RocketMQ Offset管理
## Offset管理
### 1. **Offset 的定义**
- **Offset** 表示某个消息在消息队列中的位置。通过 `Offset`,可以准确地找到该消息或者从这个位置开始继续消费消息。
- **maxOffset** 表示消息队列中的最大偏移量,是最新消息的 `Offset + 1`。
- **minOffset** 是当前消息队列中的最小偏移量,当旧消息被物理删除后,`minOffset` 会自动更新。
### 2. **消费模式与 Offset 管理**
RocketMQ 支持两种主要的消费模式,每种模式下 `Offset` 的存储和管理方式不同:
- **集群模式 (CLUSTERING Mode)**:默认情况下,多个消费者共享同一个 Consumer Group,并各自消费一部分消息。此模式下,`Offset` 由 Broker 端统一存储管理,使用 `RemoteBrokerOffsetStore` 进行远程存储,避免不同消费者之间的消费进度冲突。
- **广播模式 (BROADCASTING Mode)**:每个消费者都会消费到所有的消息,各个消费者之间独立,互不干扰。在这种模式下,`Offset` 被存储在本地,使用 `LocalFileOffsetStore`,每个消费者独立维护自己的消费进度。
### 3. **消息存储机制**
RocketMQ 使用 **CommitLog** 和 **ConsumeQueue** 协同工作来存储和检索消息:
- **CommitLog** 是物理存储层,消息的实际内容存储在 CommitLog 文件中。CommitLog 文件有固定的大小(默认 1GB),当文件满了,会生成新的文件。
- **ConsumeQueue** 是逻辑存储层,它存储的是指向 CommitLog 中具体消息的偏移量、消息长度和消息的哈希值。每个 Topic 下的每个消息队列都会有一个对应的 `ConsumeQueue` 文件,用于指向消息的物理存储位置。
### 4. **消息检索与 IndexFile**
- **IndexFile** 是消息的索引文件,用于通过 Key 或时间戳来快速查找消息。消费者可以使用消息的 Key 来查询其在 CommitLog 中的偏移量,然后通过这个偏移量在 CommitLog 中检索到实际的消息内容。
ConsumerQueue是通过偏移量offset去CommitLog文件中查找消息,但实际工作应用中,我们想查找某条具体的消息,并不知道offset值,那该怎么办呢?那IndexFile作用就来了。
IndexFile是消息索引文件,如果一个生产者发送的消息包含key值的话,会使用IndexFile存储消息索引,主要用于使用key来查询消息。文件的内容结构如图
- 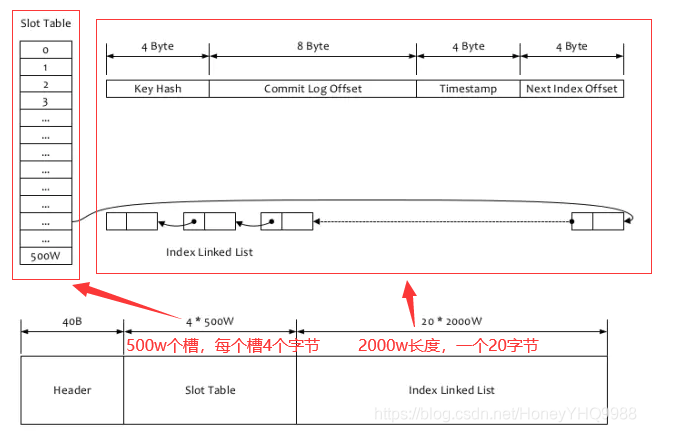
- 在Broker端,通过Key来计算Hash槽的位置,从而找到Index索引数据。从Index索引中拿到消息的物理偏移量,最后根据这个物理偏移量,直接到CommitLog文件中去找就可以了。另外说明下,通过IndexFile来查找消息的方法不影响RocketMQ的正常生产-消费流程,它只是查询定位消息的方法而已。
- 
### 5. **Offset 管理的实现**
- **Broker 端存储**:在集群模式下,`Offset` 以 JSON 格式保存在 Broker 的磁盘文件中(路径:`store/config/consumerOffset.json`),Broker 启动时会加载并管理这些 `Offset` 数据。每个 Topic 的消费进度通过 `topic@group` 这样的键值结构来记录。
- **Client 端管理**:消费者在启动时会根据消费模式选择对应的 `OffsetStore`(本地文件存储或远程存储)。在进行负载均衡时,每个消息队列的消费进度会通过 `OffsetStore` 进行更新。
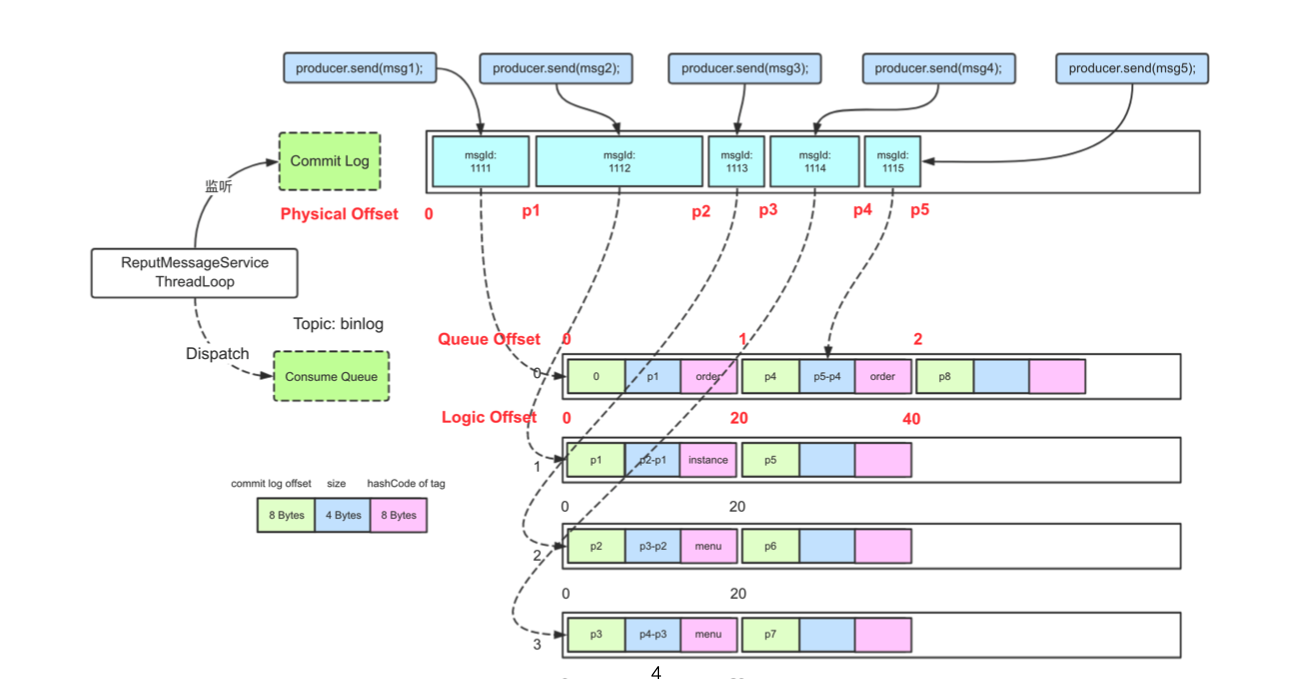
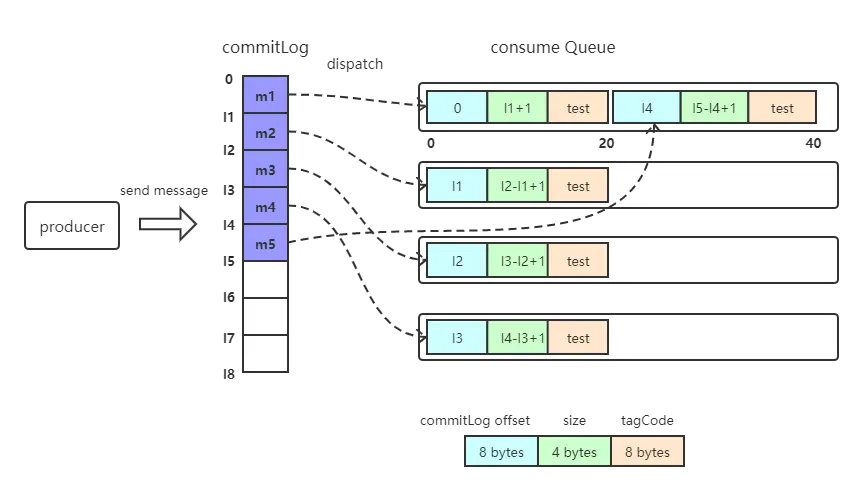
如下图所示,producer发送消息到broker之后,会将消息具体内容持久化到commitLog文件中,再分发到topic下的消费队列consume Queue,消费者提交消费请求时,broker从该consumer负责的消费队列中根据请求参数起始offset获取待消费的消息索引信息,再从commitLog中获取具体的消息内容返回给consumer。在这个过程中,consumer提交的offset为本次请求的起始消费位置,即beginOffset;consume Queue中的offset定位了commitLog中具体消息的位置。
consume Queue中每个消息索引信息长度为20bytes,包括8位长度的offset,记录commitLog中消息内容的位移;4位长度的size,记录具体消息内容的长度;8位长度的tagHashCode,记录消息的tag的哈希值(订阅时如果指定tag,会根据HashCode快速查找订阅的消息)
### 6. **Offset 的提交与更新**
在消费者处理完一批消息后,会更新消费进度:
- **推模式 (PushConsumer)** 下,当消费者成功消费一批消息后,会调用 `processConsumeResult` 方法,确认消息消费成功并移除相应的 `Offset`。然后将当前消费的最大 `Offset` 提交到 Broker 或本地文件。
- **拉模式 (PullConsumer)** 下,消费者需要自己管理和提交 `Offset`。
### 7. **重试队列和 Offset 不回滚机制**
- RocketMQ 对消费异常的消息处理是通过将消息重新发送到重试队列进行处理,而不是通过 `Offset` 回滚。这简化了客户端的 `Offset` 管理,确保消费进度的连续性。
### 8.并发消费时offset的更新
问题:consumer从broker拉取的待消费消息时批量的(默认情况下pullBatchSize=32),并发消费时,offset的更新不是按大小顺序的,比如拉取消息m1到m10,m1可能是最后消费完成的,那提交的offset的正确性如何保证?m10 offset的更新不会导致m1会误认为已消费完成。
上一小节提到消费完成后,会将线程消费的批次消息从msgTreeMap中删除,并返回当前msgTreeMap的第一个元素,也就是拉取批次最小的offset,offsetTable更新的offset一直会是拉取批次中未消费的最小的offset值。也就是m1未消费完成,m10消费完成的情况下,更新到offsetTable的当前messageQueue的消费进度为m1对应的offset值。
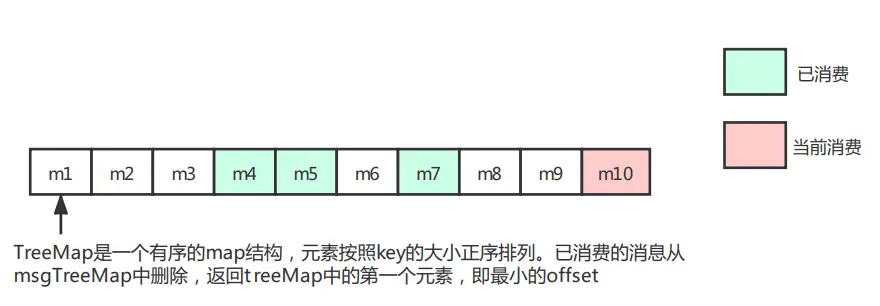
因此,offsetTable中存放的可能不是messageQueue真正消费的offset的最大值,但是consumer拉取消息时使用的是上一次拉取请求返回的nextBeginOffset,并不是依据offsetTable,正常情况下不会重复拉取数据。当发生宕机等异常时,与offsetTable未提交宕机异常一样,需要通过业务流程来保证幂等性。业务流程的幂等性是rocketMQ一直强调的。
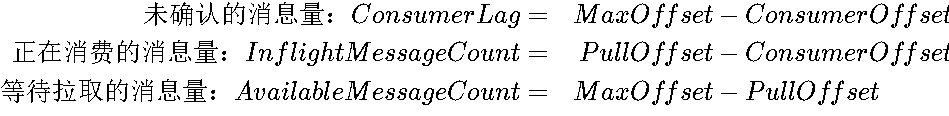
RocketMQ 中默认的消费堆积是上式中的 ConsumerLag
消息延时的算法类似,将上式中的 offset 换成对应位点消息的时间即可
-
ConsumerOffset(消费者位点):
-
定义:表示消费者已经确认消费成功的位点,也称为
CommitOffset。 -
作用:这是在消费者每次拉取消息时传递给 Broker 的位点信息,用于表明该消费者已经消费了哪些消息。消费者每次更新消费位点时,通常会更新为当前未消费的第一个消息的位点。
-
在你的场景:如果 offset 8 消费失败,消费者的
ConsumerOffset可能会停留在 8,因为这是尚未成功消费的最小消息位点。
-
PullOffset(拉取位点):
-
定义:消费者在每次拉取消息时,Broker 返回的消息的下一条消息的位点(即拉取到的消息的下一条位点)。
-
作用:消费者每次拉取到消息时会将拉取的位点更新为
PullOffset,表示下次要拉取的消息位置。 -
在你的场景:如果消息 1-7 和 9-10 被成功消费,
PullOffset会更新到下一批消息的开始位置,即 11(假设消费者已经请求了新的消息)。
-
MaxOffset(最大位点):
-
定义:表示当前消费者可以拉取的最大位点(即队列中最新的消息位点)。
-
作用:用于表示消息队列中存在的最大位点,当消费者拉取消息时,
MaxOffset代表可以拉取到的最新消息。
具体解答:
Broker 里队列的 ConsumerOffset 是多少?
在并发消费的情况下,ConsumerOffset 是基于未成功消费的最小位点来更新的。根据文章中的描述,ConsumerOffset 会停留在最小的未消费成功的消息的位点,即 8。即使 offset 9 和 10 已经成功消费,由于 offset 8 消费失败,ConsumerOffset 不会前进到 9 或 10。它将保持在 8,直到 offset 8 被成功消费。
失败的这条消息(offset 8)如何重新投递?
根据文章中的描述,当消息消费失败时,失败的消息会进入重试逻辑:
-
消费失败的消息(如 offset 8)会被投递到 重试队列 中(Retry Topic),等待再次被消费。
-
重试机制会按照一定的时间间隔(可能包括延时策略)重新投递该消息给消费者,直到该消息被成功消费或超过最大重试次数后进入死信队列(Dead Letter Queue,DLQ)。
Broker 如何知道其他消息消费成功?
文章中解释了 ProcessQueue#removeMessage 的机制,消费者会从本地缓存的 TreeMap 中移除成功消费的消息。虽然 offset 8 失败了,消息 9 和 10 的成功消费状态仍会被记录在消费者本地,并且在更新 ConsumerOffset 时,这些消息会被标记为成功消费。因此,Broker 知道 offset 9 和 10 消费成功,但不会更新 ConsumerOffset 到 9 或 10,直到 offset 8 被成功消费。
可以拉取下一批消息吗?
是的,可以拉取下一批消息。即使 offset 8 消费失败,消费者仍然可以继续拉取下一批消息(例如 offset 11-20)。这是因为 PullOffset 和 ConsumerOffset 是独立管理的。PullOffset 表示消费者下一次拉取的消息位置,而 ConsumerOffset 表示已经确认消费成功的最小位点。也就是说,即使 offset 8 尚未成功消费,消费者仍然可以请求拉取新的消息。
失败的这条消息如何重新投递?
重复消费问题(Exactly Once 语义):
在分布式消息系统中,保证消息不会被重复消费是一个常见问题。RocketMQ 默认采用至少一次(At-Least-Once)语义,这意味着消息可能会被消费多次。为了防止重复消费,常常需要在消费端实现 幂等性 逻辑。图片中的例子说明了如何通过数据库的 select for update 语句进行锁定来防止重复消费。
在你的场景中,当 offset 8 消费失败后,RocketMQ 会重新投递这条消息,导致这条消息被再次消费。为了避免同一条消息的重复处理,可以在消费逻辑中引入幂等性检查,如数据库的状态检查,确保消息只处理一次。
数据库事务管理:
图片中讨论了一个很重要的操作是将消息处理逻辑放入事务中。例如,当处理一条消息时,先查询数据库中的状态,如果该消息已经处理,则直接跳过。否则,更新状态并执行其他操作。通过这种方式,确保每条消息在数据库层面只被处理一次。
在你的场景中,当 offset 8 消费失败且被重试时,消费者再次处理消息时可以查询数据库中的状态,确认该消息是否已经处理。如果消息已经成功处理,直接返回跳过消费,避免重复逻辑。
重试机制:
RocketMQ 提供了消费失败后的重试机制。默认情况下,消息在消费失败后会被投递到重试队列,并在一定时间间隔后重新投递给消费者。这一过程通常不会影响 ConsumerOffset,除非消息被成功消费。
在你的场景中,offset 8 消费失败,RocketMQ 会自动将这条消息投递到重试队列。你可以通过配置 RocketMQ 的重试策略来控制重试的间隔和次数。同时,消费逻辑中的幂等性校验确保了即使消息被多次投递,仍然只会被处理一次。
事务的一致性保证:
图片中提到,通过数据库事务来确保多步操作的原子性。即使在失败的情况下,也可以通过回滚来确保数据的一致性。这种方式尤其适用于需要同时更新多个表或多个步骤的复杂逻辑。
在你的场景中,如果消费 offset 8 的消息涉及多个数据库操作(如更新订单状态和插入日志记录),可以通过事务确保这些操作的原子性。即使在消费失败并重试时,也可以保证前一条失败的消费没有影响到数据的完整性。
处理消息时的悲观锁(select for update):
在你的场景中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号