用python做时间序列预测七:时间序列复杂度量化
本文介绍一种方法,帮助我们了解一个时间序列是否可以预测,或者说了解可预测能力有多强。
Sample Entropy (样本熵)
Sample Entropy是Approximate Entropy(近似熵)的改进,用于评价波形前后部分之间的混乱程度,
熵越大,乱七八糟的波动越多,越不适合预测;熵越小,乱七八糟的波动越小,预测能力越强。
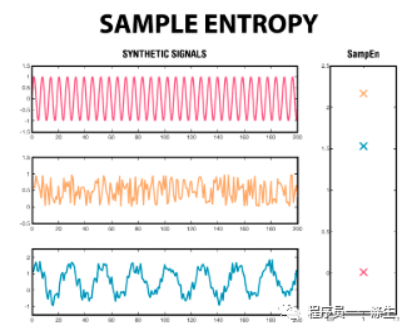
具体思想和实现如下:
- 思想
Sample Entropy最终得到一个 -np.log(A/B) ,该值越小预测难度越小,所以A/B越大,预测难度越小。
A:从0位置开始,取m+1个元素构成一个向量,然后移动一步,再取m+1个元素构成一个向量,如此继续直到最后得到一个向量集合Xa,看有多少向量彼此的距离小于容忍度r(即有多少向量彼此相似,又称自相似个数)。
B:从0位置开始,取m个元素构成一个模板向量,然后移动一步,再取m个元素构成一个模板向量,如此继续直到最后得到一个向量集合Xb,看有多少向量彼此的距离小于容忍度r(即有多少向量彼此相似,又称自相似个数)。
而实际上A总是小于等于B的,所以A/B越接近1,预测难度越小,直觉上理解,应该就是波形前后部分之间的变化不大,那么整个时间序列的波动相对来说会比较纯(这也是熵的含义,熵越小,信息越纯,熵越大,信息越混乱),或者说会具有一定的规律,而如果A和B相差很大,则时间序列波动不纯,或者说几乎没有规律可言。
比如:U = [0.2, 0.6, 0.7, 1.2, 55, 66],m=2,
那么可以计算得到:
Xa = [[0.2, 0.6, 0.7], [0.6, 0.7, 1.2], [0.7, 1.2, 55.0], [1.2, 55.0, 66.0]]
Xb = [[0.2, 0.6], [0.6, 0.7], [0.7, 1.2], [1.2, 55.0], [55.0, 66.0]]
假设Xa中相似向量的个数比Xb多,那么应该出现Xa满足r,但是Xb不满足r的情况,但是拿Xa和Xb的前两个向量来分析,如果Xa满足r,则0.2-0.6 ,0.6-0.7,0.7-1.2中的最大值应该<=r,也就是说0.2-0.6 ,0.6-0.7肯定<=r,如此推断,Xb肯定也满足r, 所以只有可能出现Xb满足r,Xa不满足r的情况。- python实现
def SampEn(U, m, r):
"""
用于量化时间序列的可预测性
:param U: 时间序列
:param m: 模板向量维数
:param r: 距离容忍度,一般取0.1~0.25倍的时间序列标准差,也可以理解为相似度的度量阈值
:return: 返回一个-np.log(A/B),该值越小预测难度越小
"""
def _maxdist(x_i, x_j):
"""
Chebyshev distance
:param x_i:
:param x_j:
:return:
"""
return max([abs(ua - va) for ua, va in zip(x_i, x_j)])
def _phi(m):
x = [[U[j] for j in range(i, i + m - 1 + 1)] for i in range(N - m + 1)]
C = [len([1 for j in range(len(x)) if i != j and _maxdist(x[i], x[j]) <= r]) for i in range(len(x))]
return sum(C)
N = len(U)
return -np.log(_phi(m + 1) / _phi(m))
if __name__ == '__main__':
_U = [0.2, 0.6, 0.7, 1.2, 55, 66]
rand_small = np.random.randint(0, 100, size=120)
rand_big = np.random.randint(0, 100, size=136)
m = 2
print(SampEn(_U, m, r=0.2 * np.std(_U)))
print(SampEn(rand_small, m, r=0.2 * np.std(rand_small)))
print(SampEn(rand_big, m, r=0.2 * np.std(rand_big)))
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
本文来自博客园,作者:AI粉嫩特攻队,转载请注明原文链接:https://www.cnblogs.com/anai/p/13083043.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号