


声明:本程序仅用于学习爬网页数据,不可用于其它用途。
本程序仍有很多不足之处,请读者不吝赐教。
依赖:本程序依赖BeautifulSoup4和lxml,如需正确运行,请先安装。下面是代码:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 5 import sys 6 reload(sys) 7 sys.setdefaultencoding('utf-8') #解决编码问题 8 9 10 """一个简单的从豆瓣网获取电影标签的示例, 11 1. 首先获取所有标签以及它所对应的请求连接, 12 获取所有标签的请求链接是https://movie.douban.com/tag/?view=cloud 13 2. 请求每个标签对应的链接获取该标签下所有电影信息 14 """ 15 16 17 import urllib 18 import urllib2 19 import re 20 import codecs 21 # BeautifulSoup 用于解析html使用,本程序中使用lxml作为解析器 22 from bs4 import BeautifulSoup 23 24 25 # url正则表达式,用于将url分割为多个部分,对其中某些部分进行url编码使用 26 URL_RGX = re.compile(r'(?P<prefix>https?://)(?P<mid>[^?]+)(?P<has_key>\??)(?P<parms>[^?]*)') 27 DOUBAN_TAG_URL = r'https://movie.douban.com/tag/?view=cloud' 28 29 30 # url请求 31 def get_request(url): 32 # 对url特定部分进行编码 33 matches = URL_RGX.match(url) 34 if matches: 35 dic = matches.groupdict() 36 prefix = dic.get('prefix', '') 37 mid = urllib.quote(dic.get('mid', '')) 38 has_key = dic.get('has_key', '') 39 parms = dic.get('parms', '') 40 if parms != '': 41 tmp_dic = dict() 42 for kv in parms.split('&'): 43 k, v = kv, '' 44 if '=' in kv: 45 k, v = kv.split('=', 1) 46 tmp_dic[k] = v 47 parms = urllib.urlencode(tmp_dic) 48 url = '{0}{1}{2}{3}'.format(prefix, mid, has_key, parms) 49 else: 50 url = None 51 if url: 52 try: 53 res = urllib.urlopen(url) 54 if res and res.getcode() == 200: 55 return res.read() 56 except Exception as e: 57 pass 58 return '' 59 60 61 # 获取所有标签信息,返回值为列表,列表中每个元素格式为(标签名, 标签url地址) 62 def get_all_tags(): 63 all_tags = list() 64 page_text = get_request(DOUBAN_TAG_URL) 65 soup = BeautifulSoup(page_text, 'lxml') 66 tags = soup.find_all('a', attrs={'class': 'tag'}) 67 for tag in tags: 68 tag_name = tag.string 69 # 将原有链接中的?focus=替换为空,替换后url为分页显示地址 70 tag_url = tag['href'].replace('?focus=', '') 71 all_tags.append((tag_name, tag_url)) 72 return all_tags 73 74 75 # 解析单个电影节点信息,返回电影信息字典 76 def parse_movie_tag(movie_tag): 77 # 下面15行代码好烂,下次改下它 78 movie_title_tag = movie_tag.find('a', attrs={'class': 'title'}) 79 movie_title = '无名电影' 80 movie_detail_url = '无链接' 81 if movie_title_tag: 82 movie_title = movie_title_tag.string.strip() 83 movie_detail_url = movie_title_tag['href'].strip() 84 # movie_detail_url = movie_tag.find('a', attrs={'class': 'title'})['href'] 85 movie_desc_tag = movie_tag.find('div', attrs={'class': 'desc'}) 86 movie_desc = '无描述信息' 87 if movie_desc_tag: 88 movie_desc = movie_desc_tag.string.strip() 89 movie_rating_nums_tag = movie_tag.find('span', attrs={'class': 'rating_nums'}) 90 movie_rating_nums = '无评分信息' 91 if movie_rating_nums_tag: 92 movie_rating_nums = movie_rating_nums_tag.string.strip() 93 return {'title': movie_title, 'detail_url': movie_detail_url, 94 'desc': movie_desc, 'rating_nums': movie_rating_nums} 95 96 97 # 获取当前页面中的电影信息节点 98 def get_current_page_movies(page_url): 99 page_text = get_request(page_url) 100 soup = BeautifulSoup(page_text, 'lxml') 101 movies = soup.find_all('dd') 102 movie_info_lst = list() 103 for movie in movies: 104 # 将解析后的电影信息加入列表中 105 movie_info_lst.append(parse_movie_tag(movie)) 106 return movie_info_lst 107 108 109 if __name__ == '__main__': 110 # 获取所有标签信息 111 all_tags = get_all_tags() 112 # 标签信息存到文件中 113 all_tags_file = codecs.open('all_tags_info.txt', 'wb') 114 all_tags_file.write('标签名\t标签url地址\r\n') 115 for tag_name, tag_url in all_tags: 116 all_tags_file.write('{0}\t{1}\r\n'.format(tag_name, tag_url)) 117 all_tags_file.flush() 118 all_tags_file.close() 119 120 # 获取每个标签下的所有电影 121 for tag_name, tag_url in all_tags: 122 movie_infos_file = codecs.open(tag_name + '.txt', 'wb') 123 movie_infos_file.write('电影名\t标签名\t电影描述\t评分\t详细链接\r\n') 124 start = 0 125 while True: 126 target_url = '{base_url}?start={start}'.format(base_url=tag_url, 127 start=start) 128 movies = get_current_page_movies(target_url) 129 for movie in movies: 130 title = movie.get('title', '') 131 detail_url = movie.get('detail_url', '') 132 desc = movie.get('desc', '') 133 rating_nums = movie.get('rating_nums', '') 134 movie_infos_file.write('{0}\t{1}\t{2}\t{3}\t{4}\r\n'.format(title, 135 tag_name, 136 desc, 137 rating_nums, 138 detail_url)) 139 movie_infos_file.flush() 140 # 计算当前页电影总个数,因单页只显示15条信息, 141 # 所以如果单页电影数小于15则表示无后续页面,则跳出循环不再请求此分类 142 current_page_movies_count = len(movies) 143 if current_page_movies_count < 15: 144 break 145 # 请求下一页标记数 146 start += current_page_movies_count 147 movie_infos_file.close()
运行结果截图:
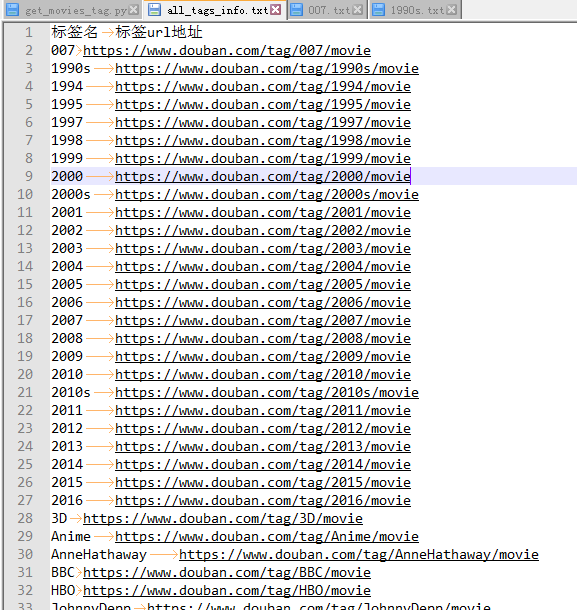
图1-电影标签信息
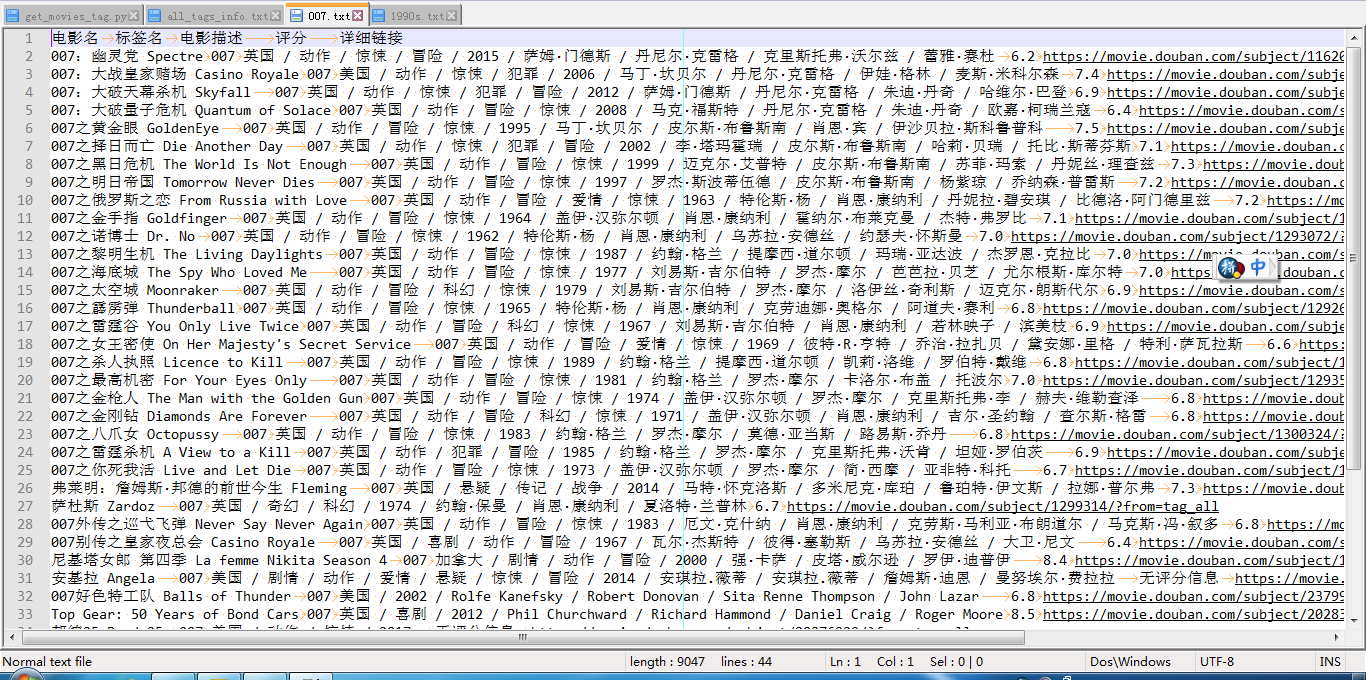
图2-具体分类下电影信息
后续优化:1、获取电影详细信息;2、请求太频繁会被禁止访问
