小样本学习总结2
本周看了2篇小样本学习的文章。
Label Hallucination for Few-Shot Classification
出自AAAI2022,本文讲的是cv中的小样本分类,核心思想就是利用大的数据集进行数据增强(数据集分别为数量大的带标签的基数据集和数量小的带标签的新数据集)。
具体的方法就是用大的数据集训练出一个特征提取网络和预测网络。
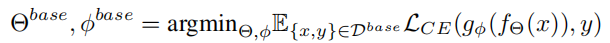
之后将小的数据集划分为支持集和查询集,在支持集上训练模型,这一步只更新预测网络,用特征提取网络和新得到的预测网络预测大数据集的标签\(\hat y\)。
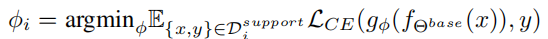
然后,每次在大的数据集和小的数据集的支持集上选出数量相同的样本进行训练,同时更新特征提取网络和预测网络。
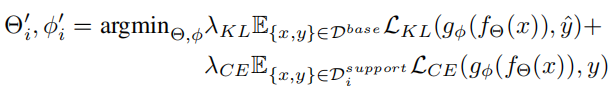
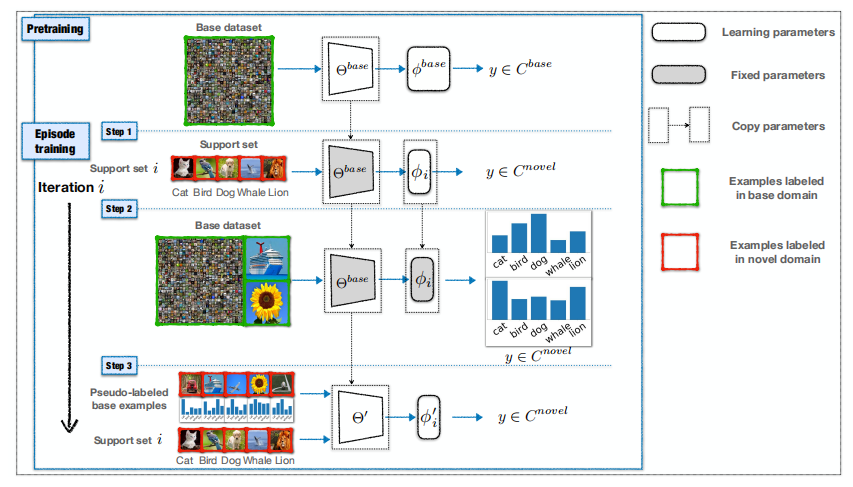
文章的思路比较简单,就是新类虽然和基类数据集标签不同,但是它们之间有的非常相似,我给基类数据集中的数据打上伪标签(伪标签都是新数据集中的标签)后,两个数据集中相似的数据标签相同,相当于扩充了新数据集。
Pushing the Limits of Simple Pipelines for Few-Shot Learning: External Data and Fine-Tuning Make a Difference
出自CVPR2022,这篇文章主要探讨了预训练、模型结构和微调对于小样本学习的影响,文章的重点似乎是为了探究这些影响做了很多实验,这篇就大概过了一遍,因为感觉对自己帮助不大。

