
8、SparkSQL综合作业
综合练习:学生课程分数
网盘下载sc.txt文件,创建RDD,并转换得到DataFrame。
RDD操作见https://www.cnblogs.com/Kiranar/p/16138625.html
同一操作插入sql/dataframe操作图,sql在下,dataframe在上
dataframe: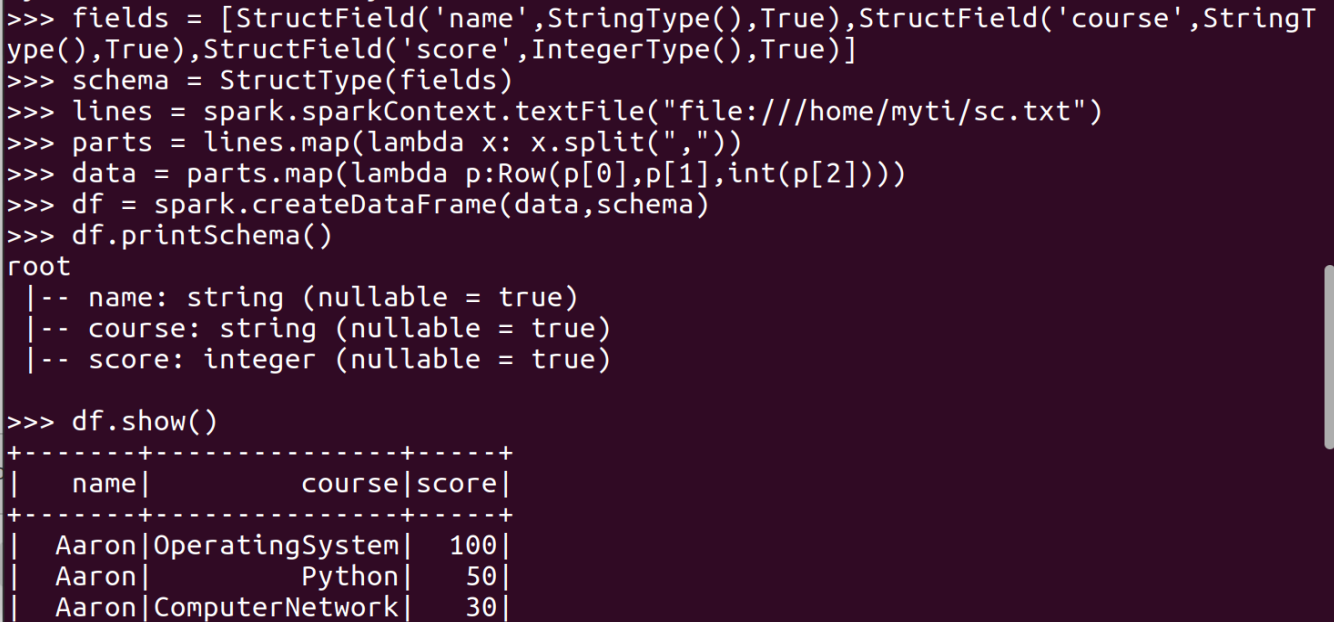
sql:
分别用DataFrame操作和spark.sql执行SQL语句实现以下数据分析:
- 持久化 scm.cache()
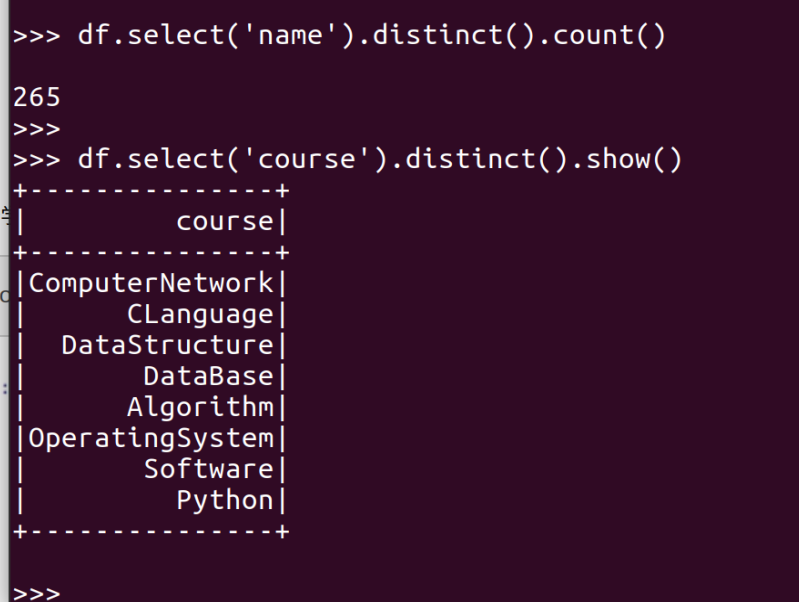
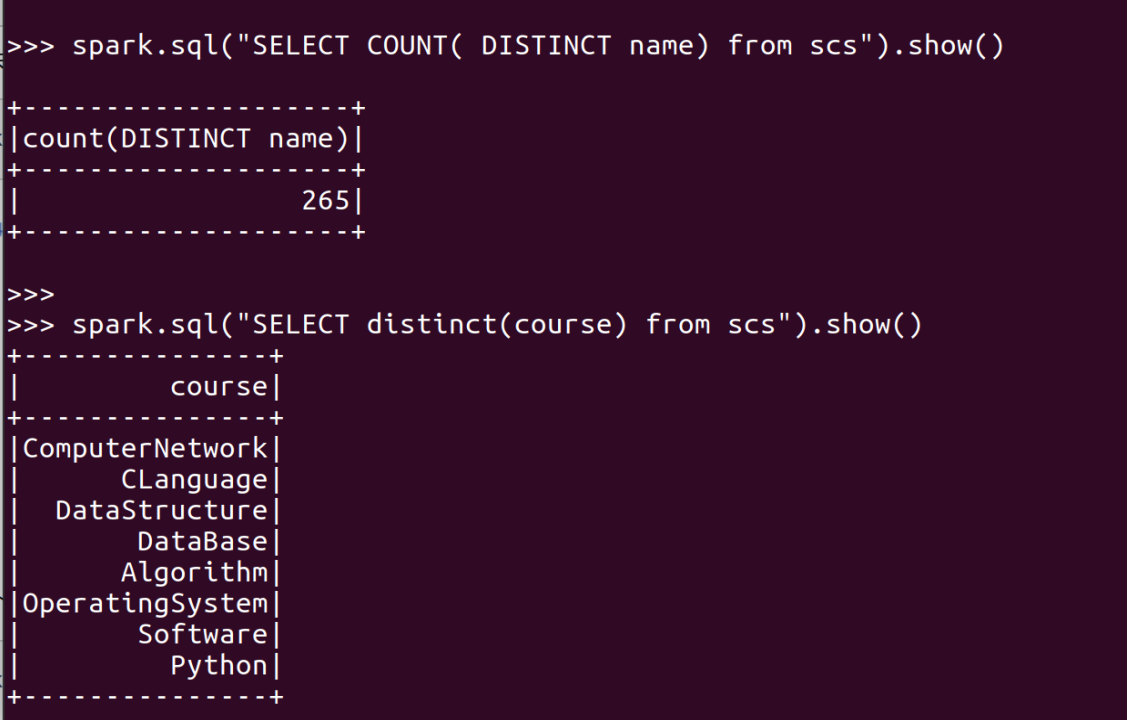
- 总共有多少学生?map(), distinct(), count()
- 开设了多少门课程?
- 生成(姓名,课程分数)键值对RDD,观察keys(),values()
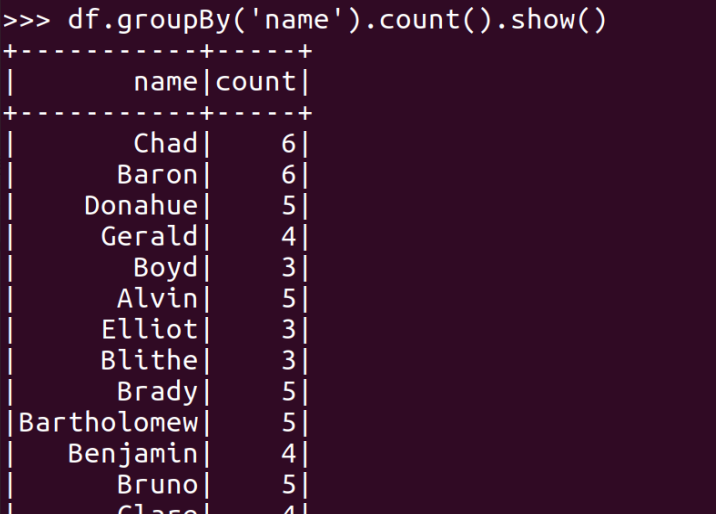
- 每个学生选修了多少门课?map(), countByKey()
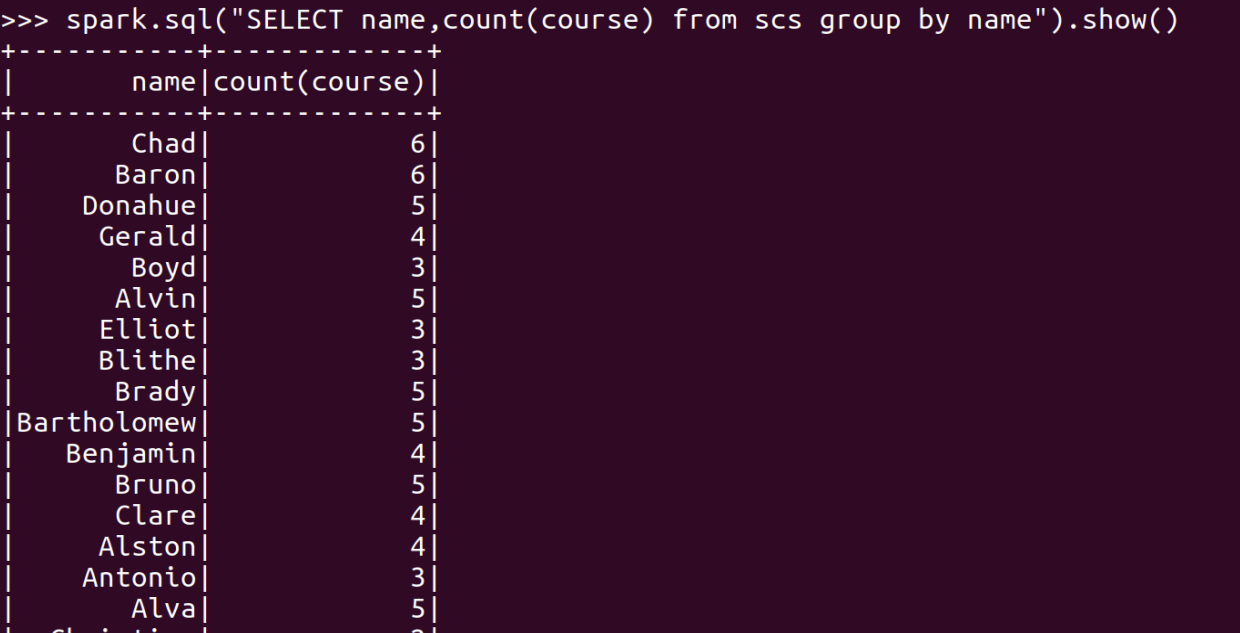
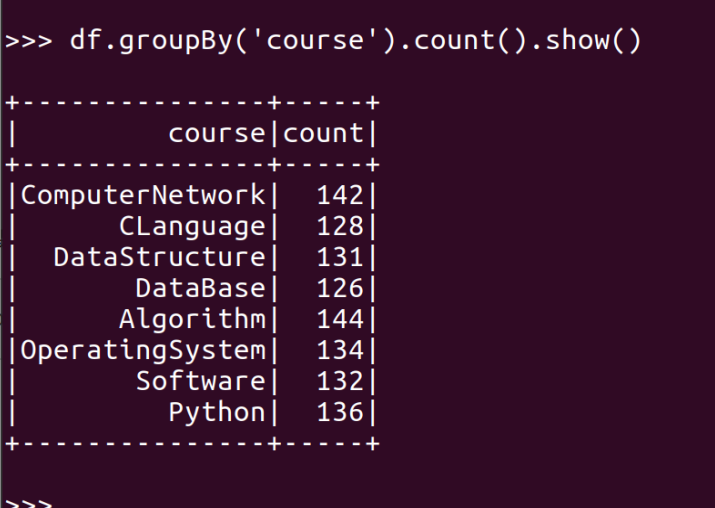
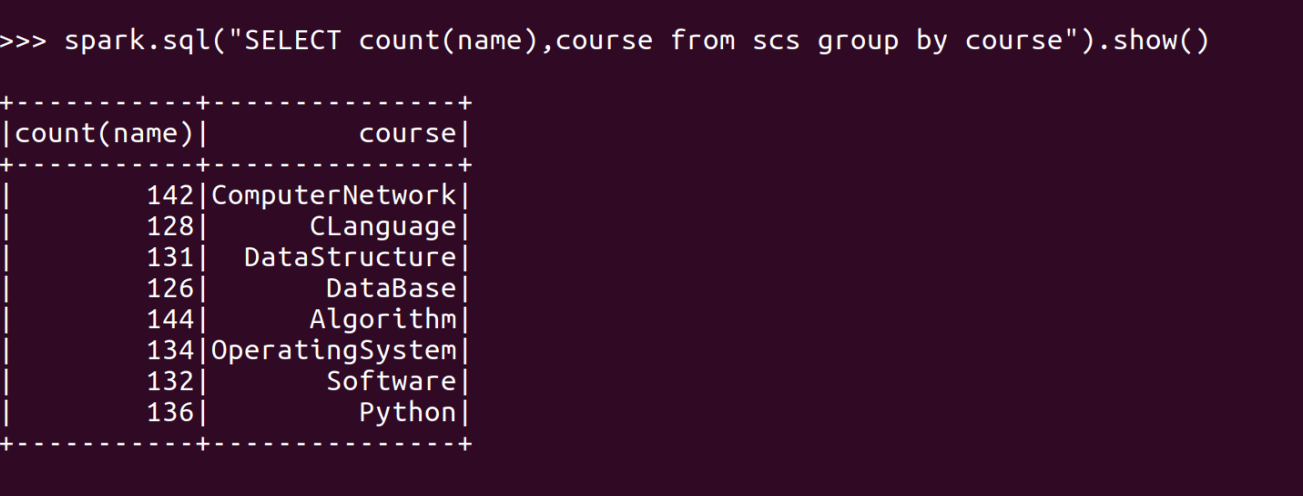
- 每门课程有多少个学生选?map(), countByValue()
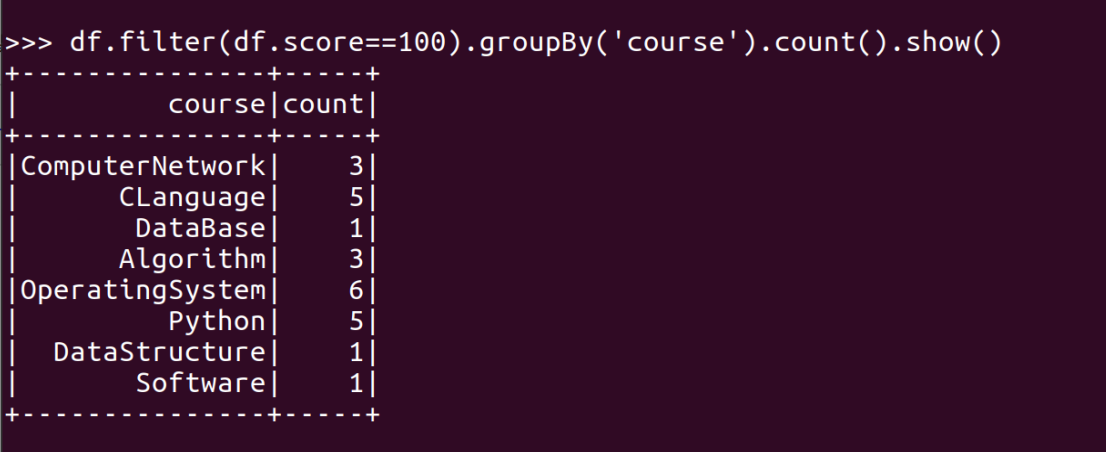
- 有多少个100分?
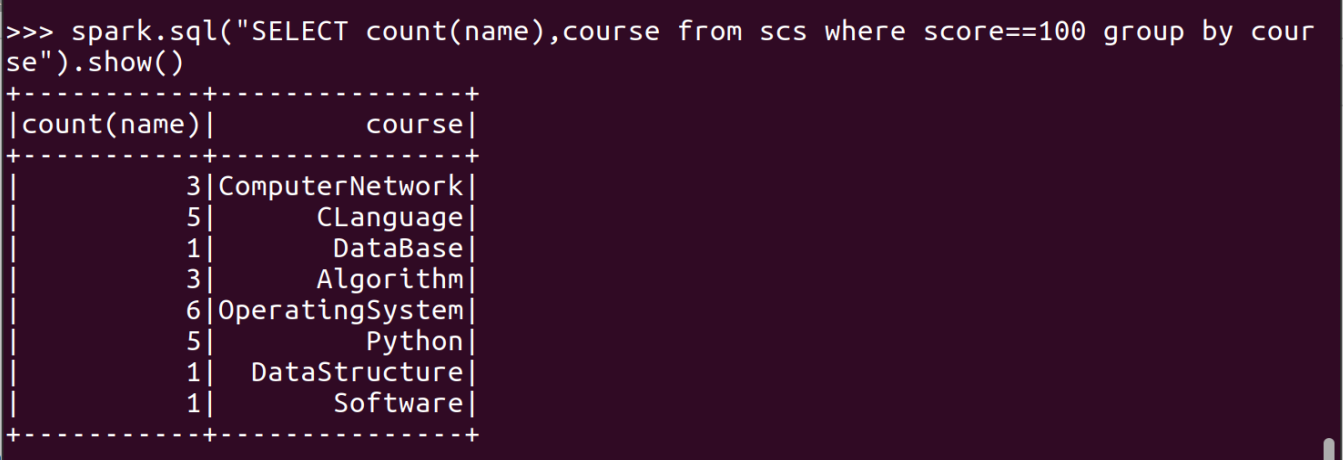
- Tom选修了几门课?每门课多少分?filter(), map() RDD
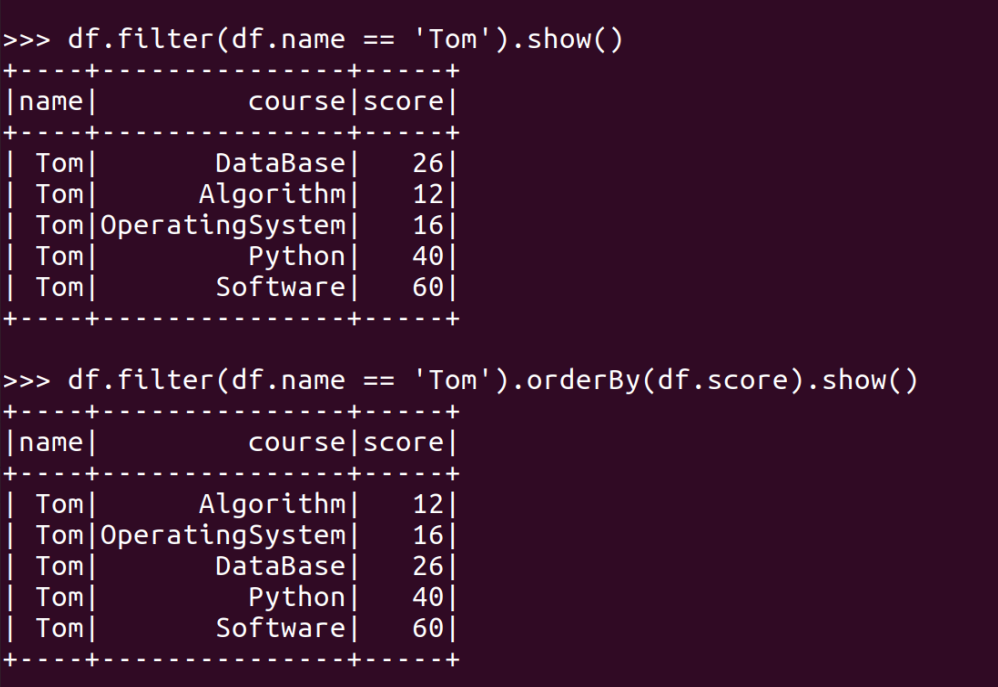
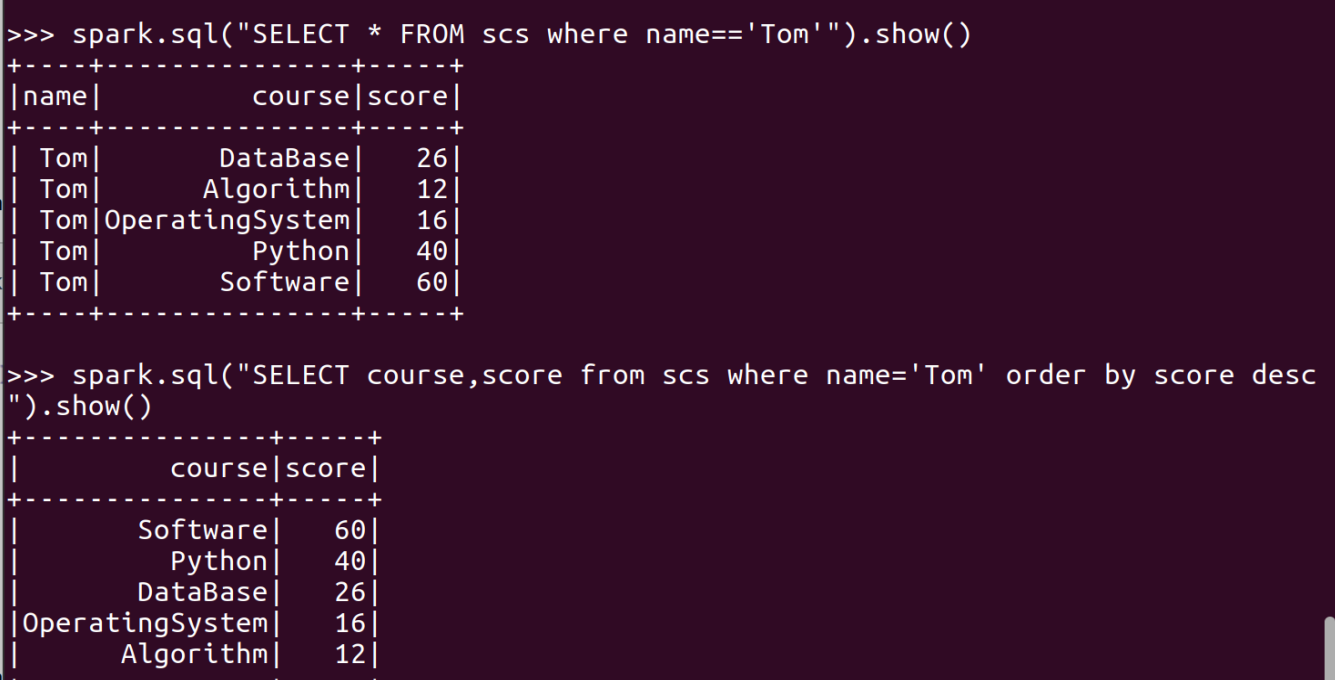
- Tom选修了几门课?每门课多少分?map(),lookup() list
- Tom的成绩按分数大小排序。filter(), map(), sortBy()
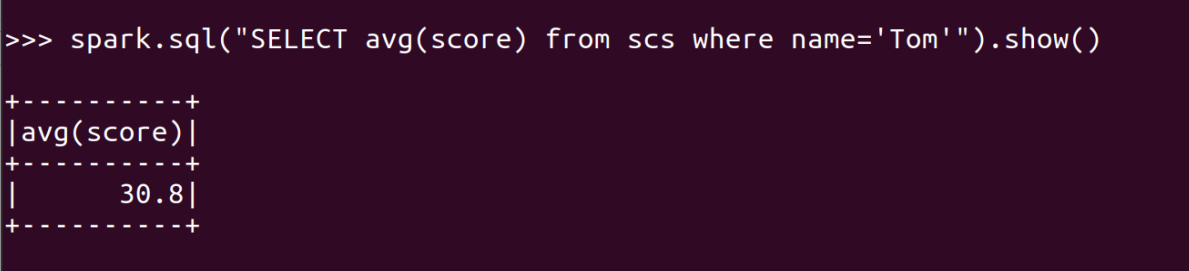
- Tom的平均分。map(),lookup(),mean()

- 生成(姓名课程,分数)RDD,观察keys(),values()
- 每个分数+20平时分。
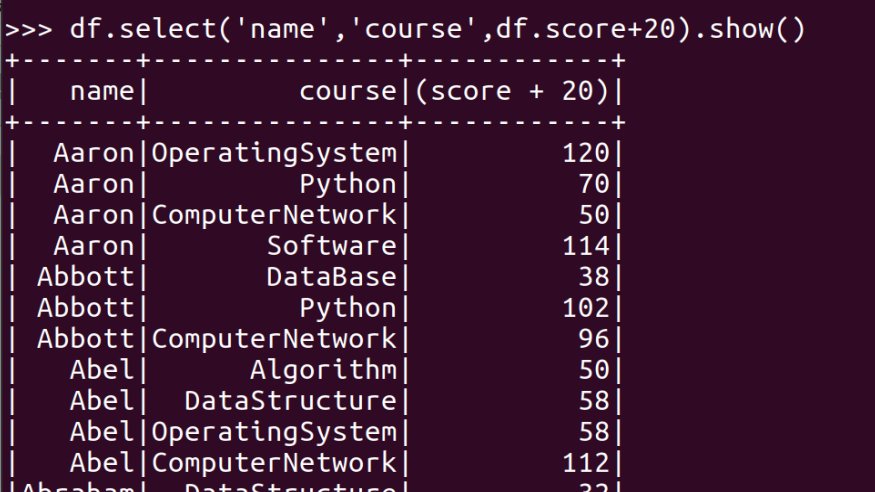
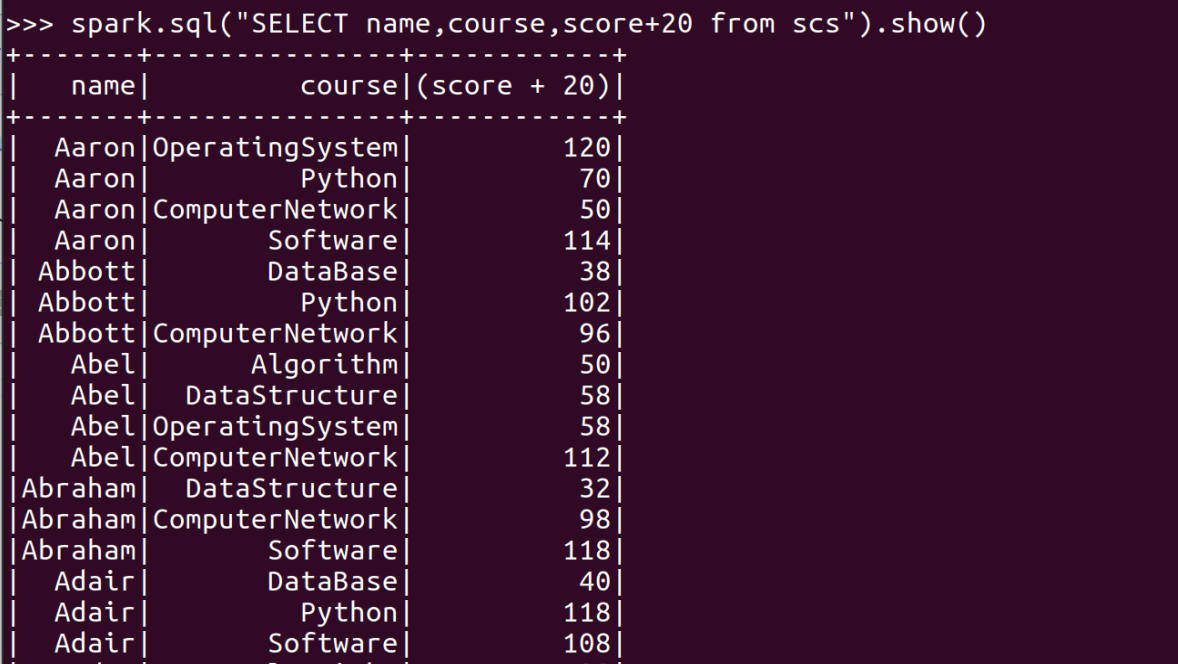
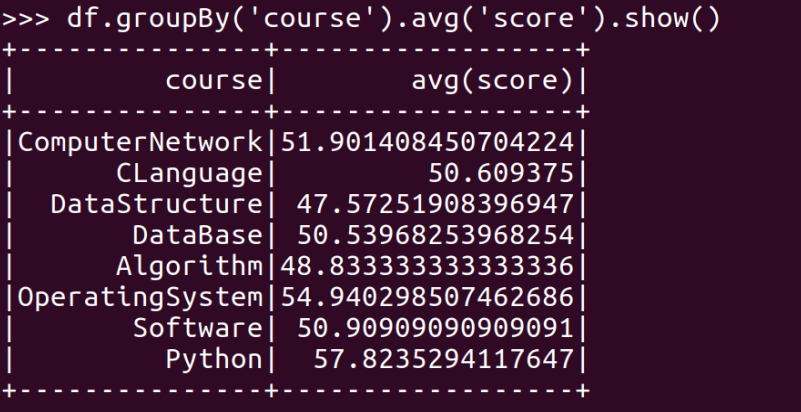
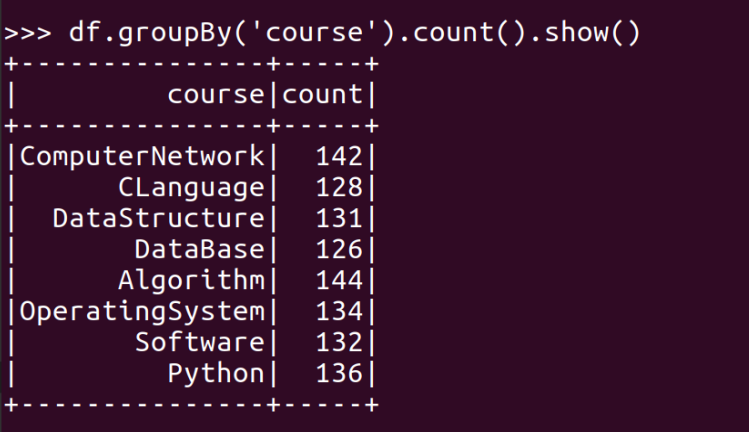
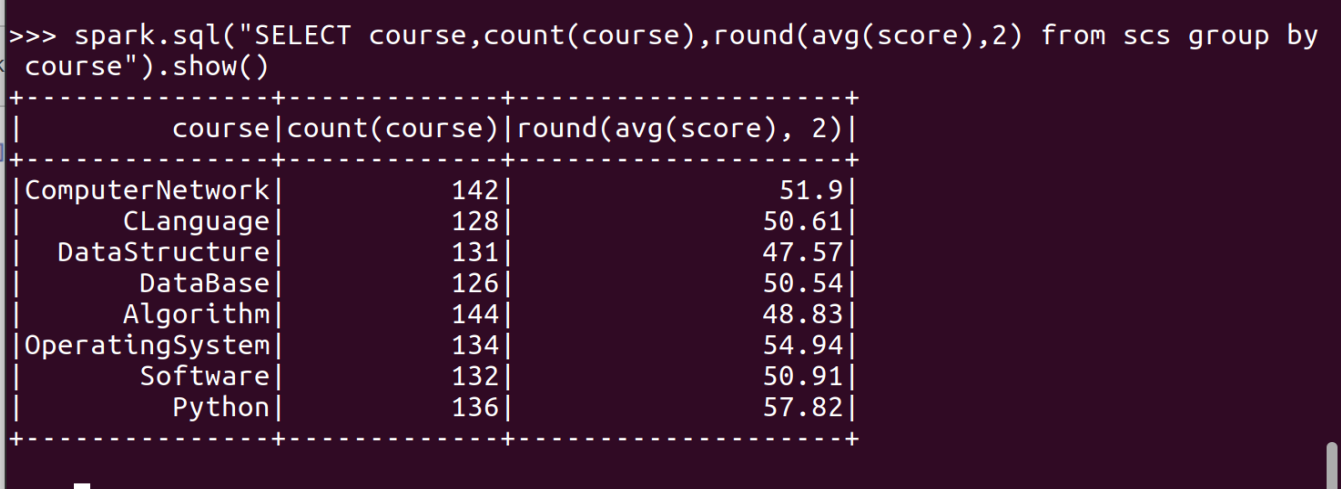
- 求每门课的选修人数及平均分
- lookup(),np.mean()实现
- reduceByKey()和collectAsMap()实现
- combineByKey(),map(),round()实现,确到2位小数
- 比较几种方法的异同。
- datadrame:
-
sql:
综合练习:学生课程分数
网盘下载sc.txt文件,分别创建RDD、DataFrame和临时表/视图;
分别用RDD操作、DataFrame操作和spark.sql执行SQL语句实现以下数据分析:
总共有多少学生?
总共开设了多少门课程?
每个学生选修了多少门课?

每门课程有多少个学生选?

每门课程>95分的学生人数

课程'Python'有多少个100分?

Tom选修了几门课?每门课多少分?


# 创建RDD url = "file:///home/hadoop/sc.txt" rdd = sc.textFile(url).map(lambda x:x.split(",")) scm = rdd.map(lambda a:[a[0],a[1],int(a[2])]) scm.cache() scm.take(3) # 并转换得到DataFrame from pyspark.sql import Row df = spark.createDataFrame(rdd.map(lambda x:Row(name=x[0],course=x[1],grade=int(x[2])))) # 观察 df df.show() df.printSchema() # 注册为临时表 df.createOrReplaceTempView("sc") # 观察临时表 spark.sql("select * from sc").show() # 导包 from pyspark.sql.functions import * # 题目 # 1.总共有多少学生? scm.map(lambda a:a[0]).distinct().count() df.select(df.name).distinct().count() spark.sql("select count(distinct name) from sc").show() # 2.总共开设了哪些课程? scm.map(lambda a:a[1]).distinct().collect() df.select(df.course).distinct().show() spark.sql("select distinct course from sc").show() # 3.每个学生选修了多少门课? name = scm.map(lambda a:(a[0],(a[1],a[2]))) name.countByKey() df.groupBy(df.name).count().show() spark.sql("select name, count(course) from sc group by name").show() # 4.每门课程有多少个学生选? name.values().countByKey() df.groupBy(df.course).count().show() spark.sql("select course, count(name) from sc group by course").show() # 5.每门课程>95分的学生人数 name.values().filter(lambda a:a[1]>95).countByKey() df.filter(df.grade>95).groupBy(df.course).count().show() spark.sql("select course,count(*) from sc where grade>95 group by course").show() # 6.课程'Python'有多少个100分? scm.filter(lambda a:a[1]=='Python').filter(lambda a:a[2]==100).count() df.filter((df.course=='Python') & (df.grade==100)).count() spark.sql("select count(*) from sc where course='Python' and grade=100").show() # 改题目了,这个是旧题目 # 7.Tom选修了几门课?每门课多少分? name.lookup('Tom') len(name.lookup('Tom')) df.select(df.course, df.grade).filter(df.name=='Tom').count() df.select(df.course, df.grade).filter(df.name=='Tom').show() spark.sql("select count(*) from sc where name='Tom'").show() spark.sql("select course, grade from sc where name='Tom'").show() # 7.Tom哪几门课不及格? scm.filter(lambda a:a[0]=='Tom').filter(lambda a:a[2]<60).map(lambda a:a[1]).collect() df.select(df.course).filter((df.name=='Tom')&(df.grade<60)).show() spark.sql("select course from sc where name='Tom' and grade<60").show() # 8.Tom的成绩按分数大小排序。 name.filter(lambda a:a[0]=='Tom').values().sortBy(lambda a:a[1],False).map(lambda a:a[1]).collect() df.select(df.grade).orderBy(df.grade).filter(df.name=='Tom').show() spark.sql("select grade from sc where name='Tom' order by grade asc").show() # 9.Tom选修了哪几门课? scm.filter(lambda a:a[0] == 'Tom').map(lambda a:a[1]).collect() df.filter(df.name == 'Tom').select(df.course).show() spark.sql('select course from sc where name = "Tom"').show() # 10.Tom的平均分。 import numpy as np np.mean(scm.filter(lambda a:a[0]=='Tom').map(lambda a:a[2]).collect()) df.filter(df.name=='Tom').agg({'grade':'mean'}).show() spark.sql("select avg(grade) from sc where name='Tom'").show() # 11.'OperatingSystem'不及格人数 scm.filter(lambda a:a[1] == 'OperatingSystem' and a[2] < 60).count() df.filter(df['course'] == 'OperatingSystem').filter(df['grade'] < 60).count() spark.sql('select count(grade) from sc where course = "OperatingSystem" and grade < 60').show() # 12.'OperatingSystem'平均分 np.mean(scm.filter(lambda a:a[1] == 'OperatingSystem').map(lambda a:(a[1],a[2])).values().collect()) df.filter(df['course'] == 'OperatingSystem').agg({'grade':'avg'}).show() spark.sql('select AVG(grade) from sc where course = "OperatingSystem"').show() # 13.'OperatingSystem'90分以上人数 scm.filter(lambda a:a[1] == 'OperatingSystem' and a[2] > 90).count() df.filter(df['course'] == 'OperatingSystem').filter(df['grade'] > 90).count() spark.sql('select count("OperatingSystem > 90") from sc where course = "OperatingSystem" and grade >90').show() # 14.'OperatingSystem'前3名 scm.filter(lambda a:a[1] == 'OperatingSystem').sortBy(lambda a:a[2],False).map(lambda a:(a[0])).take(3) df.filter(df['course'] == 'OperatingSystem').sort(-df['grade']).select(df.name).limit(3).show() spark.sql('select name from sc where course = "OperatingSystem" order by grade desc limit 3').show() # 15.每个分数按比例+20平时分。 scm.map(lambda a:((a[0],a[1]),a[2])).take(5) scm.map(lambda a:((a[0],a[1]),a[2])).mapValues(lambda v:v*0.8+20).take(5) df.select(df.name, df.course, df.grade).show() df.select(df.name, df.course, df.grade*0.8+20).show() spark.sql("select name, course, grade from sc").show() spark.sql("select name, course, grade*0.8+20 from sc").show() # 16.求每门课的平均分 rdd.map(lambda a:(a[1], (int(a[2]), 1))).reduceByKey(lambda a,b:[a[0]+b[0], a[1]+b[1]]).map(lambda a:[a[0], a[1][0]/a[1][1]]).collect() df.groupBy(df.course).agg({'grade':'avg'}).show() spark.sql('select course, AVG(grade) from sc group by course').show() # 17.选修了7门课的有多少个学生? rdd.map(lambda a:(a[0], 1)).reduceByKey(lambda a,b:a+b).filter(lambda a:a[1]==7).count() # df.groupBy('name').count().filter(col('count') == 7).select(count('name')).show() # spark.sql( "select count('name')\ from (select name, count('name') num from sc where group by name)\ where num = 7" ).show() # 18.每门课大于95分的学生数 # 跟第5题一样 # scm.filter(lambda a:a[2]>95).map(lambda a:[a[0], 1]).reduceByKey(lambda a,b:a+b).join(scm.map(lambda a:[a[0], 1]).reduceByKey(lambda a,b:a+b)).filter(lambda a: a[1][0] == a[1][1]).count() # # # df.filter(df.grade > 95).groupBy(df.name).agg({'name':'count'}).select('name', col('count(name)').alias('c1'))\ # .join(df.groupBy(df.name).agg({'name':'count'}).select('name', col('count(name)').alias('c2')),'name','left')\ # .filter(col('c1') == col('c2')).select(count('name'))\ # .show() # # # spark.sql( # "select name, count(name) c2\ # from sc group by name" # ).createOrReplaceTempView("b") # spark.sql( # "select name, count(name) c1\ # from sc where grade>95 group by name" # ).createOrReplaceTempView("a") # spark.sql( # "select count(a.name)\ # from a join b on a.name = b.name where c1 = c2" # ).show() # 19.每门课的选修人数、平均分、不及格人数、通过率 # rdd # 选修人数 rdd.map(lambda a:(a[1], 1)).reduceByKey(lambda a,b:a+b).collect() # 平均分 rdd.map(lambda a:(a[1], (int(a[2]), 1))).reduceByKey(lambda a,b:[a[0]+b[0], a[1]+b[1]]).map(lambda a:[a[0], a[1][0]/a[1][1]]).collect() # 不及格人数 rdd.map(lambda a:(a[1], a[2])).filter(lambda a:int(a[1]) < 60).map(lambda a:(a[0], 1)).reduceByKey(lambda a,b:a+b).collect() # 通过率 rdd.map(lambda a:(a[1], 1)).reduceByKey(lambda a,b:a+b).join( rdd.map(lambda a:(a[1], a[2])).filter(lambda a:int(a[1]) < 60).map(lambda a:(a[0], 1)).reduceByKey(lambda a,b:a+b) ).map(lambda a:(a[0], 1-(a[1][1]/a[1][0]))).collect() # df df1 = df.groupBy(df.course).agg({'grade':'mean'}).select( 'course', bround('avg(grade)',scale=2).alias('平均分') ).join( df.groupBy(df.course).count()\ .select( 'course', col('count').alias('选修人数') ),"course","left" ).join( df.filter(df.grade<60).groupBy(df.course).count()\ .select( 'course', col('count').alias('不及格人数') ),"course","left" ) df1.select( 'course', '平均分', '选修人数', '不及格人数', 1-df1['不及格人数']/df1['选修人数'] ).select( 'course', '平均分', '选修人数', '不及格人数', col("(1 - (不及格人数 / 选修人数))").alias("通过率") ).show() # sql spark.sql( "select course, count(name) as count, round(avg(grade), 2) as avg\ from sc group by course" ).show() spark.sql( "select course, count(name) as failed\ from sc where grade<60 group by course" ).createOrReplaceTempView("b") spark.sql( "select course, count(name) as count\ from sc group by course" ).createOrReplaceTempView("a") spark.sql( "select a.course, b.failed, 1-b.failed/a.count as pass\ from a join b on a.course = b.course" ).show() # 20.优秀、良好、通过和不合格各有多少人? scm.map(lambda a:a[2]).filter(lambda a:a>=90).count() scm.map(lambda a:a[2]).filter(lambda a:a>=80 and a<90).count() scm.map(lambda a:a[2]).filter(lambda a:a>=60 and a<80).count() scm.map(lambda a:a[2]).filter(lambda a:a<60).count() # df.filter(df.grade>=90).select(count(df.grade)).show() df.filter((df.grade>=80) & (df.grade<90)).select(count(df.grade)).show() df.filter((df.grade>=60) & (df.grade<80)).select(count(df.grade)).show() df.filter(df.grade<60).select(count(df.grade)).show() # spark.sql("select count(name) from sc where grade>=90").show() spark.sql("select count(name) from sc where grade>=80 and grade<90").show() spark.sql("select count(name) from sc where grade>=60 and grade<80").show() spark.sql("select count(name) from sc where grade<60").show() # 21.同时选修了 DataStructure 和 DataBase 的学生 scm.map(lambda a:[a[0], a[1]]).groupByKey().map(lambda x:(x[0], list(x[1]))).filter(lambda a:'DataStructure' in a[1] and 'DataBase' in a[1]).count() # df.select(col('name'), col('course').alias('ac')).join( df.select(col('name'), col('course').alias('bc')),"name","inner" ).filter(col('ac')=='DataBase').filter(col('bc')=='DataStructure')\ .select(col('name')).distinct().select(count(col('name'))).show() # spark.sql( "select count(distinct a.name)\ from sc a join (select name, course from sc) b on a.name = b.name\ where a.course = 'DataStructure' and b.course = 'DataBase'" ).show() # 22.选修了 DataStructure 但没有选修 DataBase 的学生 scm.map(lambda a:[a[0], a[1]]).groupByKey().map(lambda x:(x[0], list(x[1]))).filter(lambda a:'DataStructure' in a[1] and 'DataBase' not in a[1]).count() # df2=df.filter(col('course') == 'DataBase').select(col('name').alias('b')) df1=df.filter(col('course') == 'DataStructure').select(col('name').alias('a')) df1.join(df2,[df1.a==df2.b],'left').filter(col('b').isNull()).select(count(col('a'))).show() # spark.sql( "select distinct name\ from sc where course = 'DataStructure'" ).createOrReplaceTempView("a") spark.sql( "select distinct name\ from sc where course = 'DataBase'" ).createOrReplaceTempView("b") spark.sql( "select count(a.name)\ from a left join b on a.name = b.name\ where b.name is null" ).show() # 23.选修课程数少于3门的同学 rdd.map(lambda a:(a[0], 1)).reduceByKey(lambda a,b:a+b).filter(lambda a:a[1]<3).map(lambda a:a[0]).collect() df.groupBy('name').count().filter(col('count') < 3).select(col('name')).show() # spark.sql( "select name\ from (select name, count('name') num from sc where group by name)\ where num < 3" ).show() # 24.选修6门及以上课程数的同学 rdd.map(lambda a:(a[0], 1)).reduceByKey(lambda a,b:a+b).filter(lambda a:a[1]>=6).map(lambda a:a[0]).collect() df.groupBy('name').count().filter(col('count') > 6).select(col('name')).show() # spark.sql( "select name\ from (select name, count('name') num from sc where group by name)\ where num > 6" ).show() # 25.查询平均成绩大于等于60分的姓名和平均成绩 rdd.map(lambda a:(a[0], (int(a[2]), 1))).reduceByKey(lambda a,b:[a[0]+b[0], a[1]+b[1]]).map(lambda a:[a[0], a[1][0]/a[1][1]]).filter(lambda a:a[1]>=60).collect() # df.groupBy(df.name).agg({'grade':'mean'}).select( 'name', bround('avg(grade)',scale=2).alias('平均分') ).filter(col('平均分')>=60).show() # spark.sql( "select name, round(avg(grade), 2) as avg\ from sc group by name having avg >= 60" ).show() # 26.找出平均分最高的10位同学 rdd.map(lambda a:(a[0], (int(a[2]), 1))).reduceByKey(lambda a,b:[a[0]+b[0], a[1]+b[1]]).map(lambda a:[a[0], a[1][0]/a[1][1]]).sortBy(lambda a:a[1],False).take(10) # df.groupBy(df.name).agg({'grade':'mean'}).select( 'name', bround('avg(grade)',scale=2).alias('平均分') ).sort(-col('平均分')).limit(10).show() # spark.sql( "select name, round(avg(grade), 2) as avg\ from sc group by name\ order by avg desc limit 10" ).show()

