Django基础五之Django模型层(二)多表操作
Django基础五之Django模型层(二)多表操作
一 创建模型
表和表之间的关系
一对一、多对一、多对多
# 作者表 比较常用的信息放在这个表中
class Author(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
authorDetail=models.OneToOneField(to='AuthorDetail')
#与AuthorDetail建立一对一的关系,一对一的这个关系字段写在这两个表的任意一个表里面都可以,models.OneToOneField(to='AuthorDetail')就是foreignkey+unique,只不过不需要我们自己来写参数了,并且orm会自动帮你给这个字段名字拼上一个_id,数据库中字段名称为authorDetail_id也可以写成这样# authorDetail = models.OneToOneField(to="AuthorDetail", to_field="id",on_delete=models.CASCADE) on_delete=models.CASCADE级联关系
def __str__(self):
return self.name
# 作者信息表 不常用的作者信息放这个表中
class AuthorDetail(models.Model):
brithday=models.DateField()
telephone=models.BigIntegerField()
addr=models.CharField(max_length=64)
def __str__(self):
return self.addr
# 书籍出版社表
class Publish(models.Model):
name=models.CharField(max_length=32)
city=models.CharField(max_length=32)
email=models.EmailField()
def __str__(self):
return self.name
# 书籍表
class Book(models.Model):
title=models.CharField(max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_palces=2)
# 与Publish建立一对多的关系,外键字段建立在多的一方,字段publish如果是外键字段,那么它自动是int类型
# foreignkey里面可以加很多的参数,都是需要咱们学习的,慢慢来,to指向表,to_field指向你关联的字段,不写这个,默认会自动关联主键字段,on_delete级联删除字段名称不需要写成publish_id,orm在翻译foreignkey的时候会自动给你这个字段拼上一个_id,这个字段名称在数据库里面就自动变成了publish_id
publish=models.Foreignkey(to='publish')
# 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表,并且注意一点,你查看book表的时候,你看不到这个字段,因为这个字段就是创建第三张表的意思,不是创建字段的意思,所以只能说这个book类里面有authors这个字段属性
authors=models.ManyToManyField(to='Author')
def __str__(self):
return self.title
# 多对多的表关系,我们学mysql的时候是怎么建立的,是不是手动创建一个第三张表,然后写上两个字段,每个字段外键关联到另外两张多对多关系的表,orm的manytomany自动帮我们创建第三张表,两种方式建立关系都可以,以后的学习我们暂时用orm自动创建的第三张表,因为手动创建的第三张表我们进行orm操作的时候,很多关于多对多关系的表之间的orm语句方法无法使用
# 如果你想删除某张表,你只需要将这个表注销掉,然后执行那两个数据库同步指令就可以了,自动就删除了。
#注意不管是一对多还是多对多,写to这个参数的时候,最后后面的值是个字符串,不然你就需要将你要关联的那个表放到这个表的上面
多表间的增删改查
添加表记录---增
操作前先简单的录入一些数据:还是create和save两个方法,和单表的区别就是看看怎么添加关联字段的数据
一对一
方式一:
new_author_detail=models.AuthorDetail.objects.create(
birthday='1965-10-10',
telephone='18335267641',
addr='山西大同'
)
models.Author.objects.create(
name='ll',
age='53',
authorDetail=new_author_detail,
)
方式二 常用
obj=models.AuthorDetail.objects.filter(addr='山西大同').last()
print(obj.id)
models.Author.objects.create(
name='mx',
age='52',
authorDetail_id=obj.id
)
一对多
obj=models.Publish.objects.get(id=3)
models.Book.objects.create(
title='故事会新编',
publishDate='2019-9-10',
price=30,
# 方式一
publish=obj
# 方式二 常用
publish_id=obj.id
)
多对多
方式一 常用
book_obj=models.Book.objects.get(id=1)
book_obj.authors.add(*[1,2]) #打散
方式二
author1=models.Author.objects.get(id=3)
author2=models.Author.objects.get(id=4)
book_obj=models.Book.objects.get(id=4)
book_obj.authors.add(*[author1,author2])
删除表记录---删
一对一
models.AuthorDetail.objects.get(id=6).delete()
models.Author.objects.get(id=5).delete()
一对多
models.Publish.objects.get(id=1).delete()
models.Book.objects.get(id=1).delete()
多对多
book_obj = models.Book.objects.get(id=1)
book_obj.authors.remove(*[1, 2]) #删除
book_obj.authors.clear() #清空
book_obj.authors.add(2,) #添加
book_obj.authors.set(['1','2']) #删除然后更新
更新表记录---改
一对一
models.Author.objects.filter(id=1).update(
name='安文',
age=24,
方式一
# authorDetail_id=5,
方式二
authorDetail=models.AuthorDetail.objects.get(id=3)
)
一对多
models.Book.objects.filter(id=4).update(
title='java核心',
方式一
publish_id=4,
方式二
publish=models.Publish.objects.get(id=2)
)
多对多
book_obj.authors.set(['1','2']) #删除然后更新
查询表记录---查
基于对象的跨表查询 -- 类似于子查询
正向查询和反向查询
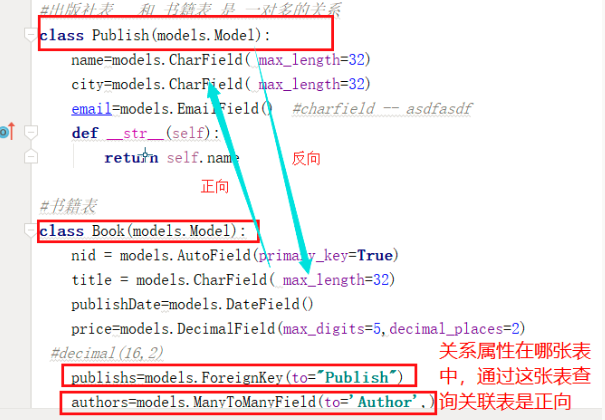
| 关系属性(字段)写在那个表中,从当前表(类)的数据去查询它关联表(类)中的数据叫正向查询,反之叫反向查询 |
#一对一
正向查询
# 查询yage的电话
author_obj=models.Author.objects.filter(name='yage').first()
print(author_obj.authorDetail)
print(author_obj.authorDetail.telepbone)
反向查询
# 查询这个电话 145523669874 是谁的
author_detail_obj=models.AuthorDertail.objects.get(telrphone=145523669872)
print(author_detail_obj.author)
print(author_detail_obj.author.name)
"""
正向查询Author_obj.authorDateil,对象.关联属性
Author------------------------->AuthorDateil
Author<-------------------------AuthorDateil
反向查询:AuthorDateil.author,对象.小写类名
"""
#一对多
正向查询
# 查询某本书 java核心 的 出版社是哪个
book_obj=models.Book.objects.get(title='java核心')
print(book_obj.publish)
print(book_obj.publish.name)
反向查询
#清华出版社出版的那些书
pub_pbj=models.Publish.objects.get(name='清华出版社')
print(pub_obj.book_set.all())
"""
正向查询 book_obj.publishs 对象.属性
Book------------------------------>>>Publish
Book<<<------------------------------Publish
反向查询 pub_obj.book_set.all() 对象.表名小写_set
"""
#多对多
正向查询
# 查询某本书 java核心 是谁出版的
book_obj=models.Book.objects.get(title='java核心')
print(book_obj.authors.all())
反向查询
#查询 yage 写了哪些书
author_obj=models.Author.object.get(name='yage')
print(author_obj.book_set.all())
"""
正向查询 book_obj.authors.all() 对象.属性
book --------------->author
book <---------------author
反向查询 author_obj.book_set.all() 对象.表名小写_set
"""
基于双下划线的跨表查询--连表查询 join
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
'''
基于双下划线的查询就一句话:正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表,一对一、一对多、多对多都是一个写法,注意,我们写orm查询的时候,哪个表在前哪个表在后都没问题,因为走的是join连表操作。
'''
# 一对一
#1. 查询yage的电话
# 方式一 正向查询
obj=models.Author.object.filter(name='yage').values('authorDetail__telepbone')
print(obj)
# 方式二 反向查询
obj=models.AuthorDetail.objects.filter(author__name='yage').values('telephone')
print(obj)
#2. 谁的电话是 145523669874
obj=models.AuthorDetail.object.filter(telephon='145523669874').values('authors__name')
print(obj)
obj=models.Author.objects.filter(authorDetail__telephon='145523669874').values('name')
print(obj)
# 一对多
# 查询某本书 java核心 的 出版社是哪个
obj=models.Book.objects.filter(name='java核心').values('publish__name')
obj=models.Publish.objects.filter(book__title='java核心').values('name')
# 清华出版社出版的那些书
obj=models.Publish.objects.filter(name='清华出版社').values('book__title')
print(obj)
obj=models.Book.object.filter(publish__name='清华出版社').values('title')
print(obj)
# 多对多
# 查询某本书 java核心 是谁出版的
obj=models.Book.objects.filter(title='java核心').values('authors__name')
print(obj)
obj=models.Author.objects.filter(book__title='java核心').values('name')
print(obj)
# 查询 yage 写了哪些书
#方法一
obj=models.Author.objects.filter(name='yage').values('book__title')
print(obj)
#方法二
obj=models.Book.objects.filter(authors__name='yage').values('title')
print(obj)
#进阶查询一
#清华出版社 出版的书 以及作者姓名
#方法一
obj=models.Publish.objects.filter(name='清华出版社').values('book__title','book__authors__name')
print(obj)
#方法二
obj=models.Book.objects.filter(publish__name='清华出版社').values('title','authors__name')
print(obj)
#方法三
obj=models.Author.objects.filter(book__publish__name='清华出版社').values('name','book__title')
print(obj)
进阶查询二
#手机号以 14552 开头的作者 出版过的所以书籍名称 以及 出版社名称
#方法一
obj=models.AuthorDetail.objects.filter(telephone__startswith='14552').values('author__book__title' , 'author__book__publish__name')
print(obj)
#方法二
obj=models.Author.objects.filter(authorDetail__telephone__startswith='14552').values('book__title','book__publish__name')
print(obj)
#方法三
obj=models.Book.objects.filter(authors__authorDetail__telephone__startswith='14552').values('authors__book__title','authors__book__publish__name')
print(obj)
related_name
反向查询时,如果定义了related_name ,则用related_name替换 表名,例如:
publish = ForeignKey(Book, related_name='bookList')
# 练习: 查询人民出版社出版过的所有书籍的名字与价格(一对多)
# 反向查询 不再按表名:book,而是related_name:bookList
obj=models.Publish.objects.filter(name="清华出版社").values("bookList__title","bookList__price")
聚合函数
from django.db.models import Avg,Min,Max ,Sum,Count
# 计算所有书籍的平均价格 图书价格的最大值
#aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
obj=models.Book.objects.all().aggregate(a=Avg('price'),m=Max('price'))
print(obj) #{'a': 47.5, 'm': Decimal('78.00')}
print(obj['m']-2) #76.00
分组查询
# 统计每个出版社出版的书籍的平均价格
ret=models.Book.objects.values('publish_id').annotate(a=Avg('price'))
print(ret) #<QuerySet [{'publish_id': 2, 'a': 69.0}, {'publish_id': 3, 'a': 30.0}, {'publish_id': 4, 'a': 22.0}]>
ret=models.Publish.objects.annotate(a=Avg('book__price'))
print(ret) #<QuerySet [<Publish: 山西出版社>, <Publish: 清华出版社>, <Publish: 江苏出版社>]>
ret = models.Publish.objects.annotate(a=Avg('book__price')).values('name', 'a')
print(ret) #<QuerySet [{'name': '山西出版社', 'a': 22.0}, {'name': '清华出版社', 'a': 69.0}, {'name': '江苏出版社', 'a': 30.0}]>
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?我们在book表里面加上两个字段:评论数:comment,收藏数:good
#查询点赞数大于评论数的书籍
ret=models.Book.objects.filter(good__gt=F('comment'))
# 查询点赞数大于评论数+20的书籍
#Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
ret=models.Book.objects.filter(good__gt=F('comment')+20)
print(ret) #<QuerySet [<Book: 今天是个好日子>, <Book: java核心>]>
#所有书籍的价格+20
models.Book.objects.all().update(price=F('price')+20)
#评论数大于100,和 ,点赞数大于100的
ret=models.Book.objects.filter(good__gt=100,comment__gt=100)
print(ret) #<QuerySet [<Book: java核心>, <Book: 故事会新编>]>
Q查询
Q 对象可以使用&(与) 、|(或)、~(非) 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
#评论数大于100,或者 点赞数大于100的
ret=models.Book.objects.filter(Q(good__gt=100)|Q(comment__gt=100))
print(ret) #<QuerySet [<Book: java核心>, <Book: 故事会新编>, <Book: LINUX学习>]>
#评论数大于100,或者 点赞数小于等于100的
ret = models.Book.objects.filter(~Q(good__gt=100) | Q(comment__gt=100))
print(ret)
#评论数大于100,或者 点赞数大于100的 且 price='42'
#逗号连接的普通查询条件放在最后
#查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
ret = models.Book.objects.filter(Q(good__gt=100) | Q(comment__gt=100),price='42')
print(ret)
#评论数大于100,或者 点赞数大于100的 且 price='42'
ret = models.Book.objects.filter(Q(good__gt=100) | Q(comment__gt=100) & Q(price='42')) #&优先级高
ret = models.Book.objects.filter(Q(Q(good__gt=100) | Q(comment__gt=100)) & Q(price='42')) #|优先级高
orm执行原生sql语句
在模型查询API不够用的情况下,我们还可以使用原始的SQL语句进行查询。
Django 提供两种方法使用原始SQL进行查询:一种是使用raw()方法,进行原始SQL查询并返回模型实例;另一种是完全避开模型层,直接执行自定义的SQL语句。
执行原生查询
raw()管理器方法用于原始的SQL查询,并返回模型的实例:
注意:raw()语法查询必须包含主键。
这个方法执行原始的SQL查询,并返回一个django.db.models.query.RawQuerySet 实例。 这个RawQuerySet 实例可以像一般的QuerySet那样,通过迭代来提供对象实例。
ret=models.Publish.objects.raw('select * from app01_publish;')
print(ret) #<RawQuerySet: select * from app01_publish;>
for i in ret:
print(i.name)
# 直接执行自定义SQL
# django提供的接口中获取数据库连接,然后像使用pymysql模块一样操作数据库
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
ret = cursor.fetchone()
查看orm生成原生sql语句
ret=models.Publish.objects.all()
print(ret)
from django.db.models import connection
print(connection.queries)
综合查询练习题
#1 查询每个作者的姓名以及出版的书的最高价格
ret=models.Author.objects.values('name').annotate(max_price=Max('book__price'))
print(ret) #注意:values写在annotate前面是作为分组依据用的,并且返回给你的值就是这个values里面的字段(name)和分组统计的结果字段数据(max_price)
#ret=models.Author.objects.annotate(max_price=Max('book__price')).values('name','max_price')#这种写法是按照Author表的id字段进行分组,返回给你的是这个表的所有model对象,这个对象里面包含着max_price这个属性,后面写values方法是获取的这些对象的属性的值,当然,可以加双下划线来连表获取其他关联表的数据,但是获取的其他关联表数据是你的这些model对象对应的数据,而关联获取的数据可能不是你想要的最大值对应的那些数据
# 2 查询作者id大于2作者的姓名以及出版的书的最高价格
ret=models.Author.objects.filter(id__gt=2).annotate(max_price=Max('book__price')).values('name','max_price')#记着,这个values取得是前面调用这个方法的表的所有字段值以及max_pirce的值,这也是为什么我们取关联数据的时候要加双划线的原因
print(ret)
#3 查询作者id大于2或者作者年龄大于等于20岁的女作者的姓名以及出版的书的最高价格
ret=models.Author.objects.filter(Q(id__gt=2)|Q(age__gte=20),sex='female').annotate(max_price=Max('book__price')).values('name','max_price')
#4 查询每个作者出版的书的最高价格 的平均值
ret=models.Author.objects.values('id').annotate(max_price=Max('book__price')).aggregate(Avg('max_price')) #{'max_price__avg': 555.0} 注意,aggregate是queryset的终止句,得到的是字典
ret=models.Author.objects.annotate(max_price=Max('book__price')).aggregate(Avg('max_price')) #{'max_price__avg': 555.0} 注意,aggregate是queryset的终止句,得到的是字典
补充
url.py 中的url(r'^admin/', admin.site.urls)路由操作admin.py
app应用中admin.py
from django.contrib import admin
from app01 import models
# Register your models here.
admin.site.register(models.Book)
admin.site.register(models.Author)
admin.site.register(models.AuthorDetail)
admin.site.register(models.Publish)
点击Tools 中run manage.py task 执行createsuperuser创建一个超级用户(username和password),然后可以访问http://127.0.0.1:8000/admin/ ,可以直接操作数据库进行增删改查。

| 访问http://127.0.0.1:8000/admin/ |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号