MLP4Rec: A Pure MLP Architecture for Sequential Recommendations阅读笔记
动机
本文是2022年IJCAI上的一篇论文。自注意力模型在序列推荐上取得了卓越的效果,但是它们依赖位置编码保存顺序关系,然而位置编码可能会破坏原始embedding所包含的信息。现有的工作大多都假设这种顺序依赖关系仅存在于物品的embedding中,而忽略了物品特征中的这种依赖关系。本文提出了一种新的推荐系统MLP4Rec,该方法对物品的顺序敏感,不需要加入位置embedding,并且捕获了序列、跨通道、跨特征的相关性。
方法
以下是MLP4Rec的结构图,结构很简单,但是如果想真正了解清楚具体模型是怎么运作的,还是看一下作者提供的源码会更好。MLP4Rec源代码
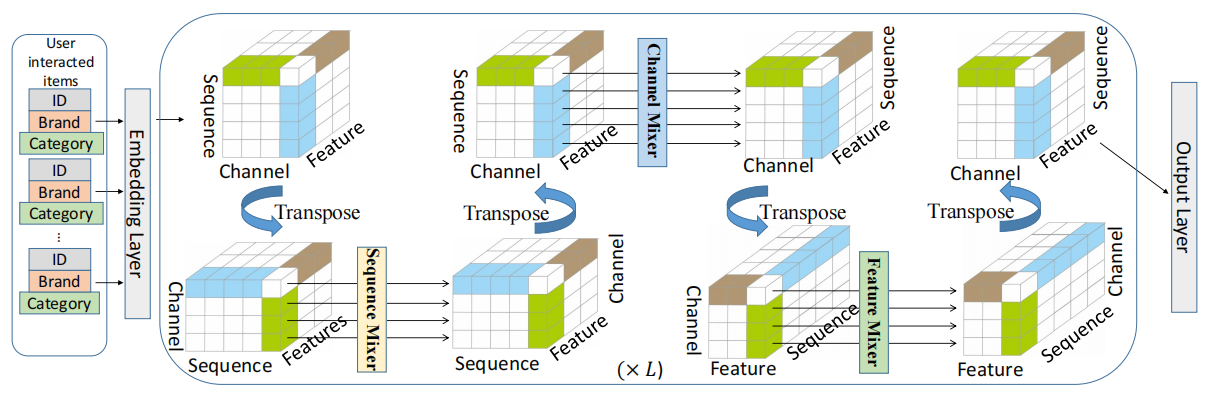
MLP4Rec结构比较简单,主要由三个混合器组成,学习三个方面的信息,分别是时间信息、商品embedding中的兴趣信息和商品特征之间的相关性。
MLP4Rec的数据输入格式为(batch_size, sequence_size, feature_size, embedding_size),了解到这一点才方便理解论文中的公式。
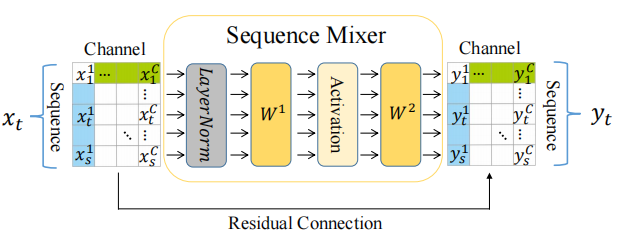
Sequence-Mixer
序列混合器学习商品序列的顺序依赖。输入和输出形状相同,但是在输出表中,所有的顺序依赖都融合在每个输出序列中。一组输入特征是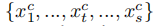 。
。
在源代码中,每个特征都对应一个Sequence-Mixer,输入数据的形状为(batch_size, sequence_size, embedding_size),作者在这里使用的是1维卷积Conv1d。
Channel-Mixer
通道混合器于序列混合器类似,不过学习的是embedding内部的相关性。通道混合器将第t个商品的embedding维度输入进通道混合器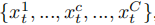 。
。
在源代码中,每个特征都对应一个Channel-Mixer,输入数据的形状为(batch_size, sequence_size, embedding_size),作者在这里使用的是线性层Linear。
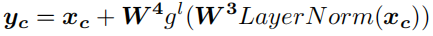
Feature-Mixer
特征混合器学习的是不同特征之间的相关性,它可以将交叉特征相关性融合到每个序列的表征中。特征混合器是最后一个混合器,在特征混合器的输入序列中,已经融合了顺序和跨通道的依赖关系。
在源代码中,只有一个特征混合器,输入数据的形状为(batch_size * sequence_size, feature_size, embedding_size),作者在这里使用的是1维卷积Conv1d。
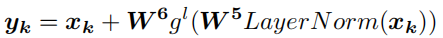
training
损失函数采用交叉熵损失函数。
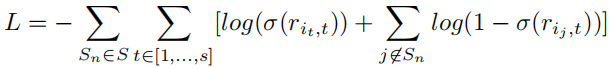
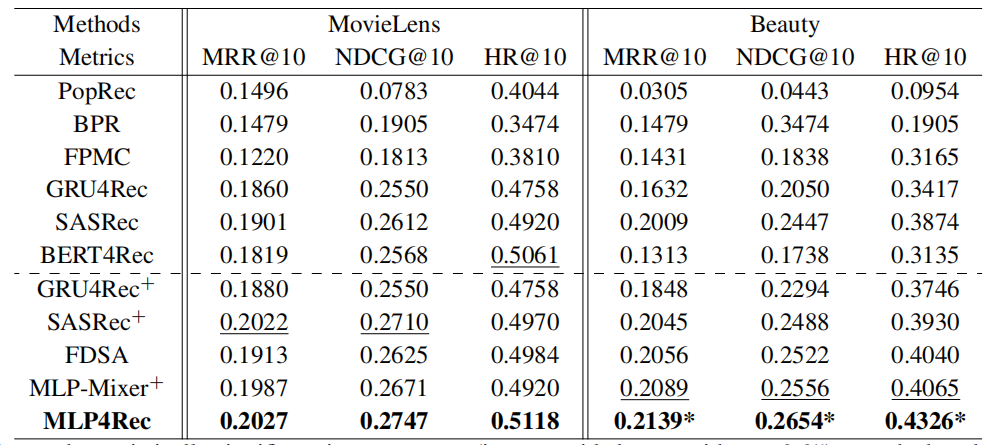
实验结果
作者在两个数据集上做了相关实验,效果超越所有基准模型。
总结
本文的核心在于用三个混合器分别捕捉顺序关系、通道之间的关系、特征之间的关系,提出的MLP4Rec算是纯MLP的模型,没有用到RNN和Attention相关的结构,但是效果却很好,同时模型结构很简单,参数很少。本文的模型基于CV领域提出的的Mlp-mixer,有时候借鉴其他领域的想法和模型也许会有意想不到的效果。

