = localName;
if (localName.equals("student")) {
stu = new Student();
}
if (attributes.getValue(0) != null) {
stu.setId(Integer.parseInt(attributes.getValue(0)));
}
}
public List<Student> getParseData() {
return data;
}
}
注意一定要继承自DefaultHandler,然复写里面的方法,这些方法名字根据字面意思很容易理解它的作用。
然后通过上面的的测试文件,按照类似的方法测试一下testSAX()方法,如果出现绿条和日志输出的话,表明解析业务逻辑成功。
第三种:DOM解析
DomParseService.java
package com.and.xml;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
/**
* DOM解析示例
*/
/**
* DOM解析器在解析XML文档时,会把文档中的所有元素,按照其出现的层次关系,解析成一个个Node对象(节点)。Node对象提供了一系列常量来代表结点的类型
* ,当开发人员获得某个Node类型后,就可以把Node节点转换成相应节点对象(Node的子类对象),以便于调用其特有的方法。
* Node对象提供了相应的方法去获得它的父结点或子结点。编程人员通过这些方法就可以读取整个XML文档的内容、或添加、修改、删除XML文档的内容.
*
* 缺点: 一次性的完全加载整个xml文件,需要消耗大量的内存。
*/
public class DomParseService {
public static List<Student> getPersonsByParseXml(InputStream is) throws Exception {
List<Student> persons = new ArrayList<Student>();
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(is);
Element root = document.getDocumentElement();
NodeList items = root.getElementsByTagName("student");// 得到所有person节点
for (int i = 0; i < items.getLength(); i++) {
Student Student = new Student();
Element personNode = (Element) items.item(i);
Student.setId(new Integer(personNode.getAttribute("id")));
// 获取person节点下的所有子节点(标签之间的空白节点和name/age元素)
NodeList childsNodes = personNode.getChildNodes();
for (int j = 0; j < childsNodes.getLength(); j++) {
Node node = (Node) childsNodes.item(j); // 判断是否为元素类型
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element childNode = (Element) node;
// 判断是否name元素
if ("name".equals(childNode.getNodeName())) {
// 获取name元素下Text节点,然后从Text节点获取数据
Student.setName(childNode.getFirstChild().getNodeValue());
} else if ("age".equals(childNode.getNodeName())) {
Student.setAge(new Short(childNode.getFirstChild().getNodeValue()));
} else if ("score".equals(childNode.getNodeName())) {
Student.setScore(Float.parseFloat(childNode.getFirstChild().getNodeValue()));
}
}
}
persons.add(Student);
}
is.close();
} catch (Exception e) {
e.printStackTrace();
}
return persons;
}
}
类似的测试方法。。。
至此,三种解析方式全部完成了,如果分别测试这三种方法的时候,一路绿条的话,那么恭喜,解析业务逻辑成功。否则,可能还有哪里有问题,请仔细检查。
对比这三种解析方式,我个人认为PULL和SAX解析方式类似,都是事件触发型的,就是当解析到某个节点的时候触发相应的事件。说明一下DOM解析,会把文档中的所有元素,按照其出现的层次关系,解析成一个个Node对象(节点),可见它会有点占内存,但是如果待解析的xml文件相对较小的话,使用DOM解析 优点还是很明确的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号