Improving Item Cold-start Recommendation via Model-agnostic Conditional Variational Autoencoder阅读笔记
动机
本文是2022年SIGIR上的一篇论文。解决推荐系统中冷启动问题通常有两种方法:1.挖掘历史数据中的分布模式,例如学习一个辅助信息到id的映射。2.在交互物品有限的情况下提高学习效率,例如元学习。但是很少有方法同时兼顾这两个方向,本文提出了CVAR模型解决了上述问题该文主要解决的是item的冷启动问题,在CTR预估场景下。
方法
以下是CVAR的框架。

首先我们有物品id嵌入表示,物品的所有特征表示和部分特征表示,分别用\(v_i、v_{\mathcal I}、v_{\mathcal X}\)表示。在正常情况下,我们用物品的id表示和所有特征表示即可计算出点击物品的可能性
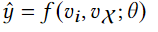
损失函数为
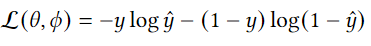
因为部分物品只有很少交互,所以它们的id表示是不准确的。本文采用了一个编码器-解码器结构,将物品的id表示降维,去除id表示的噪声,然后将辅助信息也降维,与id表示对齐。之后再通过解码器根据分布得到具体的表示,id的新的表示为
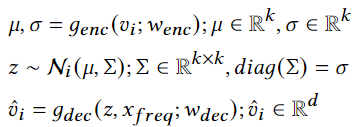
辅助信息的新的表示为

\(\mathcal L_w\)表示id的分布和辅助信息分布要相似。

原本id的表示和生成的id表示也要相似。
之后使用生成的id表示进行预测

最终的损失为
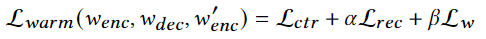
实验结果
本文提出的模型取得最好的效果。

总结
相较于以往的方法,本文是将辅助信息的分布近似于id的分布,而不是向量表示之间进行投影。因为冷启动物品或用户表示不佳,似乎用生成模型做冷启动会有更好的效果,之后也打算多看一些生成模型的推荐系统文章。

