Request之post方法(Data为Request Payload形式)的使用
今晚运用刚学的post请求的知识,爬取了学校系统中的课程表,虽然很easy,但对于我来说还是件很有成就感的事~
首先这是我们学校的教务系统的全校课程表界面,可以看到,如果要获取所有的课程表的话,基本就是选取每个学年学期的每个开课单位,并进行查询,将查询结果的每一页内容爬取下来,最终整合到一起,就ok了。其他的选项,如上课周次、星期、课程性质等等,不用选择,默认就是全部。
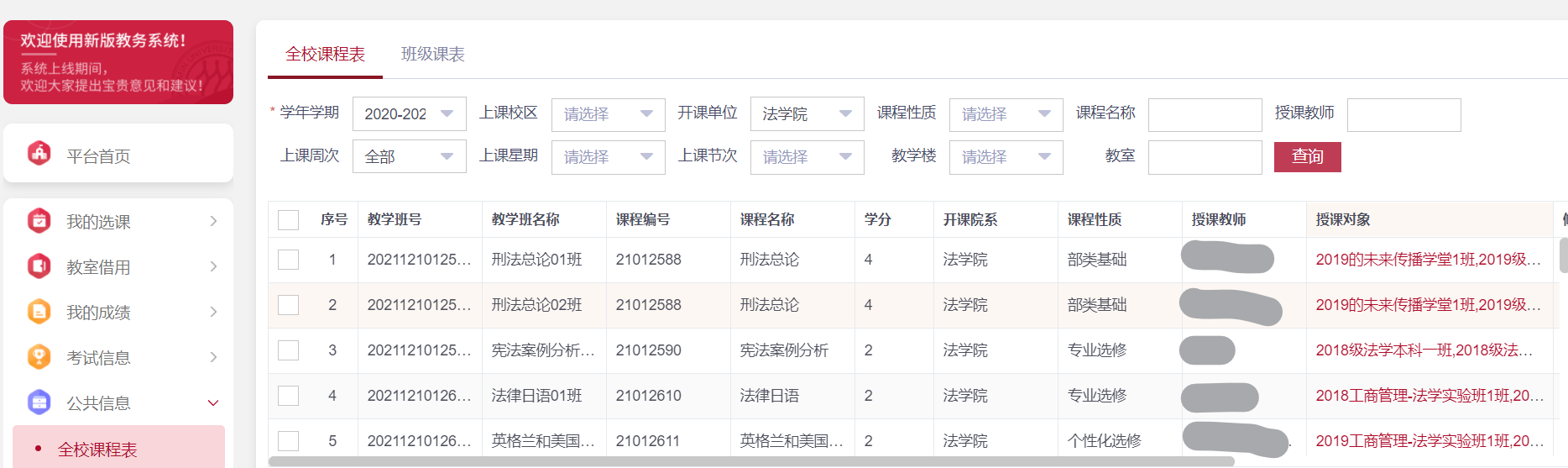
而对于各个学年学期,各个开课单位,以及各个页码,则就是一个循环的事儿。下面就着手核心部分。
通过F12在浏览器控制台中的分析,很容易发现含有要寻找信息的条目。
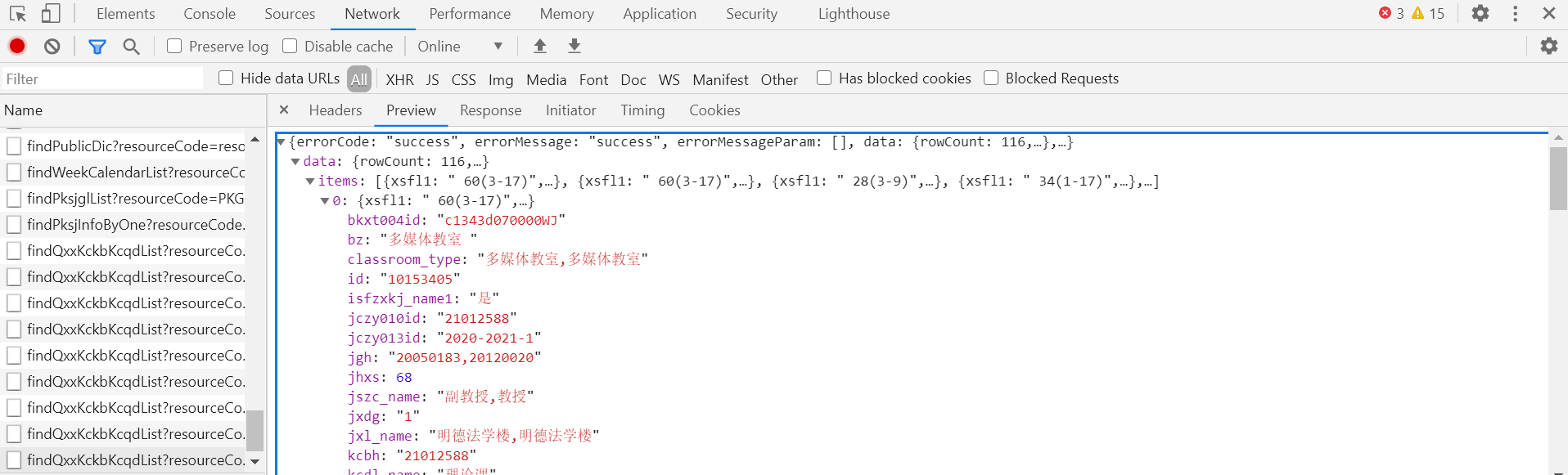
发现请求方式为POST。(由于我以前练习的都是GET请求,所以当我发现不同学院课程表的url竟然都是相同时,才发觉是POST方式233)
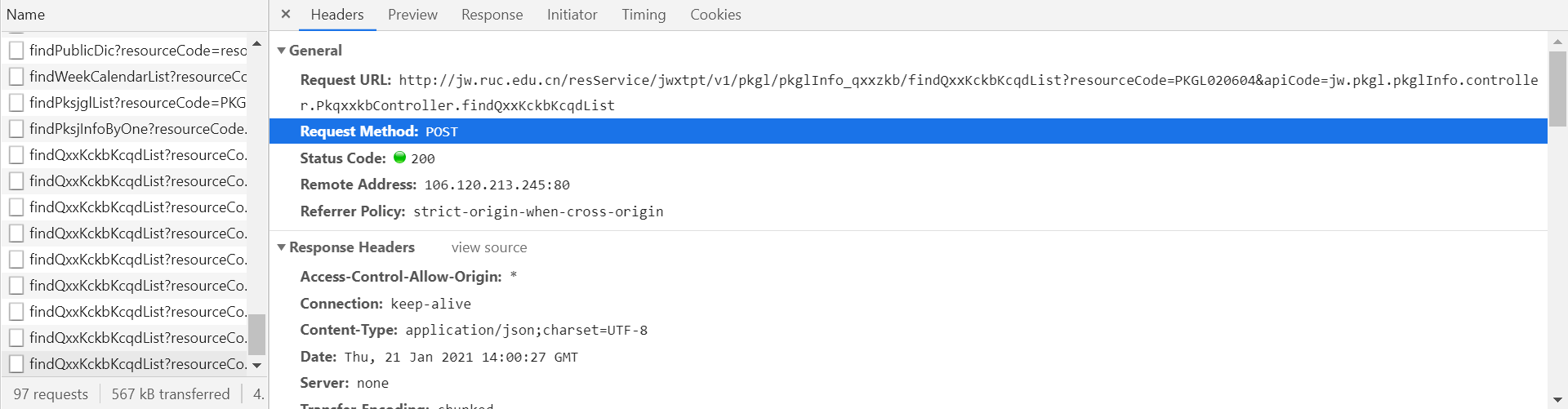
而且是Request Payload 形式的POST请求,而不是Form Data了,但正常处理。(哼,还以为什么呢,第一次见到吓了本小白一跳,于是学习了这篇文章:python爬虫如何POST request payload形式的请求。
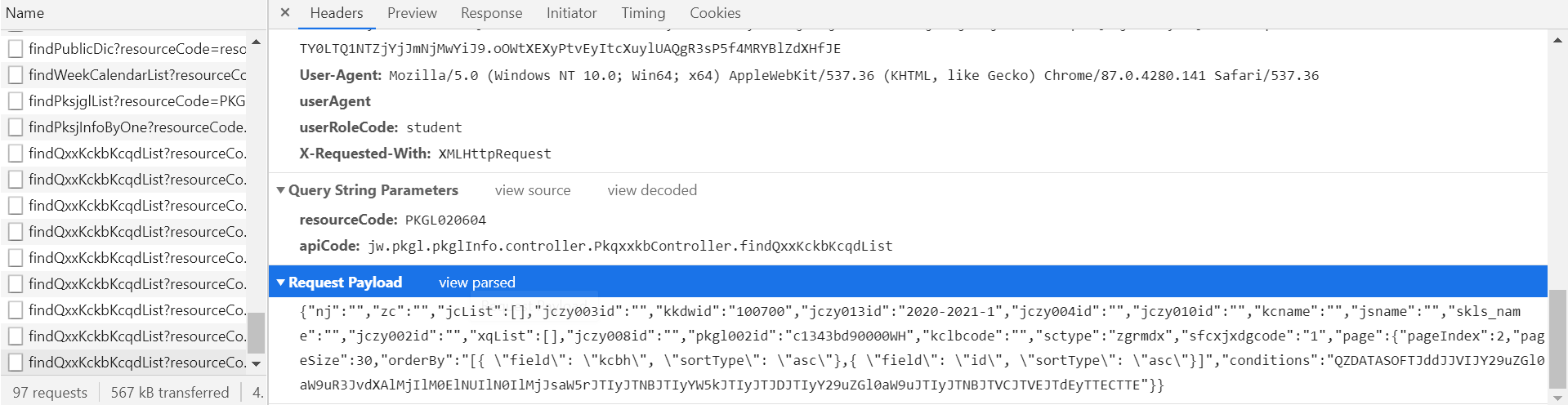
请求部分代码如下,其中对payloadData的处理上面的链接中给了好几种方式,都可以。params就是上图的Query String Parameters,复制即可。不过headers我最初挑了好几个,却总是相应无内容,一气之下(哼!)把request headers全部copy过来,大成功!
payloadData = {"nj":"","zc":"","jcList":[],"jczy003id":"","kkdwid":"100700","jczy013id":"2020-2021-1","jczy004id":"","jczy010id":"","kcname":"","jsname":"","skls_name":"","jczy002id":"","xqList":[],"jczy008id":"","pkgl002id":"c1343bd90000WH","kclbcode":"","sctype":"zgrmdx","sfcxjxdgcode":"1","page":{"pageIndex":3,"pageSize":10,"orderBy":"[{ \"field\": \"kcbh\", \"sortType\": \"asc\"},{ \"field\": \"id\", \"sortType\": \"asc\"}]","conditions":"QZDATASOFTJddJJVIJY29uZGl0aW9uR3JvdXAlMjIlM0ElNUIlN0IlMjJsaW5rJTIyJTNBJTIyYW5kJTIyJTJDJTIyY29uZGl0aW9uJTIyJTNBJTVCJTVEJTdEyTTECTTE"}}
r = requests.post(url, data=json.dumps(payloadData), headers=headers,params=params)
r.json()
下面是返回的结果
{'errorCode': 'success',
'errorMessage': 'success',
'errorMessageParam': [],
'data': {'rowCount': 116,
'items': [{'xsfl1': ' 36(1-17)',
'skdx_name': '2019工商管理-法学实验班1班,2019新闻学-法学实验班1班,2018新闻学-法学实验班1班,2019级法学本科一班,2019级法学本科三班,2019级法学本科二班',
'xsfl2': None,
'pklb_name': '法学院排课',
'xsfl3': None,
'xsfl4': None,
'bkxt004id': 'c1343d070000Xj',
'xsfl5': None,
'tk_name': '否',
'xsfl6': None,
'jhxs': 36,
'ktmc_name': '国际法02班',
下面略
}
对此进行处理就ok了。那么怎么切换到不同的学院、不同的学期的课程表呢?这里再看一下request payload的数据,下面是经过格式化显示了的。可以发现,里面的参数写的很清楚,只需要根据情况稍稍改动就可以了。
{nj: "", zc: "", jcList: [], jczy003id: "", kkdwid: "100700", jczy013id: "2020-2021-1", jczy004id: "",…}
jcList: []
jczy002id: "" ###这些空的引号表示没选,即默认全部
jczy003id: ""
jczy004id: ""
jczy008id: ""
jczy010id: ""
jczy013id: "2020-2021-1" ###这是时间信息,意为2020-2021学年秋季学期(用1表示),春季学期则用2表示。
jsname: ""
kclbcode: ""
kcname: ""
kkdwid: "100700" ###即开课单位id,因此只需要获得所有学院的id,就可以进行for循环了
nj: ""
page: {pageIndex: 2, pageSize: 30,…}
conditions: "QZDATASOFTJddJJVIJY29uZGl0aW9uR3JvdXAlMjIlM0ElNUIlN0IlMjJsaW5rJTIyJTNBJTIyYW5kJTIyJTJDJTIyY29uZGl0aW9uJTIyJTNBJTVCJTVEJTdEyTTECTTE"
orderBy: "[{ "field": "kcbh", "sortType": "asc"},{ "field": "id", "sortType": "asc"}]"
pageIndex: 2 ###这里是页码,下一条是每页显示条数(这个没法改成比如300这样的大数字,因为在页面的选项卡里有最大50这个限制)
pageSize: 30
pkgl002id: "c1343bd90000WH" #这些参数发现都是固定不变的,不用管它们
sctype: "zgrmdx"
sfcxjxdgcode: "1"
skls_name: ""
xqList: []
zc: ""
至于开课学院的id信息,可以从另一个url很方便地获取到(真的很工整呢,爱了!)其实这里包含了所有的id信息,包括学期id。

这样就万事具备了!嗯,连东风都齐全了。不过后面我就没再写,有了思路框架,内容则水到渠成,什么时候想写再说吧哈哈。
不过刚才过了一段时间再次查询,出现了错误提示,说Token过期,不过这对爬取全校课程表应该没什么影响,因为有效期还是很长的,应该有二十分钟左右,对获取全部信息来说完全足够了。
这篇文章的原理其实非常简单呐,不过写得像日记一样2333,感觉还是很有趣的!
以及一些有关的学习链接:
Python学习笔记:requests请求传递Query String Parameters参数及提交From Data数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号