
什么是形式化验证?
1. 什么是形式化验证
FV(formal verification)是指使用数学工具分析设计可能行为的空间,而不是计算特定值的结果。FV工具将着眼于所有可能的仿真,而不是尝试特定的值。当然,它并不是真的运行所有可能的仿真,但它将使用数学技术来考虑所有可能的行为。仿真和FV的区别:仿真着眼于可能测试空间中的单个点,而FV同时覆盖整个空间。
FV不再仅仅是寻找稀有的bug。当我们探索各种可用的技术时,我们将看到,FV确实应该被看作是一个通用的工具包,用于交互、验证和理解我们的设计。从早期开发开始到post-silicon调试过程,在每个设计阶段适当地利用formal方法可以增加吞吐量,增加设计信心,并减少上市时间。
2. FV的种类和适用范围
根据形式验证提供的基本功能的种类,有几种方法可以查看它,还有许多将FV方法插入设计的特定技术。我们首先看看FV的一般动机和用例,然后更具体地讨论它在何处适合于实际的设计和验证。
3.1FV的整体优势
在讨论特定的应用程序或使用模型之前,您可能会看到,分析RTL行为的数学空间比传统的模拟、仿真或其他验证流有许多优点。FV方法的一般优点有:
- 解决正确的问题:虽然这对于注重实践的工程师来说可能过于哲学化,但你有多少次问过自己:我们应该如何验证我们设计的正确性?许多人会争论说,理想的方法是用数学证明符合它们的规格。我们对模拟和仿真等较弱工具的容忍是技术限制的不幸后果,随着这些限制现在逐渐减少,我们应该尽可能地摆脱这些较老的方法。
- 完全覆盖:如果我们将“覆盖率”定义为分析的可能设计行为的比例,那么FV天生就提供了完全的覆盖率。完美的FV并不可能适用于所有的设计——稍后我们将讨论一些由于容量和限制而产生的限制——但FV方法仍然提供了行为空间的某些子集的完全覆盖,相当于运行指数数量的仿真测试。
- 最小的例子:大多数FV引擎本身都能够生成所需行为的最小示例。在重置后的10个循环中可能会出现罕见的行为,但在典型的随机仿真环境中,它会在数千个循环的随机运行中显示出来。一个FV工具通常会生成最少的10个周期的示例,使它更容易理解和调试罕见的行为。
- 极端case :对于FV,任何没有明确排除的行为都是允许的,这意味着FV工具很有可能发现用户没有想到的极端情况,例如耗费英特尔很多钱的罕见的FDIV错误。与此形成对比的是,在仿真中,用户需要指定允许哪种类型的输入模式,这通常会导致隐式的限制,而用户可能并不完全意识到这些限制。
- 状态驱动和输出驱动分析:因为FV允许在设计的任何点约束逻辑的行为,包括内部状态或输出,它使我们能够推理设计的行为,这些行为能够或不能导致感兴趣的特定状态或输出。这是与仿真的另一个主要对比,仿真需要主动驱动的输入来达到任何设计状态。
- 理解无限的行为:有了FV,数学推理的力量使我们能够在无界时间段内提出和回答有关模型行为的问题。例如,我们可以提出这样的问题:一个模型是否会永远停留在没有达到预期的状态,或者它是否能够保证最终执行某些在有限时间内无法保证的行为。这些问题不能通过仿真等技术有效地解决。
3.2 FV的一般使用模型
基于上述的总体优势,在实际设计和验证流程中有几种常用的FV方法。它可以用于实现完全覆盖,确保检查所有可能的情况,以防止诸如Pentium FDIV错误之类的问题。它可以用于寻找漏洞,在完全FV不可行的情况下,为设计中的某些特定风险区域提供可靠的覆盖。它还可以用于设计探索,使用数学分析的力量来帮助更好地理解RTL行为。
3.3 完全覆盖的FV
当您想要获得设计行为的完整覆盖时,可以考虑使用FV作为您的主要验证方法。
为了进一步理解FV方法的内在能力,让我们花点时间考虑一个简单的设计验证问题:一个有两个32位输入的加法器,如图1.4所示。
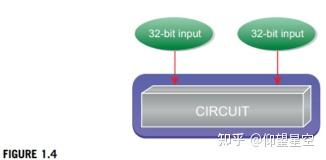
要完全验证此设计的所有可能输入,我们需要仿真总共2^64种可能的组合。如果你有一个超快的模拟器,可以模拟每秒2^20周期(这比当前大多数模拟器的实际速度快得多),这意味着你需要2^44秒,或者超过50万年的时间来检查所有可能的值。最有可能的是,你的经理没有为你当前的项目分配这么多时间。这还没有考虑到在多个周期内测试顺序行为,而在任何实际设计中,都可能需要测试顺序行为。因此,我们可以看到,在我们想要真正全面的设计覆盖的情况下,需要比模拟更强大的东西。
3.3.1 FV用于寻找Bug
当您有一个具有重要逻辑设计,并且担心您将不能通过仿真测试获得足够的覆盖率时,考虑将FV作为仿真的补充。
设计的完整FV并不总是可能的。可能存在与形式分析不兼容的模拟逻辑或其他设计方法组成的部件。由于逻辑的样式或大小,复杂性限制可能使完全的FV不可行。在这些情况下,仿真不能完全替代。
然而,对于FV有效的设计子集,该方法将提供指数级的比仅通过仿真可以获得的更多的覆盖。因此,作为仿真的补充,FV仍然是一种有价值的方法,可以发现潜在的错误,否则可能会错过。
3.3.2探索设计的FV
如果您有一个设计,可以很容易地指定感兴趣的状态或输出,但指定所需的输入序列非常困难或耗时,那么可以考虑使用FV。
FV的另一个主要用途是作为探索RTL设计行为的工具。FV工具能够分析潜在的仿真空间,并根据您希望看到的状态或输出的规范,找出产生特定行为的方法。这可以看作是逆向工程的一种形式:您不需要知道什么设计活动可以产生您所请求的给定状态,但是FV工具将为您找出这一点。例如,你可以提供这样的查询:“是否有任何输入集合,将从我的加法器给出一个32'ffffffff的值?”,而FV可以找出是否存在一些理论上可能的输入序列,让你达到目标。
这与基于期望状态或输出回答问题的仿真相比,您需要以某种方式指定需要哪些输入来产生期望的情况,或者运行大量随机仿真并希望获得期望结果。在这个简单的例子中,直接找出所需的输入可能在您的数学技能范围内,但有许多常见的设计类型,其中输入在多个周期中作为较小的或编码的片段传递,而且,要找出一个精确的仿真输入序列来得到你想要的结果可能是不可行的。使用FV工具将您从这种负担中解放出来,因为它将检查可能的仿真空间,并确定一个将得到您想要的结果或证明它是不可能的。换句话说,当使用FV设计测试时,您可以指定目标而不是过程。
3.3.3真实设计流程中的FV
基于上述方法,有一些特定的技术已经开发,使用现代EDA工具,以利用FV贯穿SOC设计流程。图1.5说明了超大规模集成电路设计流程的主要阶段,以及我们所描述的FV方法所适用的阶段。
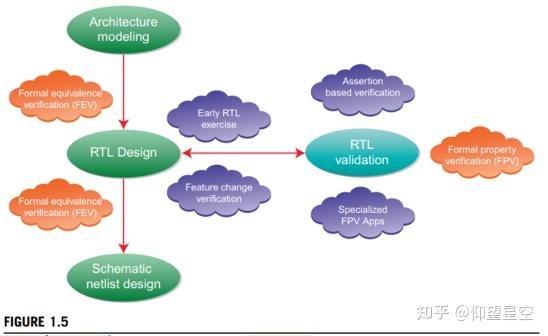
- Assertion-Based Verification (ABV):这就是使用断言(通常用SVA等语言表示)来描述RTL必须正确的属性。在某些情况下,属性可以完全描述设计的规格说明。使用ABV本身并不能保证你做的是真正的FV,因为在仿真中也可以检查断言,事实上,在当今行业中,ABV的使用占了大部分。然而,ABV是实现FV的关键组成部分。
- Formal Property Verification (FPV):使用formal工具来证明断言。FPV是一种非常普遍的技术,可以进一步细分为许多额外的技术:
- Early Design Exercise FPV: 这是指利用FPV的分析能力,在早期阶段分析RTL,以帮助了解最初的功能并发现早期的错误。
- Full Proof FPV:这是典型的使用FPV来代替仿真和验证RTL模型是否正确地实现了它的规范(通常描述为一组断言)。
- Bug Hunting FPV:这是指在不可能完全验证设计的情况下,使用FPV来补充仿真。它仍然是一种非常强大的技术,可以找到罕见的极端情况bug,并获得比仿真更大的理论覆盖率。
- Unreachable Coverage Elimination:如果您的主要验证方法是仿真,那么项目中经常会出现一些目标覆盖状态或代码行没有达到的情况,验证团队正在努力弄清楚它们是否是可测试的。FPV可以用来识别设计的可达和不可达的状态和区域。
- Specialized FPV Apps:这指的是应用于特定问题的FPV,例如验证对已知协议的遵守,确保正确的SOC连接,确保正确的控制寄存器实现,以及发现post-silicon缺陷。在每一种情况下,注意特定问题的特征可以提高所涉及的FPV的生产率。
- Formal Equivalence Verification (FEV):这是指使用formal技术来比较两个模型,并确定它们是否等价。每个模型可能是高级模型、RTL或示意图,或者这可能涉及到两个抽象级别之间的比较。
- Schematic FV. 这是指使用FEV来检查由合成或在晶体管级手绘的原理图网表是否正确地实现了它的RTL。早在20世纪90年代,这是第一种具有商业可行性的FEV,它是强大的综合工具崛起的关键推动者。现在几乎每个公司都在使用这种技术,即使他们一般不做太多的FV。
- Feature Change Verification. 随着现有RTL模型在SOC设计中重用的增加,在很多情况下,RTL的一部分有望继续用于当前定义的功能,但代码已经被修改或更改以适应新的用例。还有一些非功能更改的情况,我们希望在更改模型以修复时序或其他问题时功能保持完全相同。FEV可以用来比较RTL的两个部分,关闭任何新功能,并确保以前现有的使用模式将继续工作。
- High-Level Model Equivalence Verification. 这指的是高级模型(例如设计的一般功能的System C模型)与RTL模型的比较。这种比较涉及很多挑战,因为高级模型比RTL要抽象得多。
3.4 没有讨论的FV方法
还有许多其他有趣而强大的FV方法,它们被认为是新的和实验性的,或者主要是由学术技术实现的,还没有达到得到商业工具良好支持的程度。我们并不反对使用这些类别中的任何一种工具---事实上,其中一些已经在英特尔得到了广泛的应用,并取得了巨大的成功。但是,由于它们的新特性、对专业软件的需求,或者缺乏商业EDA支持。
- Assertion Synthesis. 这是指自动创建断言的概念,而不是要求用户编写断言。断言可以来自RTL本身,也可以来自仿真运行,或者两者的组合。这一领域在过去几年中刚刚出现,关于它的整体价值和最佳使用模式仍有很多争论,这就是为什么我们在本书中将其排除在外。
- Smart Linting. 这是最简单的断言综合类型,尝试在编译时创建rtl派生的属性,然后使用轻量级FPV立即验证。例如,智能检测工具可能试图证明所有数组访问都在声明的范围内。从技术上讲,我们可以在FPV一节中讨论这个问题,因为它是由一些商业工具以一种按下按钮的方式提供的,但是我们忽略了这个方法,因为我们没有看到它在我们的项目中展示明显的ROI。
- Structural Assertion Synthesis. 这是一种稍微复杂一点的智能检测形式,其中断言是为无法在编译时形式证明的条件生成的。它们可能需要额外的用户约束或更高级的FPV技术来正确证明或针对仿真时间检查。
- Behavioral Assertion Synthesis. 这种方法使用来自真实仿真测试的仿真痕迹,这些仿真轨迹可能是由已知模型的真实行为的验证者编写的,从而得出断言。通常这些对于未来的验证计划(包括FV和仿真)都是有用的,或者对于指出项目测试套件中的覆盖漏洞也是有用的。
- Symbolic Simulation. 符号仿真通过仿真变量和0/1值以及推导电路执行结果的布尔表达式的能力来增强仿真的基本概念。在某些方面,它可以被认为是实现FPV的另一种技术。这种方法的一种高级形式称为符号轨迹计算(STE),在英特尔公司被大量用于验证复杂的数据路径操作,如浮点数学。不幸的是,目前没有任何主要的商业EDA工具提供STE能力;英特尔的使用都是基于内部开发的非公共工具。有一些学术性的STE工具可以下载,但是在工业环境中很难使用。因此,在本书中描述它可能对一个不在英特尔工作的实践工程师没有什么用处。
- High-Level Modeling and Verification. 这是在一些比RTL更抽象的语言中建模的思想,例如System C、TLA、Murphi或PROMELA使用模型检查或定理证明工具来验证这些模型。同样,这些强大的技术已经在Intel得到了成功的应用,它们是基于应用学术或定制设计工具的专家,但它们也缺乏良好的商业EDA支持。
- Software FV. 能够formal验证软件一直是研究人员的一个目标,但是由于软件工程中高级和抽象技术的普及,在这个领域中良好的商业工具已经被证明是一个难以实现的目标。这仍然是FV技术发展的一个有希望的领域,但是由于我们关注的是硬件设计,这在很大程度上超出了作者的专业范围。
上面的列表并非详尽无遗;在学术界,形式验证仍然是一个活跃的研究领域,关于FV有趣的新用法的假设和先驱不断出现。
4.实用FV的出现
许多年来,现代数学的形式方面,即从现有的定理和公理中以明确定义的方式推导出新的定理,自然地导致数学家和科学家们对他们学科的自动化部分进行推测。既然数学在理想情况下是完全形式化的,那么为什么某种机器不能在没有人类干预的情况下进行自动推理,推导出新的有趣的定理呢?从某种意义上说,从17世纪莱布尼茨关于一种普遍特征的推测开始,这种自动化已经梦想了300多年。20世纪现代计算机系统的发展将这些梦想带到了现实领域。
4.1早期的自动推理
第一个重要的自动推理计算机程序是1956年出现。它试图从基本公理中自动推导出基本的数学定理,在某些情况下,它生成的证明被认为比现有的顶尖数学家手工编写的证明更优雅。纽厄尔、西蒙和肖的工作启发了一代人工智能和自动推理领域的研究人员,他们的想法和方法太多了,在这里无法讨论。最初,有人乐观地预言,逻辑理论家是全面通用、通用型人工智能不可避免崛起的开端,很快我们每个人的办公桌上都会有一个机器人朋友,帮助我们解决任何困难的逻辑问题。但研究人员逐渐意识到,至少在短期内,专注于特定领域的系统要比瞄准完全通用的自动推理要好得多。
4.2计算机科学应用
学术研究人员在20世纪60年代开始讨论自动解决特定的计算机科学问题,开始于R. W. Floyd和C. A. R. Hoare关于验证“部分正确性”和“完全正确性”的开创性工作,这是计算机程序的基本属性类型。这在整个20世纪70年代引发了学术兴趣和后续研究,但不幸的是,这些技术在很大程度上被认为还不足以在工业上支持任何形式的实际应用。在20世纪80年代,这项工作导致了模型检查的发展,而模型检查是本书中技术建立的基础。基本思想是,给定一个有限状态机和一个时态逻辑规范,我们可以使用有效的算法或启发式来建立机器符合规范。早期的定理证明方法要求用户通过证明一步一步地引导自动推理,而模型检查则是一种自动化得多的技术,一旦提供了模型和约束条件,系统就会自己提出证明或反例。
最初,这种方法很有希望,但由于状态爆炸问题,在工业上并不实用:正如我们在图1.4的例子中所看到的,系统中即使是少量的输入也会迅速爆炸成指数数量的组合。有一段时间,在一个经过验证的系统中,对状态数量的统计成为了该领域研究质量的重要衡量标准,因为模型检查软件在实用价值的边缘摇摇晃晃。20世纪90年代初,当其中一位作者埃里克(Erik)还在卡内基梅隆大学的研究生院时,模型核查的基础研究员之一埃德·克拉克(Ed Clarke)因其神秘的声明在当地研究生中臭名昭著,比如“我们今天验证了10^50个状态!”不擅长这方面的学生开始称他为“the guy with the states ”。但是研究人员在整个20世纪80年代继续改进现有的算法和启发式。
4.3模型检查变得实用
在20世纪90年代早期,这些工具终于开始被真正开发微处理器的公司所利用,这是由于诸如使用被称为二进制决策图(BDDs)的高效数据表示之类的进步。模型检查的真正成功开始被报道,例如,当Clarke的学生Ken McMillan使用BDDs模型检查发现IEEE Futurebus 标准的一个微妙的bug。
当英特尔FDIV bug在1994年成为一个主要的公众问题时,处理器设计公司开始密切关注使用新的受人尊敬的FV方法来改进他们的验证过程的机会。首先,他们需要雇佣研究人员来开发内部工具,因为EDA市场上没有真正的FV选项。在接下来的几十年里,各种各样的创业公司开始出现,销售不同类型的formal技术,这些技术在实践中变得越来越有用和有效。
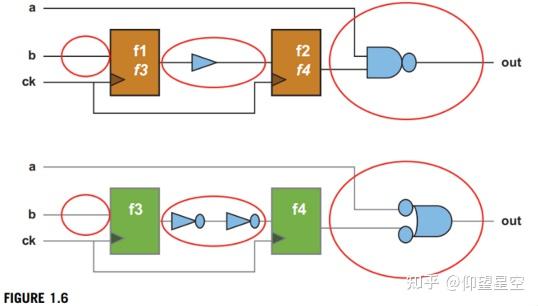
第一种实现商业可行性的FV是在schematic FV中使用FEV,验证schematic netlists与他们的RTL模型相匹配。这是一个比一般的FV更容易处理的问题,因为按照惯例,要根据RTL模型进行示意图状态匹配:RTL中的每一个锁存器或触发器,在原理图中都有一个对应的锁存器或触发器。因此,验证可以将模型分解成小的、可管理的块,每一对状态元素之间的逻辑,或“关键点”(见图1.6)。
逐渐地,实用的FPV工具出现了。这些工具发现更普遍的问题,检查RTL模型是否与规范匹配,这可能不一定是状态匹配,因此需要复杂的时间推理。新的自动启发式的不断发展也将这种方法带入了实用领域。
今天,您可以购买现成的EDA工具,并有效地使用它在整个SOC设计流程中与RTL进行交互、理解和验证。
4.4 断言的标准化
在过去十年左右的时间里,使FV特别实用的另一个发展是属性描述语言的标准化。FV工具在21世纪初或更早的时候通常提供了自己独特的语言来指定属性。每个工具都有一些“很好的理由”来解释为什么它的语言优于其他工具,并且有一些formal的论据来说明它们的定制语言的有用的数学特性。然而,所有这些分歧的最终结果是,尝试一个新的或不熟悉的工具非常困难。此外,它将用法限制在有耐心学习一组新的指令的专家。此外,许多早期的属性语言是由研究人员和数学家设计的,并没有表现出对用于RTL设计模型的真正工程师有用的表达风格的意识。
摆脱这种情况的第一丝希望始于2001年的Accelera的开放验证库(Open Verification Library, OVL),这是一组可以在任何设计语言中定义为模块/实体的标准断言。虽然它们没有提供太多的灵活性,但它们具有接受任意布尔输入的能力, 这在很大程度上弥补了这种限制。因为它是标准的,并且有在所有主要设计语言(VHDL,Verilog 2001, SystemVerilog),它在设计界变得相当流行,尽管它有其局限性。也有一些并行的努力来标准化其他属性语言,最突出的是属性规范语言(PSL)。
从2005年开始,OVL和PSL开始被一种新的断言语言所包含,这种语言试图平衡对数学可靠性和工程实用性的关注:与OVL相比,SVA提供了一种更灵活的方式来指定各种各样的断言,我们将在第3章中看到。OVL并没有完全消失:OVL的SVA实现是可用的,因此那些更熟悉这些粗粒度断言的用户仍然可以使用它们。然而,SVA已经成为描述FV属性的公认标准,目前任何正规的工具都希望支持该语言。
5.实现FV的挑战
如果FV真的像我们在本章中声称的那样强大,为什么不是每个人都在使用它呢?作为任何关于FV的实际讨论的一部分,指出一些限制也是很重要的,这些限制使得广泛部署FV变得有点困难。
5.1数学的基本局限
你可能会模糊地记得一些大学教授告诉你一些20世纪上半叶的重大发现,这些发现表明,可以用数学证明的东西是有基本限度的。例如,不完全性定理表明,任何至少像基本算法那样复杂的形式系统要么是不一致的,要么是不完整的。他通过证明,在这样一个系统中,人们总是可以构造出令人费解但又不太自相矛盾的说法:“这个说法不能被证明。”想想看:如果它是假的,那么它可以被证明,而系统是不一致的,允许对假陈述的证明。如果它是真的,那么我们就得到了一个真实且无法证明的陈述,表明了系统的不完全性。艾伦·图灵(Alan Turing)在理论计算机科学领域也得出了类似的结果,他指出,要生成一个通用的计算机程序来确定地告诉你其他程序最终会停止运行还是会永远运行,这是不可能的。
虽然这些结果在理论上很有趣,但它们真正向我们展示的是,在FV领域,不能开发出一种能够正式证明任何规范正确性的通用工具。它们并不排除开发实用工具,这些工具可以在定义良好的语言中处理绝大多数有限的现实规范。
5.2理论复杂性
除了从根本上问什么是可以计算或不能计算的,计算机科学家还问了另一个问题:对于可以计算的答案,需要多少时间或内存?复杂性理论的子领域试图通过根据问题的难解程度将问题划分为不同的复杂性类别来回答这个问题。FV的核心问题之一是可满足性(satissatisability, SAT)问题
布尔表达式,是否有一些变量的值会使它的值为1? 例如,考虑下面的布尔表达式:
(a&b&c) | (a&!b&d) | (c&d&e) | (!e&a&b)
如果问是否有一组值的变量a, b, c, d, e,这将导致这个表达式来评估1,没有简单的方法来回答这个问题, 除了尝试所有的组合值。但如果有人给了你一套他们声称有效的值,那就很容易把它们替换掉并验证它。
1971年,库克的定理表明,这个问题SAT属于一类被称为np-complete可证明难题。这意味着数学家们通常认为,解决这个问题的时间与输入集的大小呈指数关系。指数时间意味着绑定表达式包含n的指数,如(2^n)或(7^3n +5^n+1)。特别小的n值这可能不是那么糟糕,但如果你尝试用一些你会发现随着n值增大,指数时间会很快失控。在实践中,如果一个问题是np-complete的,这意味着一个程序不能在所有可能的情况下在合理的时间内解决它。
5.3好的消息
事实上,上述所有问题都表明,FV是一个工程挑战。我们永远不可能实现一个100%保证在100%的RTL设计中都能运行良好的FV系统,但有多少工程领域能给我们提供这样的保证呢?他们所做的表明,关于FV工具的使用:解决问题的策略对某些情况子集有效,但不保证对每个情况都有效。
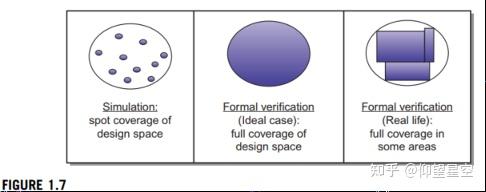
即使在FV只适用于设计子集的情况下,我们通常会发现的部分都是适用的,它相当于一个指数的运行仿真测试,验证空间的完全覆盖一个巨大的子集,即使不能达到理想的完全覆盖。图1.7说明了这种情况。
因此,我们所提到的复杂性挑战并没有超过FV技术的内在力量和许多好处。正如您在本书中看到的,当前的FV工具有效地结合了一组强大的启发式方法来解决我们在RTL设计中每天遇到的实际验证问题,并且日益强大。
6. 放大formal的力量
在过去的20年里,研究已经产生了各种各样的启发式方法来攻击SAT和类似的问题,这就是为什么我们今天能够使用现成的EDA工具并使用它来分析典型的超大规模集成电路设计的主要原因。现在,使用现成的FPV工具,加载一个真正的单元或集群级RTL设计,并能够立即进行形式化分析是很常见的。
然而,由于我们使用的是启发式方法,您可能会遇到这样的情况:您想要在比工具的初始按钮容量更大的设计上运行FV。一旦您熟悉了该技术的基础知识,您就会发现,使用各种技巧可以使看似困难的问题变得容易处理,这是相对容易的。以下是我们在准备具有挑战性的FV设计时使用的一些通用技术:
- State Matching: 大多数当前的综合工具生成的原理图都是(大部分)保证与生成它们的RTL有一个逐触发器的对应关系。因此,当做形式等价检查之间RTL和netlists,我们可以利用我们对这两种设计中相应的失败的知识来简化问题。
- Bounded Proofs: 与证明设计保证始终具有正确的行为不同,您可以证明在一定长度的行为跟踪中,所有行为都保证是正确的。虽然这并不像保证功能的完整证明那样强大,但它仍然相当于运行指数数量的仿真测试。因此,它在实践中往往是非常有用的。
- Proof Decomposition 我们通常可以通过使每个属性尽可能简单来显著提高我们的FV能力。例如,“(a或B)暗示C”形式的属性可以被分为两个独立的属性"A意味着C " 和" B意味着C "
- Targeted Verification 您主要担心的是一些小的危险情况吗?比如当队列快要满了或者协议快要完成时,会发生什么情况?您可以引导该工具集中于问题空间的特定部分。
- Size Reductions 通常,我们可以只表示大内存或缓存的一小部分,将数据路径宽度减少到几个位,或减少参数化元素的大小,但仍然可以以一种能够捕捉到绝大多数bug的方式分析我们的设计。
- Case Splitting 对于一个有许多模式或操作码的设计,我们需要一次验证它们吗?我们通常可以将作业分成若干个简单的验证任务,每个任务检查一个可能行为的子集。
- Design Abstractions 在验证整体设计的属性时,我们常常会忽略计算的细节。例如,计数器是否真的需要在每个循环中精确地递增1,或者其他逻辑是否只关心在每个循环中生成真实的值?
- Data Abstractions 也许我们不需要完全分析一般的数据模式,而是可以指定可能数据的一个简化子集,例如大多数数据位为0,或者所有数据包都是一小组类型中的一种。
参考书:Formal_Verification_An_Essential_Toolkit_for_Modern_VLSI_Design

 浙公网安备 33010602011771号
浙公网安备 33010602011771号