记一次生产GC频繁处理
发现问题
公司飞书收到了告警通知,CPU超高了
登录该服务器,执行top -H -p pid 和一系列操作(详见:CPU超高问题排查_zab635590867的博客-CSDN博客 )后,发现是GC线程,于是查看了该线程的gc情况,发现FGC频繁,如下图。
jstat -gc 20011 1000 10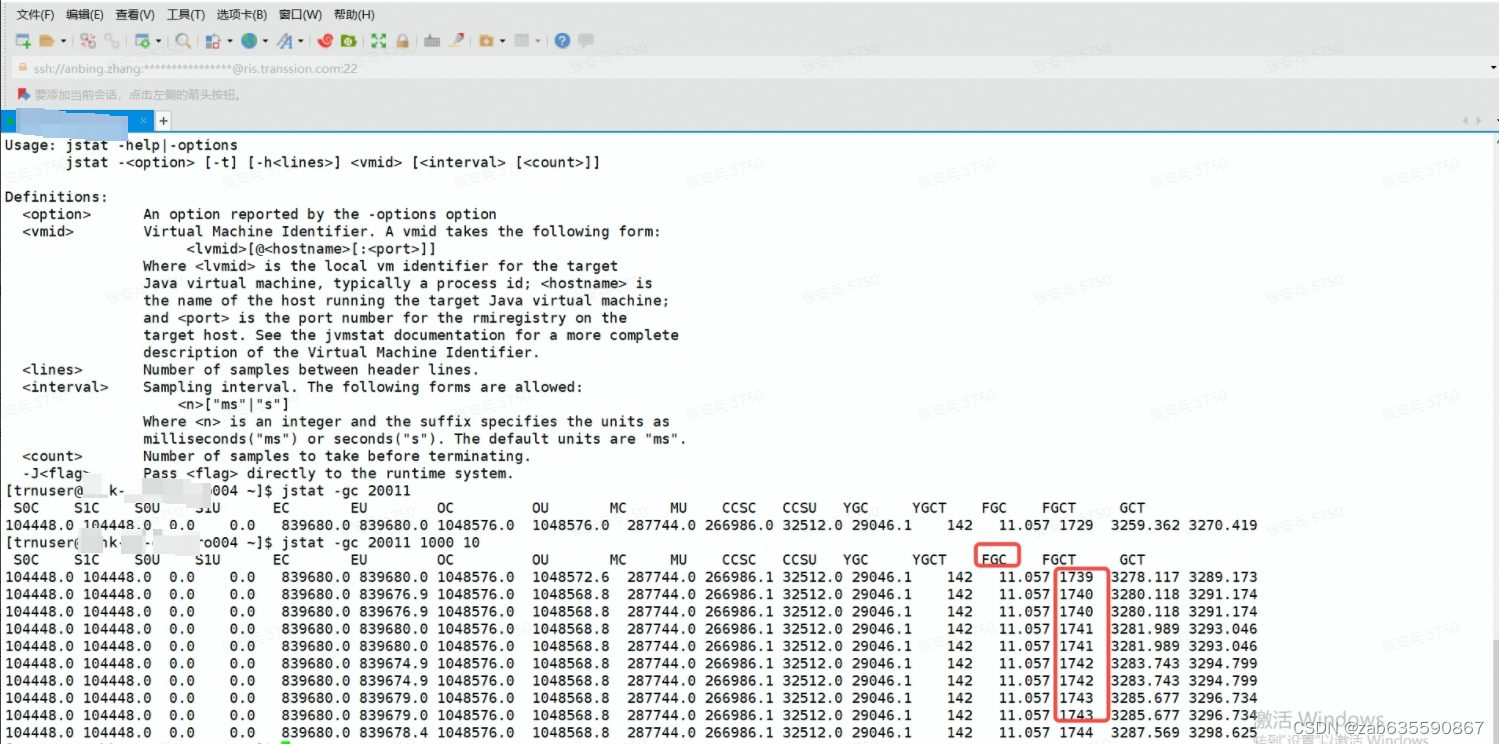
上述排查命令表示:查看线程id为20011的线程的GC情况,每1000ms打印一次记录,打印10次。
可以看到FullGC次数每一两秒就在增加,这是很典型的FullGC频繁。
dump内存文件
通常情况下,不允许直接采用jmap下载dump文件,可能会占用大量资源。但是考虑到我们服务是分布式部署的,而且GC只是频繁,如果没有发送OOM,也不会自动打印dump文件,为了不错过这次机会,还是在线上冒险执行了
jmap –dump:live,format=b,file=xx.hprof 20011dump下来的hprof文件,总共2.43G
工具准备
分析采用MemoryAnalyzer,简称MAT,安装该工具需要注意两个事项:
第一,MAT新版需要安装JDK11才能使用;
第二,堆文件大小超过了MAT默认的设置,需要调整配置文件,才能打开
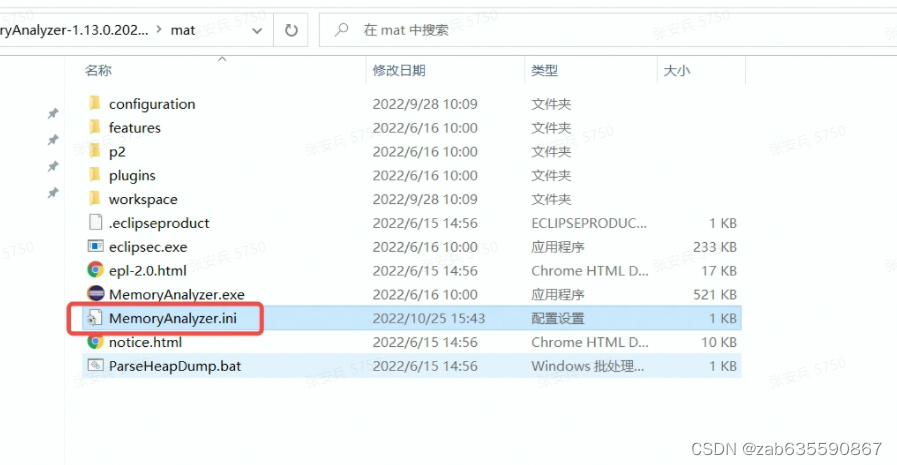
因为内存文件大小为2.43G,所以调整配置如下:
-vm
C:\Program Files\Java\jdk-11.0.16.1\bin\javaw.exe
-startup
plugins/org.eclipse.equinox.launcher_1.6.400.v20210924-0641.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_64_1.2.400.v20211117-0650
-vmargs
-Xmx3072m分析
MAT工具使用,网上有很多介绍资料了,博主这里只是介绍自己的分析。
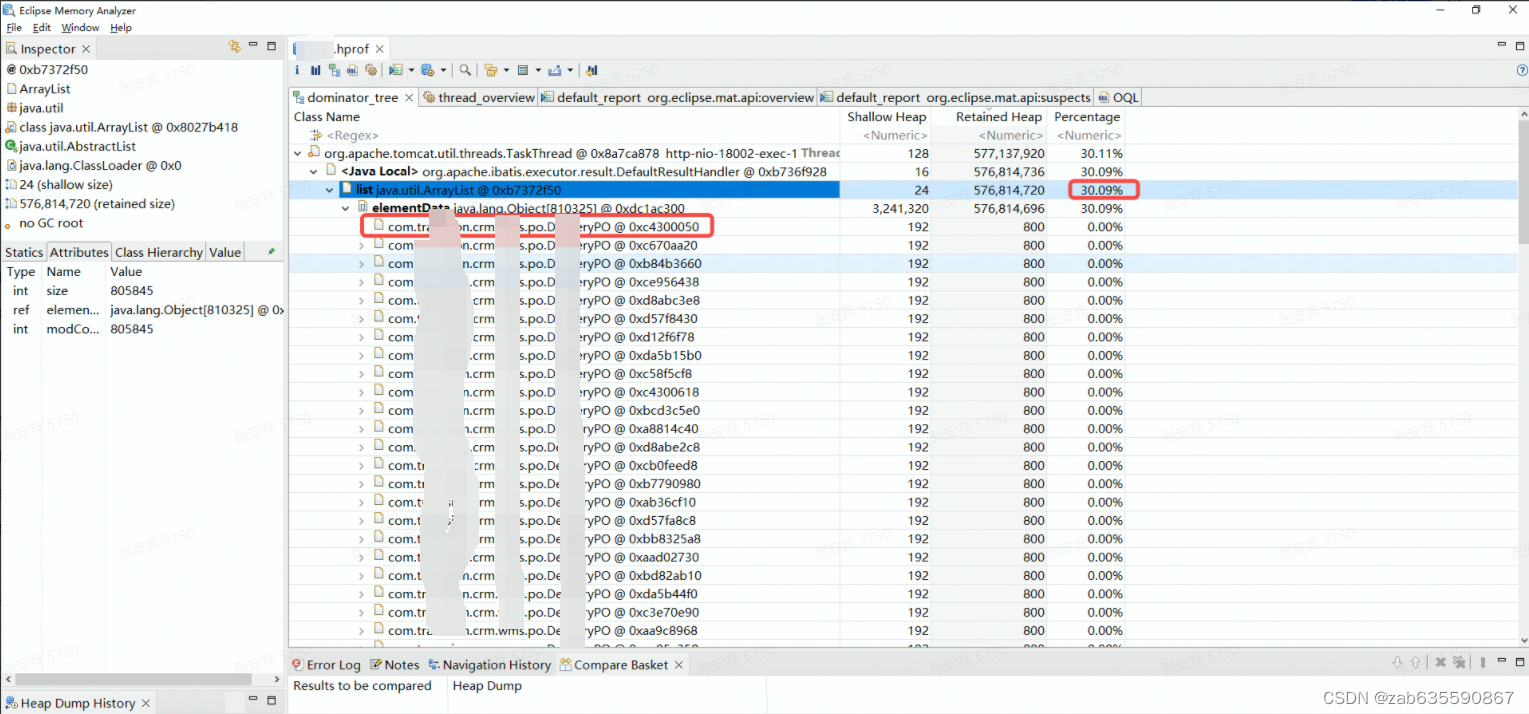
打开dominator_tree后,发现2.4G的文件30%都是这个PO类,总共80w+。这是一个非常可疑的点。但是由于没有线程分析那样指向了某行代码,所以,只能带着这个类去代码中查找可能查询到该类集合的地方。
经过全局搜索:List<xxPO>
找到如下问题
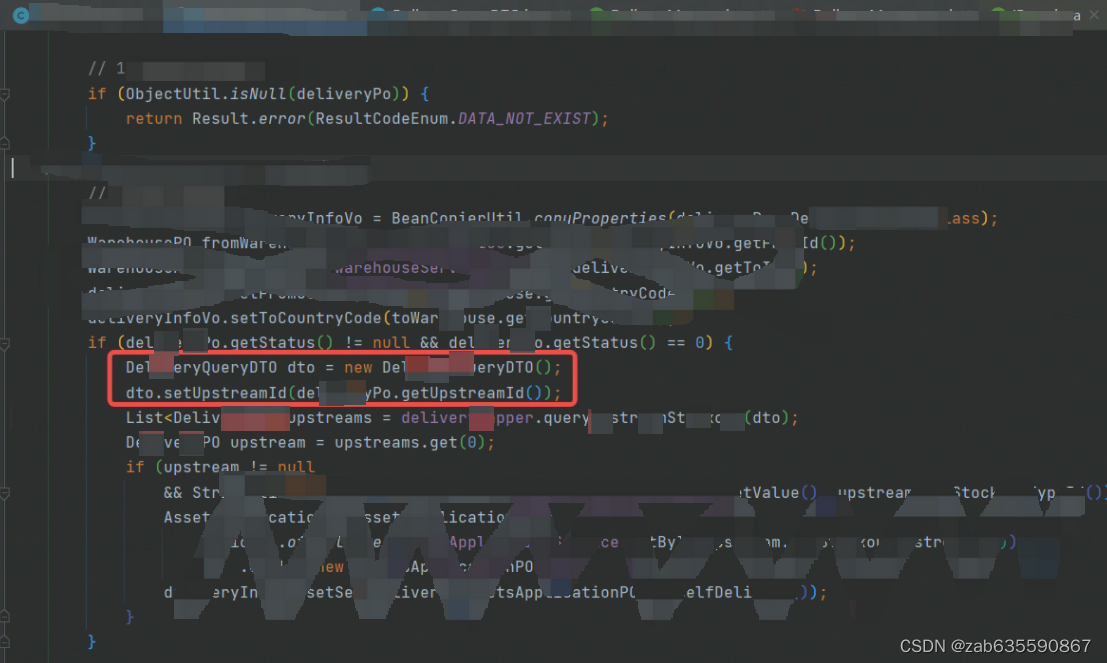
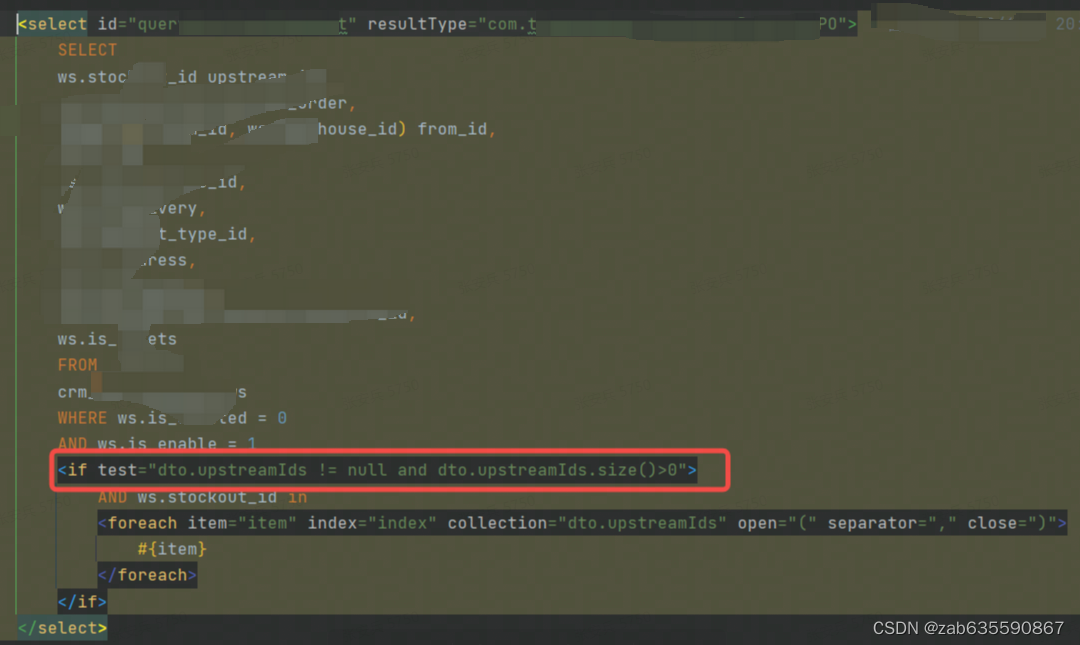
简单来说,就是查询sql的条件因为疏忽,写错了,代码传的upStreamId,sql写的upStreamIds,当然两个字段都有,然后导致sql中的if条件不满足,where就只有两个状态值限制,约等于一个全表查询。这也解释了为什么会有80W的PO类。
总结
1、GC频繁的原因有很多,但是总归来说,都是内存区域的大小容不下新增的内存需求。本次属于全表操作,大规模的数据涌入,让GC线程不停工作,进而FullGC频繁导致了CPU超高。
2、思考:全表查询已经不是第一次被发现造成了线上问题了,所以开发中一定要注意sql中的where条件,避免存在传参为空,导致全表查询的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号