Prometheus自定义监控告警项-3
prometheus 编写告警规则
将自定义的告警规则写到独立的文件中,prometheus.yml中引用如下:
rule_files:
- "rules/*.yml"
[root@localhost prome]# mkdir /usr/local/prome/rules
编辑一个新的名为node-server.yml文件
vim node-server.yml
groups: # 告警分组
- name: Node-server.rules # 组名称
rules: #告警规则
- alert: System Memory Used # 告警主题名称
expr: 100-(node_memory_MemAvailable_bytes{job="node-server"}/node_memory_MemTotal_bytes{job="node-server"}*100) > 60 # 告警阈值
for: 1m # 阈值持久时间
labels: # 标签,定义告警级别
severity: warning
annotations: # 告警描述信息
summary: "Instance {{ $labels.instance }} : {{ $labels.job }} 内存使用率过高 "
description: "{{ $labels.instance }} : {{ $labels.job }} 内存使用率超过60%.当前值: {{ $value }}" # {{ $value }} 调用的是上面的promeSQL的值
- 告警规则编写完后,检查一下配置
# 可以看到检测到几个报警规则文件和每个规则文件中定义了几个告警规则
[root@localhost prome]# ./promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 2 rule files found
Checking rules/node-server.yml
SUCCESS: 1 rules found
Checking rules/rules.yml
SUCCESS: 1 rules found
- 配置无误后重载 prometheus 服务
一分钟后收到邮件
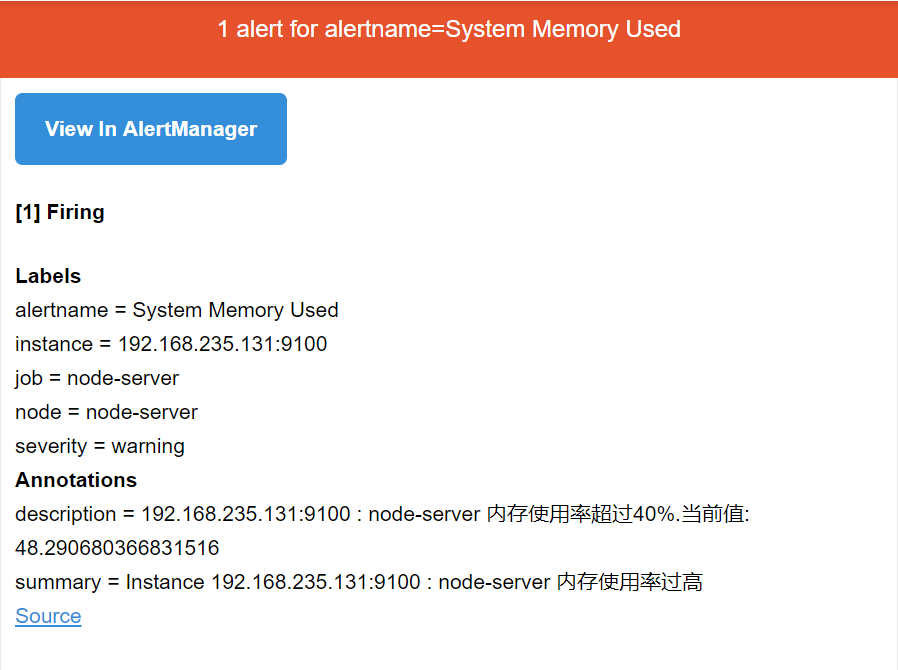
同样,一个资源组的其他监控项写在同一个规则文件中的rules下定义多个告警项即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号