
linux内核的职责?
1 操作系统的核心——内核
术语“操作系统”通常包含两种不同含义。
1.指完整的软件包,这包括用来管理计算机资源的核心层软件,以及附带的所有标准软件工具,诸如命令行解释器、图形用户界面、文件操作工具和文本编辑器等。
2.在更狭义的范围内,是指管理和分配计算机资源(即CPU、RAM和设备)的核心层软件。
术语“内核”通常是第二种含义,本书中的“操作系统”一词也是这层意思。
虽然在没有内核的情况下,计算机也能运行程序,但有了内核会极大简化其他程序的编写和使用,令程序员“功力”大进、游刃有余。这要归功于内核为管理计算机的有限资源所提供的软件层。
一般情况下,Linux内核可执行文件采用/boot/vmlinuz或与之类似的路径名。而文件名的来历也颇有渊源。早期的UNIX实现称其内核为UNIX。在后续实现了虚拟内存机制的UNIX系统中,其内核名称变更为vmunix。对Linux来说,文件名称中的系统名需要调整,而以“z”替换“linux”末尾的“x”,意在表明内核是经过压缩的可执行文件。
内核的职责
内核所能执行的主要任务如下所示。
- 进程调度:计算机内均配备有一个或多个CPU(中央处理单元),以执行程序指令。与其他UNIX系统一样,Linux属于抢占式多任务操作系统。“多任务”意指多个进程(即运行中的程序)可同时驻留于内存,且每个进程都能获得对CPU的使用权。“抢占”则是指一组规则。这组规则控制着哪些进程获得对CPU的使用,以及每个进程能使用多长时间,这两者都由内核进程调度程序(而非进程本身)决定。
- 内存管理:以一二十年前的标准来看,如今计算机的内存容量可谓相当可观,但软件的规模也保持了相应地增长,故而物理内存(RAM)仍然属于有限资源,内核必须以公平、高效地方式在进程间共享这一资源。与大多数现代操作系统一样,Linux也采用了虚拟内存管理机制(6.4节),这项技术主要具有以下两方面的优势。
- 进程与进程之间、进程与内核之间彼此隔离,因此一个进程无法读取或修改内核或其他进程的内存内容。
- 只需将进程的一部分保持在内存中,这不但降低了每个进程对内存的需求量,而且还能在RAM中同时加载更多的进程。这也大幅提升了如下事件的发生概率,在任一时刻,CPU都有至少一个进程可以执行,从而使得对CPU资源的利用更加充分。
- 提供了文件系统:内核在磁盘之上提供有文件系统,允许对文件执行创建、获取、更新以及删除等操作。
- 创建和终止进程:内核可将新程序载入内存,为其提供运行所需的资源(比如,CPU、内存以及对文件的访问等)。这样一个运行中的程序我们称之为“进程”。一旦进程执行完毕,内核还要确保释放其占用资源,以供后续程序重新使用。
- 对设备的访问:计算机外接设备(鼠标、键盘、磁盘和磁带驱动器等)可实现计算机与外部世界的通信,这一通信机制包括输入、输出或是两者兼而有之。内核既为程序访问设备提供了简化版的标准接口,同时还要仲裁多个进程对每一个设备的访问。
- 联网:内核以用户进程的名义收发网络消息(数据包)。该任务包括将网络数据包路由至目标系统。
- 提供系统调用应用编程接口(API):进程可利用内核入口点(也称为系统调用)请求内核去执行各种任务。Linux系统调用API是本书的主题。3.1节会详细描述进程在执行系统调用时所经历的步骤。
除了上述特性外,一般而言,诸如Linux之类的多用户操作系统会为每个用户营造一种抽象:虚拟私有计算机(virtual private computer)。这就是说,每个用户都可以登录进入系统,独立操作,而与其他用户大致无干。例如,每个用户都有属于自己的磁盘存储空间(主目录)。再者,用户能够运行程序,而每一程序都能从CPU资源中“分得一杯羹”,运转于自有的虚拟地址空间中。而且这些程序还能独立访问设备,并通过网络传递信息。内核负责解决(多进程)访问硬件资源时可能引发的冲突,用户和进程对此则往往一无所知。
内核态和用户态
现代处理器架构一般允许CPU至少在两种不同状态下运行,即:用户态和核心态(有时也称之为监管态supervisor mode)。执行硬件指令可使CPU在两种状态间来回切换。与之对应,可将虚拟内存区域划分(标记)为用户空间部分或内核空间部分。在用户态下运行时,CPU只能访问被标记为用户空间的内存,试图访问属于内核空间的内存会引发硬件异常。当运行于核心态时,CPU既能访问用户空间内存,也能访问内核空间内存。
仅当处理器在核心态运行时,才能执行某些特定操作。这样的例子包括:执行宕机(halt)指令去关闭系统,访问内存管理硬件,以及设备I/O操作的初始化等。实现者们利用这一硬件设计,将操作系统置于内核空间。这确保了用户进程既不能访问内核指令和数据结构,也无法执行不利于系统运行的操作。
以进程及内核视角检视系统
在完成诸多日常编程任务时,程序员们习惯于以面向进程(process-oriented)的思维方式来考虑编程问题。然而,在研究本书后续所涵盖的各种主题时,读者有必要转换视角,站在内核的角度上来看问题。为突显二者间的差异,本书接下来会分别从进程和内核视角来检视系统。
一个运行系统通常会有多个进程并行其中。对进程来说,许多事件的发生都无法预期。执行中的进程不清楚自己对CPU的占用何时“到期”,系统随之又会调度哪个进程来使用CPU(以及以何种顺序来调度),也不知道自己何时会再次获得对CPU的使用。信号的传递和进程间通信事件的触发由内核统一协调,对进程而言,随时可能发生。诸如此类,进程都一无所知。进程不清楚自己在RAM中的位置。或者换种更通用的说法,进程内存空间的某块特定部分如今到底是驻留在内存中还是被保存在交换空间(磁盘空间中的保留区域,作为计算机RAM的补充)里,进程本身并不知晓。与之类似,进程也闹不清自己所访问的文件“居于”磁盘驱动器的何处,只是通过名称来引用文件而已。进程的运作方式堪称“与世隔绝”——进程间彼此不能直接通信。进程本身无法创建出新进程,哪怕“自行了断”都不行。最后还有一点,进程也不能与计算机外接的输入输出设备直接通信。
相形之下,内核则是运行系统的中枢所在,对于系统的一切无所不知、无所不能,为系统上所有进程的运行提供便利。由哪个进程来接掌对 CPU 的使用,何时“接任”,“任期”多久,都由内核说了算。在内核维护的数据结构中,包含了与所有正在运行的进程有关的信息。随着进程的创建、状态发生变化或者终结,内核会及时更新这些数据结构。内核所维护的底层数据结构可将程序使用的文件名转换为磁盘的物理位置。此外,每个进程的虚拟内存与计算机物理内存及磁盘交换区之间的映射关系,也在内核维护的数据结构之列。进程间的所有通信都要通过内核提供的通信机制来完成。响应进程发出的请求,内核会创建新的进程,终结现有进程。最后,由内核(特别是设备驱动程序)来执行与输入/输出设备之间的所有直接通信,按需与用户进程交互信息。
本书后续内容中会出现如下措辞,例如:“某进程可创建另一个进程”、“某进程可创建管道”、“某进程可将数据写入文件”,以及“调用exit()以终止某进程”。请务必牢记,以上所有动作都是由内核来居中“调停”,上面的说法不过是“某进程可以请求内核创建另一个进程”的缩略语,以此类推。
进阶阅读
涵盖操作系统概念和设计,尤其是对 UNIX 操作系统加以重点关注的现代教科书包括:[Tanenbaum, 2007]、[Tanenbaum & Woodhull,2006]以及[Vahalia, 1996],最后一本包含了与虚拟内存架构有关的详细内容。[Goodheart & Cox, 1994]详细介绍了System V Release 4。[Maxwell, 1999]则是有选择性地针对 Linux 2.2.5 的部分内核源码进行了注释。[Lions, 1996]对第六版UNIX源码进行了详尽阐释,并一直是研究UNIX操作系统内幕的入门级经典。[Bovet & Cesati, 2005]描述了Linux2.6内核的实现。
2 shell
shell是一种具有特殊用途的程序,主要用于读取用户输入的命令,并执行相应的程序以响应命令。有时,人们也称之为命令解释器。
术语登录shell(login shell)是指用户刚登录系统时,由系统创建,用以运行shell的进程。尽管某些操作系统将命令解释器集成于内核中,而对 UNIX 系统而言,shell 只是一个用户进程。shell的种类繁多,登入同一台计算机的不同用户同时可使用不同的shell(就单个用户来说,情况也一样)。纵观UNIX历史,出现过以下几种重要的shell。
- Bourne shell(sh):这款由Steve Bourne编写的shell历史最为悠久,且应用广泛,曾是第七版UNIX的标配shell。Bourne shell包含了在其他shell中常见的许多特性,I/O重定向、管道、文件名生成(通配符)、变量、环境变量处理、命令替换、后台命令执行以及函数。对于所有问世于第七版UNIX之后的实现而言,除了可能提供有其他shell之外,都附带了Bourne shell。
- C shell(csh):由Bill Joy于加州大学伯克利分校编写而成。其命名则源于该脚本语言的流控制语法与C语言有着许多相似之处。C shell当时提供了若干极为实用的交互式特性,并不为Bourne shell所支持,这其中包括命令的历史记录、命令行编辑功能、任务控制和别名等。C shell与Bourne shell并不兼容。尽管C shell曾是BSD系统标配的交互式shell,但一般情况下,人们还是喜欢针对Bourne shell编写shell脚本(稍后介绍),以便其能够在所有UNIX实现上移植。
- Korn shell(ksh):AT&T贝尔实验室的David Korn编写了这款shell,作为Bourne shell的“继任者”。在保持与Bourne shell兼容的同时,Korn shell还吸收了那些与C shell相类似的交互式特性。
- Bourne again shell(bash):这款shell是GNU项目对Bourne shell的重新实现。Bash提供了与C shell和Korn shel所类似的交互式特性。Brian Fox 和Chet Ramey是bash的主要作者。bash或许是Linux上应用最为广泛的shell了。在Linux上,Bourne shell(sh)其实正是由bash仿真提供的。
POSIX.2-1992基于当时的Korn shell版本定义了一个shell标准。如今,Korn shell和bash都符合POSIX规范,但两者都提供了大量对标准的扩展,其扩展之间存在许多差异。
设计shell的目的不仅仅是用于人机交互,对shell脚本(包含shell命令的文本文件)进行解释也是其用途之一。为实现这一目的,每款shell都内置有许多通常与编程语言相关的功能,其中包括变量、循环和条件语句、I/O命令以及函数等。
尽管在语法方面有所差异,每款shell执行的任务都大致相同。除非指明是某款特定shell的操作,否则书中的“shell”都会按所描述的方式运作。本书绝大多数需要用到shell的示例都会使用bash,若无其他说明,读者可假定这些示例也能以相同方式在其他类Bourne的shell上运行。
3 用户和组
系统会对每个用户的身份做唯一标识,用户可隶属于多个组。
用户
系统的每个用户都拥有唯一的登录名(用户名)和与之相对应的整数型用户ID(UID)。系统密码文件/etc/passwd为每个用户都定义有一行记录,除了上述两项信息外,该记录还包含如下信息。
- 组ID:用户所属第一个组的整数型组ID。
- 主目录:用户登录后所居于的初始目录。
- 登录shell:执行以解释用户命令的程序名称。
该记录还能以加密形式保存用户密码。然而,出于安全考虑,用户密码往往存储于单独的shadow密码文件中,仅供特权用户阅读。
组
出于管理目的,尤其是为了控制对文件和其他资源的访问,将多个用户分组是非常实用的做法。例如,某项目的开发团队人员需要共享同一组文件,就可以将他们编为同一组的成员。在早期的UNIX实现中,一个用户只能隶属于一个组。BSD率先允许一个用户同时属于多个组,这一理念后来被其他UNIX实现纷纷效仿,并最终成为POSIX.1-1990标准。每个用户组都对应着系统组文件/etc/group中的一行记录,该记录包含如下信息。
- 组名:(唯一的)组名称。
- 组ID(GID):与组相关的整数型ID。
- 用户列表:隶属于该组的用户登录名列表(通过密码文件记录的group ID字段未能标识出的该组其他成员,也在此列),以逗号分隔。
超级用户
超级用户在系统中享有特权。超级用户账号的用户ID为0,通常登录名为root。在一般的UNIX系统上,超级用户凌驾于系统的权限检查之上。因此,无论对文件施以何种访问权限限制,超级用户都可以访问系统中的任何文件,也能发送信号干预系统运行的所有用户进程。系统管理员可以使用超级用户账号来执行各种系统管理任务。
4 单根目录层级、目录、链接及文件
内核维护着一套单根目录结构,以放置系统的所有文件。(这与微软Windows之类的操作系统形成了鲜明对照,Windows系统的每个磁盘设备都有各自的目录层级。)这一目录层级的根基就是名为“/”的根目录。所有的文件和目录都是根目录的“子孙”。图 1-2 所示为这种文件层级结构的示例。
文件类型
在文件系统内,会对文件类型进行标记,以表明其种类。其中一种用来表示普通数据文件,人们常称之为“普通文件”或“纯文本文件”,以示与其他种类的文件有所区别。其他文件类型包括设备、管道、套接字、目录以及符号链接。
术语“文件”常用来指代任意类型的文件,不仅仅指普通文件。
路径和链接
目录是一种特殊类型的文件,内容采用表格形式,数据项包括文件名以及对相应文件的引用。这一“文件名+引用”的组合被称为链接。每个文件都可以有多条链接,因而也可以有多个名称,在相同或不同的目录中出现。
目录可包含指向文件或其他目录的链接。路径间的链接建立起如图2-1所示的目录层级。
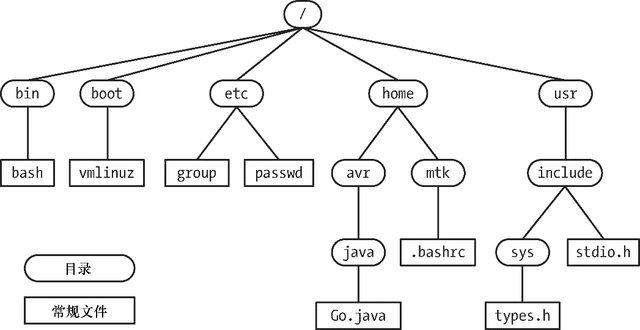
图2-1:Linux单根目录层级的一部分
每个目录至少包含两条记录:.和..,前者是指向目录自身的链接,后者是指向其上级目录—— 父目录的链接。除根目录外,每个目录都有父目录。对于根目录而言,..是指向根目录自身的链接(因此,/..等于/)。
符号链接
类似于普通链接,符号链接给文件起了一个“别号(alternative name)”。在目录列表中,普通链接是内容为“文件名+指针”的一条记录,而符号链接则是经过特殊标记的文件,内容包含了另一文件的名称。(换言之,一个符号链接对应着目录中内容为“文件名+指针”的一条记录,指针指向的文件内容①为另一个文件名的字符串。)所谓“另一文件”通常被称为符号链接的目标,人们一般会说符号链接“指向”或“引用”目标文件。在多数情况下,只要系统调用用到了路径名,内核会自动解除(换言之,按照)该路径名中符号链接的引用,以符号链接所指向的文件名来替换符号链接。若符号链接的目标文件自身也是一个符号链接,那么上述过程会以递归方式重复下去。(为了应对可能出现的循环引用,内核对解除引用的次数作了限制。)如果符号链接指向的文件并不存在,那么可将该链接视为空链接(dangling link)。
通常,人们会分别使用硬链接(hard link)或软链接(soft link)这样的术语来指代正常链接和符号链接。之所以存在这两种不同类型的链接,将在第18章做出解释。
文件名
在大多数Linux文件系统上,文件名最长可达255个字符。文件名可以包含除“/”和空字符(\0)外的所有字符。但是,只建议使用字母、数字、点(“.”)、下划线(“_”)以及连字符(“−”)。SUSv3将这65个字符的集合[-._a-zA-Z0-9]称为可移植文件名字符集(portable filename character set)。
对于可移植文件名字符集以外的字符,由于其可能会在shell、正则表达式或其他场景中具有特殊含义,故而应避免在文件名中使用。如在上述环境中出现了包含特殊含义字符的文件名,则需要进行转义,即对此类字符进行特殊标记(一般会在特殊字符前插入一个“\”),以指明不应以特殊含义对其进行解释。若场境不支持转义机制,则不能使用此类文件名。
此外,还应避免以连字符(“-”)作为文件名的起始字符,因为一旦在shell命令中使用这种文件名,会被误认为命令行选项开关。
路径名
路径名是由一系列文件名组成的字符串,彼此以“/”分隔,首字符可以为“/”(非强制)②。除却最后一个文件名外,该系列文件名均为目录名称(或为指向目录的符号链接)。路径名的尾部③可标识任意类型的文件,包括目录在内。有时将该字符串中最后一个“/”字符之前的部分称为路径名的目录部分,将其之后的部分称为路径名的文件部分或基础部分。
路径名应按从左至右的顺序阅读,路径名中每个文件名之前的部分,即为该文件所处目录。可在路径名中任意位置后引入字符串“..”④,用以指代路径名中当前位置的父目录。
路径名描述了单根目录层级下的文件位置,又可分为绝对路径名和相对路径名:
- 绝对路径名以“/”开始,指明文件相对于根目录的位置。图2-1中的/home/mtk/. bashrc、/usr/include以及/(根路径的路径名)都是绝对路径名的例子。
- 相对路径名定义了相对于进程当前工作目录(见下文)的文件位置,与绝对路径名相比,相对路径名缺少了起始的“/”。如图2-1所示,在目录usr下,可使用相对路径名include/sys/types.h来引用文件types.h,在目录avr下,可使用相对路径名../mtk/.bashrc来访问文件.bashrc。
当前工作目录
每个进程都有一个当前工作目录(有时简称为进程工作目录或当前目录)。这就是单根目录层级下进程的“当前位置”,也是进程解释相对路径名的参照点。
进程的当前工作目录继承自其父进程。对登录shell来说,其初始当前工作目录,是依据密码文件中该用户记录的主目录字段来设置。可使用cd命令来改变shell的当前工作目录。
文件的所有权和权限
每个文件都有一个与之相关的用户ID和组ID,分别定义文件的属主和属组。系统根据文件的所有权来判定用户对文件的访问权限。
为了访问文件,系统把用户分为3类:文件的属主(有时,也称为文件的用户)、与文件组(group)ID相匹配的属组成员用户以及其他用户。可为以上3类用户分别设置3种权限(共计9种权限位):只允许查看文件内容的读权限;允许修改文件内容的写权限;允许执行文件的执行权限。这里的文件要么指程序,要么是交由某种解释程序(通常指shell的一种,但也有例外)处理的脚本。
也可针对目录进行上述权限设置,但意义稍有不同。读权限允许列出目录内容(即该目录下的文件名),写权限允许对目录内容进行更改(比如,添加、修改或删除文件名),执行(有时也称为搜索)权限允许对目录中的文件进行访问(但需受文件自身访问权限的约束)。
5 文件I/O模型
UNIX系统I/O模型最为显著的特性之一是其I/O通用性概念。也就是说,同一套系统调用(open()、read()、write()、close()等)所执行的I/O操作,可施之于所有文件类型,包括设备文件在内。(应用程序发起的I/O请求,内核会将其转化为相应的文件系统操作,或者设备驱动程序操作,以此来执行针对目标文件或设备的I/O操作。)因此,采用这些系统调用的程序能够处理任何类型的文件。
就本质而言,内核只提供一种文件类型:字节流序列,在处理磁盘文件、磁盘或磁带设备时,可通过lseek()系统调用来随机访问。
许多应用程序和函数库都将新行符(十进制ASCII码为10,有时亦称其为换行)视为文本中一行的结束和另一行的开始。UNIX系统没有文件结束符的概念,读取文件时如无数据返回,便会认定抵达文件末尾。
文件描述符
I/O 系统调用使用文件描述符——(往往是数值很小的)非负整数——来指代打开的文件。获取文件描述符的常用手法是调用 open(),在参数中指定 I/O 操作目标文件的路径名。
通常,由shell启动的进程会继承3个已打开的文件描述符:描述符0为标准输入,指代为进程提供输入的文件;描述符1为标准输出,指代供进程写入输出的文件;描述符2为标准错误,指代供进程写入错误消息或异常通告的文件。在交互式shell或程序中,上述三者一般都指向终端。在stdio函数库中,这几种描述符分别与文件流stdin、stdout和stderr相对应。
stdio函数库
C编程语言在执行文件I/O操作时,往往会调用C语言标准库的I/O函数。也将这样一组I/O函数称为stdio函数库,其中包括fopen()、fclose()、scanf()、printf()、fgets()、fputs()等。stdio函数位于I/O系统调用层(open()、close()、read()、write()等)之上。
本书假定读者已经了解了C语言的标准I/O(stdio)函数,因此也不会介绍这方面的内容。更多与stdio函数库有关的信息请参考[Kernighan & Ritchie, 1988]、[Harbison & Steele,2002]、[Plauger、1992]和[Stevens & Rago, 2005]。
6 程序
程序通常以两种面目示人。其一为源码形式,由使用编程语言(比如,C语言)写成的一系列语句组成,是人类可以阅读的文本文件。要想执行程序,则需将源码转换为第二种形式——计算机可以理解的二进制机器语言指令。(这与脚本形成了鲜明对照,脚本是包含命令的文本文件,可以由shell或其他命令解释器之类的程序直接处理。)一般认为,术语“程序”的上述两种含义几近相同,因为经过编译和链接处理,会将源码转换为语义相同的二进制机器码。
过滤器
从stdin读取输入,加以转换,再将转换后的数据输出到stdout,常常将拥有上述行为的程序称为过滤器,cat、grep、tr、sort、wc、sed、awk均在其列。
命令行参数
C语言程序可以访问命令行参数,即程序运行时在命令行中输入的内容。要访问命令行参数,程序的main()函数需做如下声明:
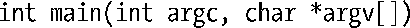
argc变量包含命令行参数的总个数,argv指针数组的成员指针则逐一指向每个命令行参数字符串。首个字符串argv[0],标识程序名本身。
7 进程
简而言之,进程是正在执行的程序实例。执行程序时,内核会将程序代码载入虚拟内存,为程序变量分配空间,建立内核记账(bookkeeping)数据结构,以记录与进程有关的各种信息(比如,进程ID、用户ID、组ID以及终止状态等)。
在内核看来,进程是一个个实体,内核必须在它们之间共享各种计算机资源。对于像内存这样的受限资源来说,内核一开始会为进程分配一定数量的资源,并在进程的生命周期内,统筹该进程和整个系统对资源的需求,对这一分配进行调整。程序终止时,内核会释放所有此类资源,供其他进程重新使用。其他资源(如CPU、网络带宽等)都属于可再生资源,但必须在所有进程间平等共享。
进程的内存布局
逻辑上将一个进程划分为以下几部分(也称为段)。
- 文本:程序的指令。
- 数据:程序使用的静态变量。
- 堆:程序可从该区域动态分配额外内存。
- 栈:随函数调用、返回而增减的一片内存,用于为局部变量和函数调用链接信息分配存储空间。
创建进程和执行程序
进程可使用系统调用fork()来创建一个新进程。调用fork()的进程被称为父进程,新创建的进程则被称为子进程。内核通过对父进程的复制来创建子进程。子进程从父进程处继承数据段、栈段以及堆段的副本后,可以修改这些内容,不会影响父进程的“原版”内容。(在内存中被标记为只读的程序文本段则由父、子进程共享。)
然后,子进程要么去执行与父进程共享代码段中的另一组不同函数,或者,更为常见的情况是使用系统调用execve()去加载并执行一个全新程序。execve()会销毁现有的文本段、数据段、栈段及堆段,并根据新程序的代码,创建新段来替换它们。
以execve()为基础,C语言库还提供了几个相关函数,接口虽然略有不同,但功能全都相同。以上所有库函数的名称均以字符串“exec”打头,在函数间差异无关宏旨的场合,本书会用符号exec()作为这些库函数的统称。不过,请读者牢记,实际上根本不存在名为exec()的库函数。
一般情况下,书中会使用“执行”一词来指代execve()及其衍生函数所实施的操作。
进程ID和父进程ID
每一进程都有一个唯一的整数型进程标识符(PID)。此外,每一进程还具有一个父进程标识符(PPID)属性,用以标识请求内核创建自己的进程。
进程终止和终止状态
可使用以下两种方式之一来终止一个进程:其一,进程可使用_exit()系统调用(或相关的exit()库函数),请求退出;其二,向进程传递信号,将其“杀死”。无论以何种方式退出,进程都会生成“终止状态”,一个非负小整数,可供父进程的wait()系统调用检测。在调用_exit()的情况下,进程会指明自己的终止状态。若由信号来“杀死”进程,则会根据导致进程“死亡”的信号类型来设置进程的终止状态。(有时会将传递进_exit()的参数称为进程的“退出状态”,以示与终止状态有所不同,后者要么指传递给_exit()的参数值,要么表示“杀死”进程的信号。)
根据惯例,终止状态为0表示进程“功成身退”,非0则表示有错误发生。大多数shell会将前一执行程序的终止状态保存于shell变量$?中。
进程的用户和组标识符(凭证)
每个进程都有一组与之相关的用户ID (UID)和组ID (GID),如下所示。
- 真实用户 ID 和组 ID:用来标识进程所属的用户和组。新进程从其父进程处继承这些ID。登录shell则会从系统密码文件的相应字段中获取其真实用户ID和组ID。
- 有效用户ID和组ID:进程在访问受保护资源(比如,文件和进程间通信对象)时,会使用这两个 ID(并结合下述的补充组ID)来确定访问权限。一般情况下,进程的有效ID与相应的真实ID值相同。正如即将讨论的那样,改变进程的有效ID实为一种机制,可使进程具有其他用户或组的权限。
- 补充组ID:用来标识进程所属的额外组。新进程从其父进程处继承补充组ID。登录shell则从系统组文件中获取其补充组ID。
特权进程
在UNIX系统上,就传统意义而言,特权进程是指有效用户ID为0(超级用户)的进程。通常由内核所施加的权限限制对此类进程无效。与之相反,术语“无特权”(或非特权)进程是指由其他用户运行的进程。此类进程的有效用户ID为非0值,且必须遵守由内核所强加的权限规则。
由某一特权进程创建的进程,也可以是特权进程。例如,一个由root(超级用户)发起的登录shell。成为特权进程的另一方法是利用set-user-ID机制,该机制允许某进程的有效用户ID等同于该进程所执行程序文件的用户ID。
能力(Capabilities)
始于内核2.2,Linux把传统上赋予超级用户的权限划分为一组相互独立的单元(称之为“能力”)。每次特权操作都与特定的能力相关,仅当进程具有特定能力时,才能执行相应操作。传统意义上的超级用户进程(有效用户ID为0)则相应开启了所有能力。
赋予某进程部分能力,使得其既能够执行某些特权级操作,又防止其执行其他特权级操作。
本书第39章会对能力做深入讨论。在本书后文中,当述及只能由特权进程执行的特殊操作时,一般都会在括号中标明其具体能力。能力的命名以CAP_为前缀,例如,CAP_KILL。
init进程
系统引导时,内核会创建一个名为init的特殊进程,即“所有进程之父”,该进程的相应程序文件为/sbin/init。系统的所有进程不是由init(使用 frok())“亲自”创建,就是由其后代进程创建。init进程的进程号总为1,且总是以超级用户权限运行。谁(哪怕是超级用户)都不能“杀死”init进程,只有关闭系统才能终止该进程。init 的主要任务是创建并监控系统运行所需的一系列进程。(手册页init(8)中包含了init进程的详细信息。)
守护进程
守护进程指的是具有特殊用途的进程,系统创建和处理此类进程的方式与其他进程相同,但以下特征是其所独有的:
- “长生不老”。守护进程通常在系统引导时启动,直至系统关闭前,会一直“健在”。
- 守护进程在后台运行,且无控制终端供其读取或写入数据。
守护进程中的例子有syslogd(在系统日志中记录消息)和httpd(利用HTTP分发Web页面)。
环境列表
每个进程都有一份环境列表,即在进程用户空间内存中维护的一组环境变量。这份列表的每一元素都由一个名称及其相关值组成。由fork()创建的新进程,会继承父进程的环境副本。这也为父子进程间通信提供了一种机制。当进程调用exec()替换当前正在运行的程序时,新程序要么继承老程序的环境,要么在exec()调用的参数中指定新环境并加以接收。
在绝大多数shell中,可使用export命令来创建环境变量(C shell使用setenv命令),如下所示:
本书在展示交互式输入、输出的shell会话日志时,总是以黑体字来呈现输入文本。有时也会在日志中以斜体字形式加注,以解释输入的命令和产生的输出。
C语言程序可使用外部变量(char **environ)来访问环境,而库函数也允许进程去获取或修改自己环境中的值。
环境变量的用途多种多样。例如,shell定义并使用了一系列变量,供shell执行的脚本和程序访问。其中包括:变量HOME(明确定义了用户登录目录的路径名)、变量PATH(指明了用户输入命令后,shell查找与之相应程序时所搜索的目录列表)。
资源限制
每个进程都会消耗诸如打开文件、内存以及CPU时间之类的资源。使用系统调用setrlimit(),进程可为自己消耗的各类资源设定一个上限。此类资源限制的每一项均有两个相关值:软限制(soft limit)限制了进程可以消耗的资源总量,硬限制(hard limit)软限制的调整上限。非特权进程在针对特定资源调整软限制值时,可将其设置为0到相应硬限制值之间的任意值,但硬限制值则只能调低,不能调高。
由fork()创建的新进程,会继承其父进程对资源限制的设置。
使用ulimit命令(在C shell中为limit)可调整shell的资源限制。shell为执行命令所创建的子进程会继承上述资源设置。
8 内存映射
调用系统函数mmap()的进程,会在其虚拟地址空间中创建一个新的内存映射。
映射分为两类。
- 文件映射:将文件的部分区域映射入调用进程的虚拟内存。映射一旦完成,对文件映射内容的访问则转化为对相应内存区域的字节操作。映射页面会按需自动从文件中加载。
- 相映成趣的是并无文件与之相对应的匿名映射,其映射页面的内容会被初始化为0。
由某一进程所映射的内存可以与其他进程的映射共享。达成共享的方式有二:其一是两个进程都针对某一文件的相同部分加以映射,其二是由fork()创建的子进程自父进程处继承映射。当两个或多个进程共享的页面相同时,进程之一对页面内容的改动是否为其他进程所见呢?这取决于创建映射时所传入的标志参数。若传入标志为私有,则某进程对映射内容的修改对于其他进程是不可见的,而且这些改动也不会真地落实到文件上;若传入标志为共享,对映射内容的修改就会为其他进程所见,并且这些修改也会造成对文件的改动。内存映射用途很多,其中包括:以可执行文件的相应段来初始化进程的文本段、内存(内容填充为0)分配、文件I/O(即映射内存I/O)以及进程间通信(通过共享映射)。
9 静态库和共享库
所谓目标库是这样一种文件:将(通常是逻辑相关的)一组函数代码加以编译,并置于一个文件中,供其他应用程序调用。这一做法有利于程序的开发和维护。现代UNIX系统提供两种类型的对象库:静态库和共享库。
静态库
静态库(有时,也称之为档案文件[archives])是早期UNIX系统中唯一的一种目标库。本质上说来,静态库是对已编译目标模块的一种结构化整合。要使用静态库中的函数,需要在创建程序的链接命令中指定相应的库。主程序会对静态库中隶属于各目标模块的不同函数加以引用。链接器在解析了引用情况后,会从库中抽取所需目标模块的副本,将其复制到最终的可执行文件中,这就是所谓静态链接。对于所需库内的各目标模块,采用静态链接方式生成的程序都存有一份副本。这会引起诸多不便。其一,在不同的可执行文件中,可能都存有相同目标代码的副本,这是对磁盘空间的浪费。同理,调用同一库函数的程序,若均以静态链接方式生成,且又于同时加以执行,这会造成内存浪费,因为每个程序所调用的函数都各有一份副本驻留在内存中,此其二。此外,如果对库函数进行了修改,需要重新加以编译、生成新的静态库,而所有需要调用该函数“更新版”的应用,都必须与新生成的静态库重新链接。
共享库
设计共享库的目的是为了解决静态库所存在的问题。
如果将程序链接到共享库,那么链接器就不会把库中的目标模块复制到可执行文件中,而是在可执行文件中写入一条记录,以表明可执行文件在运行时需要使用该共享库。一旦在运行时将可执行文件载入内存,一款名为“动态链接器”的程序会确保将可执行文件所需的动态库找到,并载入内存,随后实施运行时链接,解析可执行文件中的函数调用,将其与共享库中相应的函数定义关联起来。在运行时,共享库代码在内存中只需保留一份,且可供所有运行中的程序使用。
经过编译处理的函数仅在共享库内保存一份,从而节约了磁盘空间。另外,这一设计还能确保各类程序及时使用到函数的最新版本,功莫大焉,只需将带有函数新定义体的共享库重新加以编译即可,程序会在下次执行时自动使用新函数。
10 进程间通信及同步
Linux系统上运行有多个进程,其中许多都是独立运行。然而,有些进程必须相互合作以达成预期目的,因此彼此间需要通信和同步机制。
读写磁盘文件中的信息是进程间通信的方法之一。可是,对许多程序来说,这种方法既慢又缺乏灵活性。因此,像所有现代UNIX实现那样,Linux也提供了丰富的进程间通信(IPC)机制,如下所示。
- 信号(signal),用来表示事件的发生。
- 管道(亦即shell用户所熟悉的“|”操作符)和FIFO,用于在进程间传递数据。
- 套接字,供同一台主机或是联网的不同主机上所运行的进程之间传递数据。
- 文件锁定,为防止其他进程读取或更新文件内容,允许某进程对文件的部分区域加以锁定。
- 消息队列,用于在进程间交换消息(数据包)。
- 信号量(semaphore),用来同步进程动作。
- 共享内存,允许两个及两个以上进程共享一块内存。当某进程改变了共享内存的内容时,其他所有进程会立即了解到这一变化。
UNIX系统的IPC机制种类如此繁多,有些功能还互有重叠,部分原因是由于各种IPC机制是在不同的UNIX实现上演变而来的,需要遵循的标准也各不相同。例如,就本质而言,FIFO和UNIX套接字功能相同,允许同一系统上并无关联的进程彼此交换数据。二者之所以并存于现代UNIX系统之中,是由于FIFO来自System V,而套接字则源于BSD。
11 信号
尽管上一节将信号视为 IPC 的方法之一,但其在其他方面的广泛应用则更为普遍,因此值得深入讨论。
人们往往将信号称为“软件中断”。进程收到信号,就意味着某一事件或异常情况的发生。信号的类型很多,每一种分别标识不同的事件或情况。采用不同的整数来标识各种信号类型,并以SIGxxxx形式的符号名加以定义。
内核、其他进程(只要具有相应的权限)或进程自身均可向进程发送信号。例如,发生下列情况之一时,内核可向进程发送信号。
- 用户键入中断字符(通常为Control-C)。
- 进程的子进程之一已经终止。
- 由进程设定的定时器(告警时钟)已经到期。
- 进程尝试访问无效的内存地址。
在shell中,可使用kill命令向进程发送信号。在程序内部,系统调用kill()可提供相同的功能。
收到信号时,进程会根据信号采取如下动作之一。
- 忽略信号。
- 被信号“杀死”。
- 先挂起,之后再被专用信号唤醒。
就大多数信号类型而言,程序可选择不采取默认的信号动作,而是忽略信号(当信号的默认处理行为并非忽略此信号时,会派上用场)或者建立自己的信号处理器。信号处理器是由程序员定义的函数,会在进程收到信号时自动调用,根据信号的产生条件执行相应动作。
信号从产生直至送达进程期间,一直处于挂起状态。通常,系统会在接收进程下次获得调度时,将处于挂起状态的信号同时送达。如果接收进程正在运行,则会立即将信号送达。然而,程序可以将信号纳入所谓“信号屏蔽”⑤以求阻塞该信号。如果产生的信号处于“信号屏蔽”之列,那么此信号将一直保持挂起状态,直至解除对该信号的阻塞。(亦即从信号屏蔽中移除。)
12 线程
在现代UNIX实现中,每个进程都可执行多个线程。可将线程想象为共享同一虚拟内存及一干其他属性的进程。每个线程都会执行相同的程序代码,共享同一数据区域和堆。可是,每个线程都拥有属于自己的栈,用来装载本地变量和函数调用链接信息。
线程之间可通过共享的全局变量进行通信。借助于线程 API 所提供的条件变量和互斥机制,进程所属的线程之间得以相互通信并同步行为——尤其是在对共享变量的使用方面。此外,利用2.10节所述的IPC和同步机制,线程间也能彼此通信。
线程的主要优点在于协同线程之间的数据共享(通过全局变量)更为容易,而且就某些算法而论,以多线程来实现比之以多进程实现要更加自然。再者,显而易见,多线程应用能从多处理器硬件的并行处理中获益匪浅。
13 进程组和shell任务控制
shell执行的每个程序都会在一个新进程内发起。比如,shell创建了3个进程来执行以下管道命令(在当前的工作目录下,根据文件大小对文件进行排序并显示):

除Bourne shell以外,几乎所有的主流shell都提供了一种交互式特性,名为任务控制。该特性允许用户同时执行并操纵多条命令或管道。在支持任务控制的shell中,会将管道内的所有进程置于一个新进程组或任务中。(如果情况很简单,shell命令行只包含一条命令,那么就会创建一个只包含单个进程的新进程组。)进程组中的每个进程都具有相同的进程组标识符(以整数形式),其实就是进程组中某个进程(也称为进程组组长process group leader)的进程ID。
内核可对进程组中的所有成员执行各种动作,尤其是信号的传递。如下节所述,支持任务控制的shell会利用这一特性,以挂起或恢复执行管道中的所有进程。
14 会话、控制终端和控制进程
会话指的是一组进程组(任务)。会话中的所有进程都具有相同的会话标识符。会话首进程(session leader)是指创建会话的进程,其进程ID会成为会话ID。
使用会话最多的是支持任务控制的shell,由shell创建的所有进程组与shell自身隶属于同一会话,shell是此会话的会话首进程。
通常,会话都会与某个控制终端相关。控制终端建立于会话首进程初次打开终端设备之时。对于由交互式shell所创建的会话,这恰恰是用户的登录终端。一个终端至多只能成为一个会话的控制终端。
打开控制终端会致使会话首进程成为终端的控制进程。一旦断开了与终端的连接(比如,关闭了终端窗口),控制进程将会收到SIGHUP信号。
在任一时点,会话中总有一个前台进程组(前台任务),可以从终端中读取输入,向终端发送输出。如果用户在控制终端中输入了“中断”(通常是Control-C)或“挂起”字符(通常是Control-Z),那么终端驱动程序会发送信号以终止或挂起(亦即停止)前台进程组。一个会话可以拥有任意数量的后台进程组(后台任务),由以“&”字符结尾的行命令来创建。
支持任务控制的shell提供如下命令:列出所有任务,向任务发送信号,以及在前后台任务之间来回切换。
15 伪终端
伪终端是一对相互连接的虚拟设备,也称为主从设备。在这对设备之间,设有一条IPC信道,可供数据进行双向传递。
从设备(slave device)所提供的接口,其行为方式与终端相类似,基于这一特点,可以将某个为终端编写的程序与从设备连接起来,然后,再利用连接到主设备的另一程序来驱动这一“面向终端”的程序,这是伪终端的一个关键用途。由“驱动程序”⑥所产生的输出,在经由终端驱动程序的常规输入处理(例如,默认情况下,会把回车符映射为换行符)后,会作为输入传递给与从设备相连的面向终端的程序。而由面向终端的程序向从设备写入的任何数据又作为“驱动程序”的输入来传递(在执行完所有常规的终端输入处理后)。换句话说,“驱动程序”所履行的功能,在效果上等同于用户通常在传统终端上所执行的操作。
伪终端广泛应用于各种应用领域,最知名的要数telnet和ssh之类提供网络登录服务的应用,以及X Window系统所提供的终端窗口实现。
16 日期和时间
进程涉及两种类型的时间。
- 真实时间:指的是在进程的生命期内(所经历的时间或时钟时间),以某个标准时间点(日历时间)或固定时间点(通常是进程的启动时间)为起点测量得出的时间。在UNIX系统上,日历时间是以国际协调时间(简称UTC)1970年1月1日凌晨为起始点,按秒测量得出的时间,再进行时区调整(定义时区的基准点为穿过英格兰格林威治的经线)⑦。这一日期与UNIX系统的生日很接近,也被称为纪元(Epoch)。
- 进程时间:亦称为CPU时间,指的是进程自启动起来,所占用的CPU时间总量。可进一步将CPU时间划分为系统CPU时间和用户CPU时间。前者是指在内核模式中,执行代码所花费的时间(比如,执行系统调用,或代表进程执行其他的内核服务)。后者是指在用户模式中,执行代码所花费的时间(比如,执行常规的程序代码)。
time命令会显示出真实时间、系统CPU时间,以及为执行管道中的多个进程而花费的用户CPU时间。
17 客户端/服务器架构
本书有多处论及客户端/服务器应用程序的设计和实现。
客户端/服务器应用由两个组件进程组成。
- 客户端:向服务器发送请求消息,请求服务器执行某些服务。
- 服务器:分析客户端的请求,执行相应的动作,然后,向客户端回发响应消息。
有时,服务器与客户端之间可能需要就一次服务而进行多次交互。
客户端应用通常与用户打交道,而服务器应用则提供对某些共享资源的访问。一般说来,都是众多客户端进程与为数不多的一个或几个服务器端进程进行通信。
客户端和服务器既可以驻留于同一台计算机上,也可以位于联网的不同计算机上。客户端和服务器使用2.10节所讨论的IPC机制来实现彼此通信。
服务器可以提供各种服务,如下所示。
- 提供对数据库或其他共享信息资源的访问。
- 提供对远程文件的跨网访问。
- 对某些商业逻辑进行封装。
- 提供对共享硬件资源的访问(比如,打印机)。
- 提供WWW服务。
将某项服务封装于单独的服务器应用中,这一做法原因很多,举例如下。
- 效率:较之于在本地的每台计算上提供相同资源,在服务器应用管理之下提供资源的一份实例,则要节约许多。
- 控制、协调和安全:由于资源(尤其是信息资源)的统一存放,服务器既可以协调对资源的访问(例如,两个客户端不能同时更新同一信息),还可以保护资源安全,令其只对特定客户端开放。
- 在异构环境中运行:在网络中,客户端和服务器应用所运行的硬件平台和操作系统可以不同。
18 实时性
实时性应用程序是指那些需要对输入做出及时响应的程序。此类输入往往来自于外接的传感器或某些专门的输入设备,而输出则会去控制外接硬件。具有实时性需求的应用程序示例包括自动化装配流水线、银行ATM机,以及飞机导航系统等。
虽然许多实时性应用程序都要求对输入做出快速响应,但决定性因素却在于要在事件触发后的一定时限内,保证响应的交付。
要提供实时响应,特别是在短时间内加以响应,就需要底层操作系统的支持。由于实时响应的需求与多用户分时操作系统的需求存在冲突,大多数操作系统“天生”并不提供这样的支持。虽然已经设计出不少实时性的UNIX变体,但传统的UNIX实现都不是实时操作系统。Linux的实时性变体也早已诞生,而近期的Linux内核正转向对实时性应用原生而全面的支持。
为支持实时性应用,POSIX.1b定义了多个POSIX.1扩展,其中包括异步I/O、共享内存、内存映射文件、内存锁定、实时性时钟和定时器、备选调度策略、实时性信号、消息队列,以及信号量等。虽然这些扩展还不具备严格意义上的“实时性”,但当今的大多数UNIX实现都支持上面提到的全部或部分扩展(本书将讲解Linux所支持的POSIX.1b特性)。
本书会以术语“真实时间(real time)”来指代日历时间或经历时间的概念,而术语“实时性(realtime)”则是指操作系统或应用程序具备本节所述的响应能力。
19 /proc文件系统
类似于其他的几种UNIX实现,Linux也提供了/proc文件系统,由一组目录和文件组成,装配(mount)于/proc目录下。
/proc文件系统是一种虚拟文件系统,以文件系统目录和文件形式,提供一个指向内核数据结构的接口。这为查看和改变各种系统属性开启了方便之门。此外,还能通过一组以/ proc/PID形式命名的目录(PID即进程ID)查看系统中运行各进程的相关信息。
通常,/proc目录下的文件内容都采取人类可读的文本形式,shell脚本也能对其进行解析。程序可以打开、读取和写入/proc目录下的既定文件。大多数情况下,只有特权级进程才能修改/proc目录下的文件内容。
本书在讲解各种Linux编程接口的同时,也会对相关的/proc文件进行介绍。12.1节将就该文件系统的总体信息做进一步介绍。尚无任何标准对/proc文件系统进行过规范,书中与该文件系统相关的细节均为Linux专有。
UNIX/Linux书籍推荐
UNIX环境高级编程 第3版

20多年来,严谨的C程序员都是依靠一本书来深入了解驱动UNIX和Linux内核的编程接口的实用知识的,这本书就是W. Richard Stevens所著的《UNIX环境高级编程》。现在,Stevens的同事Stephen Rago彻底更新了这本经典著作。
这一版涵盖了70多个新接口,包括POSIX异步I/O、旋转锁、屏障(barrier)和POSIX信号量。此外,这一版删除了许多过时的接口,保留了一些广泛使用的接口。书中几乎所有实例都已经在主流的4个平台上测试过,包括Solaris 10、Mac OS X 10.6.8(Darwin 10.8.0)、Free-BSD 8.0和Ubuntu 12.04(基于Linux 3.2)。
与前两版一样,读者仍可以通过实例学习,这些实例包括了1万多行可下载的ISO C源代码,书中通过简明但完整的程序阐述了400多个系统调用和函数,清楚地说明它们的用法、参数和返回值。为了使读者能融会贯通,书中还提供了几个贯穿整章的案例,每个案例都根据现在的技术环境进行了全面更新。
本书帮助几代程序员写出了可靠、强大、高性能的代码。第3版根据当今主流系统进行更新,更具实用价值。
UNIX网络编程 卷1 套接字联网API 第3版

这是一部传世之作!网络编程专家Bill Fenner和Andrew M.Rudoff 应邀执笔,对W.RichardStevens 的作品进行修订。书中吸纳了近几年网络技术的发展,增添了IPv6、SCTP 协议和密钥管理套接字等内容,深入讨论了关键标准、实现和技术。
书中的所有示例都是在UNIX 系统上测试通过的真实的、可运行的代码,继承了Stevens 一直强调的理念:“学习网络编程的*好方法就是下载这些程序,对其进行修改和改进,只有这样实际编写代码才能深入理解有关概念和方法。”
本书为UNIX 网络编程提供全面的指导,是网络研究和开发人员公认的必不可少的参考书,无论网络编程的初学者还是网络专家都会大受裨益。
UNIX网络编程 卷2 进程间通信 第2版

本书是一部UNIX 网络编程的经典之作!进程间通信(IPC)几乎是所有Unix 程序性能的关键,理解IPC 也是理解如何开发不同主机间网络应用程序的必要条件。本书从对Posix IPC 和System V IPC 的内部结构开始讨论,全面深入地介绍了4 种IPC 形式:消息传递(管道、FIFO、消息队列)、同步(互斥锁、条件变量、读写锁、文件与记录锁、信号量)、共享内存(匿名共享内存、具名共享内存)及远程过程调用(Solaris门、Sun RPC)。附录中给出了测量各种IPC 形式性能的方法。
Linux命令行大全 第2版

本书对Linux命令行进行详细的介绍,全书内容包括4个部分,第一部分由Shell的介绍开启命令行基础知识的学习之旅;第二部分讲述配置文件的编辑,如何通过命令行控制计算机;第三部分探讨常见的任务与必备工具;第四部分全面介绍Shell编程,读者可通过动手编写Shell脚本掌握Linux命令的应用,从而实现常见计算任务的自动化。通过阅读本书,读者将对Linux命令有更加深入的理解,并且可以将其应用到实际的工作中。
本书适合Linux初学人员、Linux系统管理人员及Linux爱好者阅读。
鸟哥的Linux私房菜 基础学习篇 第四版

本书是知名度颇高的Linux入门书《鸟哥的Linux私房菜基础学习篇》的新版,全面而详细地介绍了Linux操作系统。
全书分为五部分:第一部分着重说明计算机的基础知识、Linux的学习方法,如何规划和安装Linux主机以及CentOS 7.x的安装、登录与求助方法;第二部分介绍Linux的文件系统、文件、目录与磁盘的管理;第三部分介绍文字模式接口shell和管理系统的好帮手shell脚本,另外还介绍了文字编辑器vi和vim的使用方法;第四部分介绍了对于系统安全非常重要的Linux账号的管理、磁盘配额、高级文件系统管理、计划任务以及进程管理;第五部分介绍了系统管理员(root)的管理事项,如了解系统运行状况、系统服务,针对登录文件进行解析,对系统进行备份以及核心的管理等。
本书内容丰富全面,基本概念的讲解非常细致,深入浅出。各种功能和命令的介绍,都配以大量的实例操作和详尽的解析。本书是初学者学习Linux不可多得的一本入门好书。
Linux就该这么学(第2版)

《Linux就该这么学(第2版)》源自日均访问量近60000次的线上同名课程,口碑与影响力俱佳,旨在打造简单易学且实用性强的轻量级Linux入门教程。
《Linux就该这么学(第2版)》在上一版的基础上进行了大量的更新,基于红帽RHEL 8系统编写,且内容适用于CentOS、Fedora等系统。
本书共分为20章,内容涵盖了部署Linux系统,常用的Linux命令,与文件读写操作有关的技术,使用Vim编辑器编写和修改配置文件,用户身份与文件权限的设置,硬盘设备分区、格式化以及挂载等操作,部署RAID磁盘阵列和LVM,firewalld防火墙与iptables防火墙的区别和配置,使用ssh服务管理远程主机,使用Apache服务部署静态网站,使用vsftpd服务传输文件,使用Samba或NFS实现文件共享,使用BIND提供域名解析服务,使用DHCP动态管理主机地址,使用Postfix与Dovecot部署邮件系统,使用Ansible服务实现自动化运维,使用iSCSI服务部署网络存储,使用MariaDB数据库管理系统,使用PXE+Kickstart无人值守安装服务,使用LNMP架构部署动态网站环境等。此外,本书的配套站点还深度点评了红帽RHCSA、RHCE、RHCA认证,方便读者备考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号