Fast-adapting and Privacy-preserving Federated Recommender System阅读笔记
动机
本文是2021年VLDBJ上的一篇论文。在联邦推荐系统中,存在着数据异质性的问题,一些用户与物品有很多交互,而一些用户与物品交互很少,传统的联邦推荐利于活跃用户的推荐,而几乎忽略那些不活跃的用户(这部分用户占比非常大)。同时,某些恶意用户还会尝试获取用户私有信息。为了解决以上问题,本文作者提出了PrivRec和DP-PrivRec模型,DP-PrivRec是PrivRec加入差分隐私技术的模型,可以更好地保护用户隐私,这里的保护隐私主要针对降低恶意用户识别出参与联邦学习用户的可能性。
算法
本文提出的联邦推荐方法分为两个阶段,第一阶段是利用自监督学习获得物品的embedding,第二阶段用基于一阶元学习reptile的方法学习推荐模型(PrivRec、DP-PrivRec)。
自监督学习获取物品表示
这一阶段,我们可以利用用户的交互序列来获取物品的表示,这里的交互序列不包含任何用户信息。受到BERT启发,对于一个交互序列X,我们使用一个不在序列中的物品去替代序列中的一个物品,记作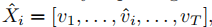 ,因此,有以下损失函数
,因此,有以下损失函数
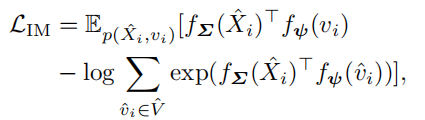
\(f_\Sigma\)和\(f_\psi\)是编码函数,分别学习物品序列和物品的表示。这个式子的目标是最大化正对(\(\hat{X},v_i\))和负对(\(\hat{X},\hat{v}_i\))之间的分数。我认为可以理解为拉近\(v_i\)和序列之中其它item的距离,同时使得\(\hat{v}_i\)和序列中其它item的距离增大。
还可以使用一段序列去替代一段序列,方法与上述类似。
第一阶段学到的物品的表示用于第二阶段初始化。
PrivRec
PrivRec是一种基于一阶元学习reptile的方法。它和FedAvg非常相似,不同的地方在于,在FedAvg中,在客户端本地训练时,每个客户端本地的数据数量会不同,这样会导致推荐系统会更利于活跃的用户,而几乎忽略了不活跃的用户,而在PrivRec中,每个客户端本地训练的数据数量相同(通过采样相同数量的交互物品来保证训练数据数量相同),从而避免出现上述问题。
整体的流程是首先采样M个客户端,向每个客户端发送模型参数,每个客户端在本地训练然后返回梯度,服务器聚合这些梯度更新模型参数。

DP-PrivRec
我们在PrivRec的基础上主要通过两个额外的步骤来构建DP-PrivRec。
在客户端本地更新的时候,我们需要对上传的梯度进行一个裁剪,S是一个预定义的阈值。
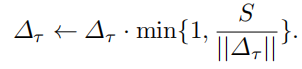
在服务器端聚合服务器传来的梯度时,我们需要加入噪声,本文采用从高斯分布\(N(0,\sigma ^2)\)获取噪声,其中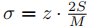 。
。
DP-PrivRec流程如下

推荐模型
本文使用的推荐模型为DSSM,模型训练过程可表示为
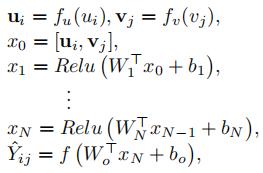
损失函数为
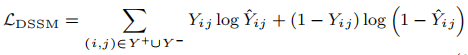
最后,总的损失函数为
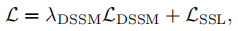
实验结果
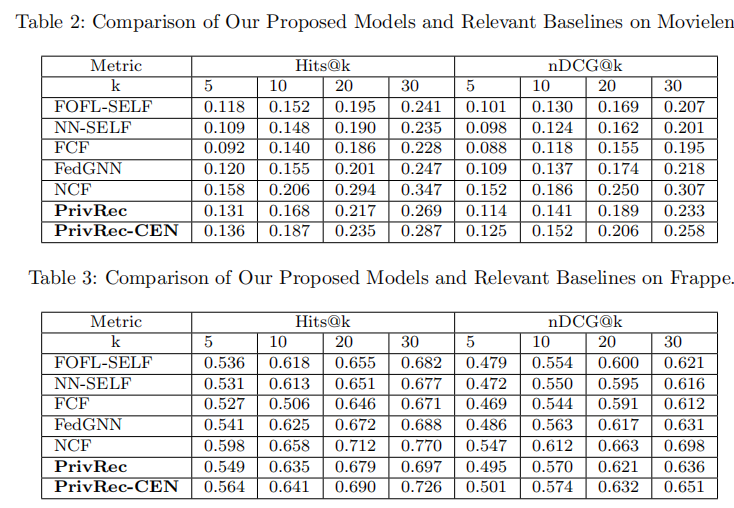
作者在movielens和Frappe两个数据集上做了实验,本文提出的方法优于所有文中提到的联邦推荐基线方法。NCF是一种效果很好的集中训练的推荐模型,可以认为是本次实验中的上界,PrivRec-CEN是PrivRec的集中训练版本。
总结
本文重点在于使用隐私差分解决恶意参与者问题和使用一阶元学习解决数据异构问题。因为隐私保护和模型性能是不能兼得的,使用差分隐私技术后模型性能会有一定的下降,本文提出的两阶段学习可以一定程度上缓解这个问题。本文使用的推荐模型是2013年提出的模型,如果换用更先进的模型,我认为性能还会有更大提升。

