腾讯游戏安全技术比赛2021机器学习方向参赛体会
比赛官网:
https://gslab.qq.com/html/competition/2021/index.htm
(初决赛题目一样,只是多了一些提示)
先说结果,得奖和我无关。
第一次尝试打这类比赛,试试水,报了机器学习方向。
初见赛题
放出题那天,数据足足8个G,我用了Motrix玩命下载,慢慢等它解压,发现数据总共60多G!

训练集67.6GB,哭了
还好比赛时间是3天。
如何处理大数据
但是读取数据上就有问题。
赛题给了个例子,关于某用户某次击杀的前600帧的数据,可以进行deltaX一阶差分处理。
但是打开那60G的数据的前一万行,我发现数据是乱序的,想要找到每个用户每次击杀的每600帧数据,真的是难上加难!
咋办?难不成排序?
我还真的尝试了一下,内存炸满,最后无疾而终。所以排序根本行不通。
所以应该怎么处理?
对用户进行分类
其实是有办法的。
分块读入数据,分析每条数据,找出属于哪个用户,直接保存到磁盘里。
这样顺序读一遍下来,可以按照用户把数据分成许多个txt文件,保存到磁盘上。
# 本代码按行读取,效率极低,建议改成一次读取10000行,再按行分析,提高速度
with open('data/训练集/cp_rawdata_0509.txt', 'r') as f:
data = f.readline()
#i = 0
while data:
data = data.split('|')
name = data[1]
path = r'data_split/' + name + '.txt'
with open(path, 'a') as f1:
f1.write(str(data))
f1.write('\n')
#if i % 100000 == 0:
# print(i)
#i += 1
data = f.readline()
这时候要注意一点,赛题给的用户的黑白名单并不完整。也就是说,训练集里的某些用户根本没有标签,这样的人就可以不进行处理,直接抛弃。
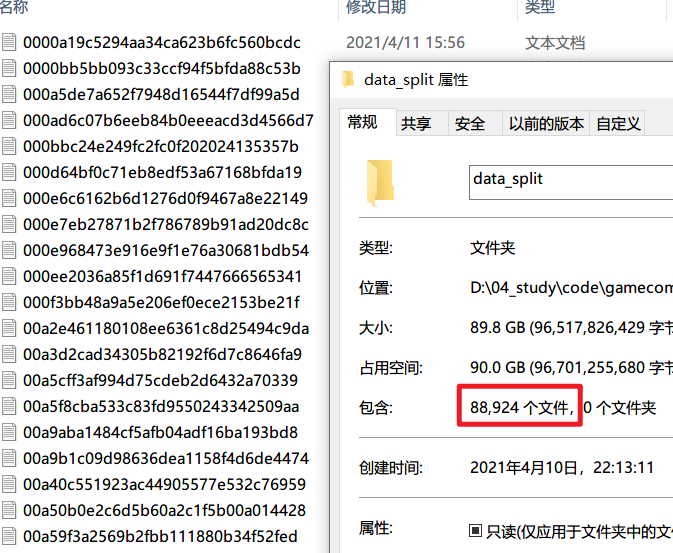
把数据集按照用户名分成若干个数据
分类后的用户就很简单了,最大的一个txt文件也就45.3MB,可以放心读取并且排序了。
ps:大数据下的代码调试
大数据处理时候,代码也许会有一些bug,但是数据过大,绝不可能把数据全部跑一边才发现是否有bug,所以调试代码时候,注意读的数据小一些,同时数据处理过程中,设定计数器,方便自己对程序运行有一个直观的把握。
或者可以使用jupyter notebook,可以对数据进行暂时存储。
尝试解决赛题的过程
特征工程
本次赛题是一个分类问题,判断用户是开了外挂还是没开外挂,0-1分类问题。
首先我们要对数据提取特征,也就是特征工程,选取和“开外挂”相关的特征。
类似于房价分析,房价和面积、位置等特征有关,预测房价的时候就需要对这些特征进行分类处理。
同样的,这次比赛也要对特征进行提取,之后再对特征送入模型进行训练。
由于我连结果都没跑出来,所以就不放出思路了。
模型
这里说的模型指的是分类器。我们有了这么多特征,如何分类?
一般常用的分类器比如XGBox,lightGBM。本次比赛可以尝试后者。
当模型训练好之后,再对验证集进行处理,获得结果。
个人心得
这一次比赛特别有意义,毕竟第一次参加,紧迫的时间也促进自己学习。此外,一定要多多参加比赛,才能成长地更快!
附录:特征工程的代码
# 对硬盘上已经划分好的txt文件进行读取并处理
# 该代码有bug,即最后保存到本地那一步出问题了
import numpy as np
import os
import json
import pandas as pd
import requests
feature_list = [] # 保存内容
target = []
feature_matrix = []
def get_feature(data_600, num_usr):
# 输入的是已经排好序的600帧数据
# 这个函数内容是我的特征工程,看上去比较杂乱
kill_time = data_600[:, 0]
deltaX = data_600[:, 3]
deltaY = data_600[:, 4]
button = data_600[:, 5]
pitch = data_600[:, 6]
yaw = data_600[:, 7]
type = data_600[:, 10]
weapon = data_600[:, 11]
deltaX_diff = np.diff(deltaX)
deltaX_diff_max = np.max(deltaX_diff)
num_weapon = np.sum(np.unique(weapon))
yaw_diff = np.diff(yaw)
pitch_diff = np.diff(pitch)
# kill_time sum 总和加一
kill_time_diff = np.diff(kill_time)
# 向feature_list添加内容
if len(feature_list[num_usr]) == 0: # 空的话,就填入
feature_list[num_usr].append(1)
feature_list[num_usr].append(deltaX_diff_max)
feature_list[num_usr].append(num_weapon)
feature_list[num_usr].append(set(w for w in np.unique(weapon)))
feature_list[num_usr].append(np.max(yaw_diff))
feature_list[num_usr].append(np.max(pitch_diff))
feature_list[num_usr].append(np.min(kill_time_diff))
feature_list[num_usr].append(np.extract(button >= 20, button).shape[0])
feature_list[num_usr].append(np.extract(type == 3, type).shape[0])
else: # 不空就部分叠加
feature_list[num_usr][0] += 1
feature_list[num_usr][1] = max(feature_list[num_usr][1], deltaX_diff_max)
feature_list[num_usr][2] += num_weapon
feature_list[num_usr][3].update(w for w in np.unique(weapon))
feature_list[num_usr][4] = max(feature_list[num_usr][4], np.max(yaw_diff))
feature_list[num_usr][5] = max(feature_list[num_usr][5], np.max(pitch_diff))
feature_list[num_usr][6] = min(feature_list[num_usr][6], np.min(kill_time_diff))
feature_list[num_usr][7] += np.extract(button >= 20, button).shape[0]
feature_list[num_usr][8] += np.extract(type == 3, type).shape[0]
def get_matrix(num_usr):
feature_matrix.append([])
feature_matrix[num_usr].append(feature_list[num_usr][0])
feature_matrix[num_usr].append(feature_list[num_usr][1])
feature_matrix[num_usr].append(feature_list[num_usr][2])
feature_matrix[num_usr].append(len(feature_list[num_usr][3]))
feature_matrix[num_usr].append(feature_list[num_usr][4])
feature_matrix[num_usr].append(feature_list[num_usr][5])
feature_matrix[num_usr].append(feature_list[num_usr][6])
feature_matrix[num_usr].append(feature_list[num_usr][7]/feature_list[num_usr][0])
feature_matrix[num_usr].append(feature_list[num_usr][8]/feature_list[num_usr][0])
if __name__ == "__main__":
np.set_printoptions(threshold=np.inf)
path = os.listdir(r'D:\04_study\code\gamecompetition\data_split')
with open('data/名单/训练集black_uin.txt', 'r') as f:
user_black = f.read().split()
with open('data/名单/训练集white_uin.txt', 'r') as f:
user_white = f.read().split()
for name in path: # 读取每一个用户的数据
usr = name[:-4] # 保存用户名称
usr_flag = 0
if usr in user_black: # 判断用户是否在名单里
target.append(1)
elif usr in user_white:
target.append(0)
else:
continue
data = 0
l = []
num_usr = 0
feature_list.append([])
# 提交内容
with open(r'D:\04_study\code\gamecompetition\data_split' + '\\' + name, 'r') as f:
data = f.read()
data = data.split('\n')
for i, d in enumerate(data):
d = d[1:-1].split(',')
l.append(d)
l = np.array(l[:-1])
l = l[:, 1:]
l = l[np.argsort(l[:, 2])] # 排序
# 提取每一行的内容,转成可识别的格式
for i, il in enumerate(l):
l[i][1] = il[1][2:-3]
l[i][2] = il[2][2:-3]
l[i][3] = il[3][2:-1]
l[i][4] = il[4][2:-1]
l[i][5] = il[5][2:-1]
l[i][6] = il[6][2:-1]
l[i][7] = il[7][2:-1]
l[i][8] = il[8][2:-1]
l[i][9] = il[9][2:-1]
l[i][10] = il[10][2:-1]
l[i][11] = il[11][2:-1]
l[i][12] = il[12][2:-3]
l = l[:, 1:].astype('float')
#print(l.shape)
num_line = l.shape[0]
for i in range(num_line // 600):
# 调用函数,每600帧处理一次
# 将结果保存到list中
get_feature(l[i * 600:(i + 1) * 600], num_usr)
# 将特征转换为特征矩阵,并保存到本地
get_matrix(num_usr)
num_usr += 1
# 最后将矩阵输出
np.savetxt('data/结果/feature.txt', np.array(feature_matrix),delimiter=',')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号