POSO: Personalized Cold Start Modules for Large-scale Recommender Systems阅读笔记
动机
本文是2021年快手的一篇文章。目前用户冷启动有以下难题:1.新用户行为分布与普通用户有很大不同。2.尽管新用户也包含个性化特征,但是因为采样不平衡,这些特征会被淹没(个人理解就是因为新用户数据少,他们的特征很难被有效学习)。针对以上问题,本文提出了POSO方法。
方法
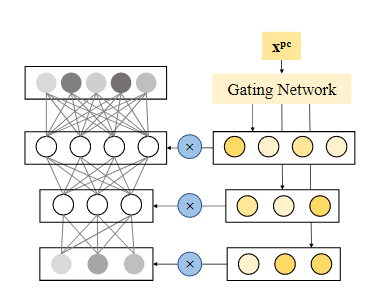
POSO不是一个单独的模型,它可以集成在其他模型中,例如常见的MLP,attention模型等。
POSO思想简单而有效,在理想的情况下,我们针对每一位用户,为他量身定做一个推荐系统。
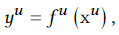
但是实际上用户数量非常庞大,我们不可能为每个用户去训练一个推荐系统。一种可能的解决方案是我们将用户分组,然后为每组用户训练一个推荐系统。一个特定的用户可以看作是几种用户的组合,
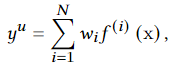
对于权重\(w_i\),我们很难去生成。对此,我们使用门控网络\(g(x^{pc})\)生成,其中pc代表识别用户组的关键属性。但是这仍需要训练多个模型,非常耗费时间和计算资源。本方法的关键点在于我们该在单层上操作,其余层保持不变
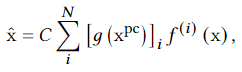
\(\hat x\)和\(x\)分别是两个相邻的层。
以MLP为例,本质上就是根据个性化特征,通过门控网络,显性地学习不同分布特征的特性。
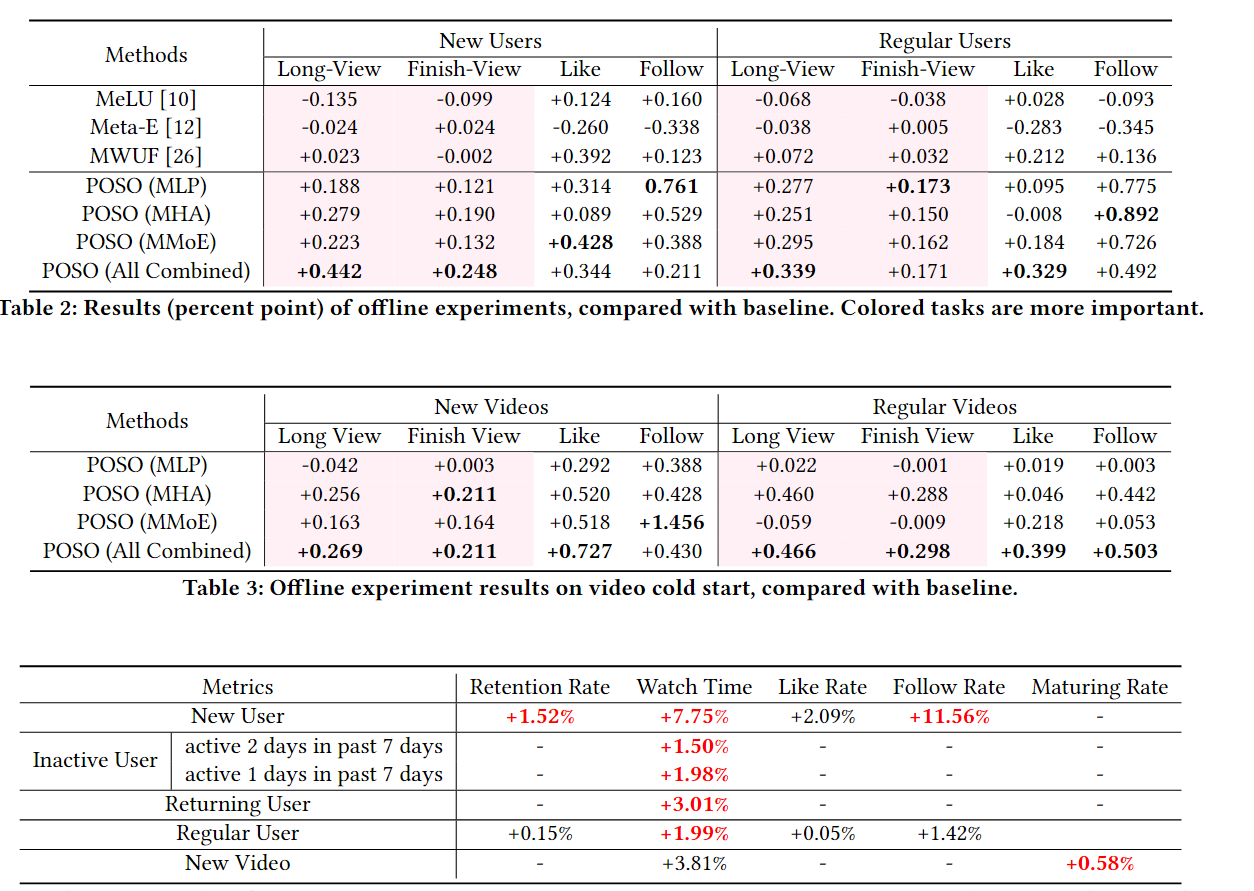
实验结果
无论是在线测试还是离线测试,本文提出的方法的效果相对于原方法均有提升。
总结
本文是工业界的一篇文章,方法看上去很扎实,没有特别复杂的公式,有的是详细的分析和简单的做法。核心思想就是利用能区分新用户和老用户的特征、门控网络和预测模块,尽管老用户占推荐系统的主导地位,但新用户可以通过另一套门控网络和模块进行学习和预测,不至于新用户因为数据少而得不到充分训练。这个思想值得借鉴。

