23、常用模块
一 time与datetime模块
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
格式化字符串的时间格式
其中计算机认识的时间只能是'时间戳'格式,而程序员可处理的或者说人类能看懂的时间有: '格式化的时间字符串','结构化的时间' ,于是有了下图的转换关系


datetime模块
二 random模块
生成随机验证码
三 os模块
os模块是与操作系统交互的一个接口
四 sys模块
打印进度条
五 shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
shutil.copyfile(src, dst)
拷贝文件
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copy(src, dst)
拷贝文件和权限
shutil.copy2(src, dst)
拷贝文件和状态信息
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
拷贝软连接
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
zipfile压缩解压缩
tarfile压缩解压缩
六 json&pickle模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,'状态'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
如何序列化之json和pickle:
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:


注意点
了解
猴子补丁与ujson
pickle

python2与python3的pickle兼容性问题
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
七 shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
八 xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
xml数据
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
自己创建xml文档:
九 configparser模块
配置文件如下:
读取
改写
基于上述方法添加一个ini文档
十 hashlib模块
hash算法就像一座工厂,工厂接收你送来的原材料(可以用m.update()为工厂运送原材料),经过加工返回的产品就是hash值

以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
模拟撞库破解密码
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 进行进一步的处理然后再加密:
注意!注意!注意
十一 subprocess模块
十二 logging模块
一 日志级别
二 默认级别为warning,默认打印到终端
三 为logging模块指定全局配置,针对所有logger有效,控制打印到文件中
logging.basicConfig()
四 logging模块的Formatter,Handler,Logger,Filter对象
五 Logger与Handler的级别
logger是第一级过滤,然后才能到handler,我们可以给logger和handler同时设置level,但是需要注意的是
重要,重要,重要!!!
六 Logger的继承(了解)
七 应用
logging配置文件
使用
关于如何拿到logger对象的详细解释
另外一个django的配置,瞄一眼就可以,跟上面的一样
直奔主题版==
1、日志级别与配置
2、日志配置字典
3、使用
common.py
十三 re模块
一:什么是正则?
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。**
生活中处处都是正则:
比如我们描述:4条腿
你可能会想到的是四条腿的动物或者桌子,椅子等
继续描述:4条腿,活的
就只剩下四条腿的动物这一类了
二:常用匹配模式(元字符)

search与findall
作业:
正则表达式中(?:pattern)、(?=pattern)、(?!pattern)、(?<=pattern)和(?<!pattern)
(?:pattern)
()表示捕获分组,()会把每个分组里的匹配的值保存起来,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推
(?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来
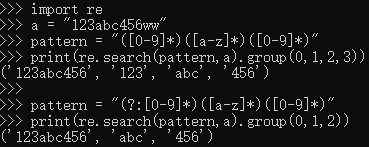
可以看到 (?:[0-9]) 匹配的第一个 [0-9] 没有保存下来,即没有保存匹配到的“123”,而([0-9]*)则保存了下来。
python中group(0)返回匹配到的整体
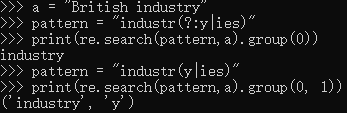
(?:pattern)在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如,'industr(?:y|ies)' 就是一个比 'industry|industries' 更简略的表达式。因为我们单独存储下 “y” 或者 “ies” 没有什么意义
(?=pattern)
正向肯定预查(look ahead positive assert),匹配pattern前面的位置。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。
简单说,以 xxx(?=pattern)为例,就是捕获以pattern结尾的内容xxx
例如,"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern)
正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。
简单说,以 xxx(?!pattern)为例,就是捕获不以pattern结尾的内容xxx
例如"Windows(?!95|98|NT|2000)"能匹配"Windows3.1"中的"Windows",但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?<=pattern)
反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。
简单说,以(?<=pattern)xxx为例,就是捕获以pattern开头的内容xxx。
例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。
(?<!pattern)
简单说,以(?<!pattern)xxx为例,就是捕获不以pattern开头的内容xxx。
反向否定预查,与正向否定预查类似,只是方向相反。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。
下述表达式都是断言,不占用宽度
前面有,正向后发(?<=exp),放前面;
后面有,正向先行(?=exp),放后面;
前面无,反向后发(?<!exp),放前面;
后面无,反向先行(?!exp),放后面。
例如
__EOF__

本文链接:https://www.cnblogs.com/amgulen/p/13952553.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构