FedFast: Going Beyond Average for Faster Training of Federated Recommender Systems阅读笔记
动机
本文是2020年KDD上的一篇论文。传统的联邦推荐在每一轮随机选择用户参与训练,并简单地使用它们的局部模型平均来计算全局模型,但是这种方式需要大量客户端训练多轮才能收敛到一个令人满意的效果。本文提出的FedFast可以加速训练过程,并且可以获得一个准确性更高的模型。
算法
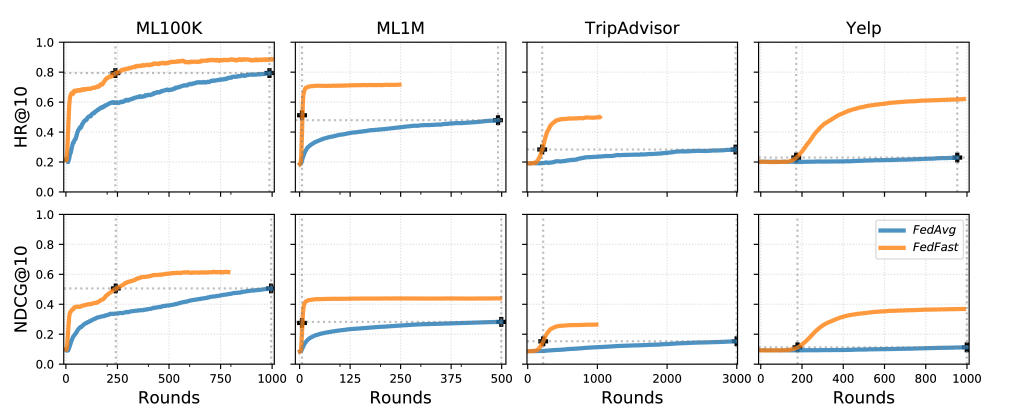
以下是FedFast算法,关键点在于ActvSAMP和ActvAGG,这两部分分别是选择客户端参与训练和模型聚合的方法。首先在每一轮确定选择的客户端数量,根据ActvSAMP采集到相应的客户端,对于每个采集到的客户端进行更新,并将新的模型参数上传至服务器,ActvAGG负责聚合用户模型并对全体用户模型进行更新。

ActvSAMP
ActvSAMP是选择一些具有代表性的客户端参与训练,我们首先需要将用户聚成p类,在每一类中随机选择m/p个用户,总共选择m个用户参与训练,将选择的用户返回。

ActvAGG
这部分负责聚合用户模型。
在第3行,模型中除了用户embedding和物品embedding之外的参数使用FedAvg方法进行更新。
第6-12行,对物品的embedding进行更新,这是一个加权更新,权值是本轮参数值和上一轮参数值的差值。
第15行,对于被选中参与更新的客户端,直接更新即可。
第18行,对于所有客户端重新聚类,聚类的根据是每个客户端的模型参数。
第20-25行,计算每个被选中参与更新的客户端贡献给它所在类的梯度。
第26-30行,计算所有没被选中的客户端的用户embedding,根据当前类中被选中参与更新的客户端的平均梯度来更新自身embedding。
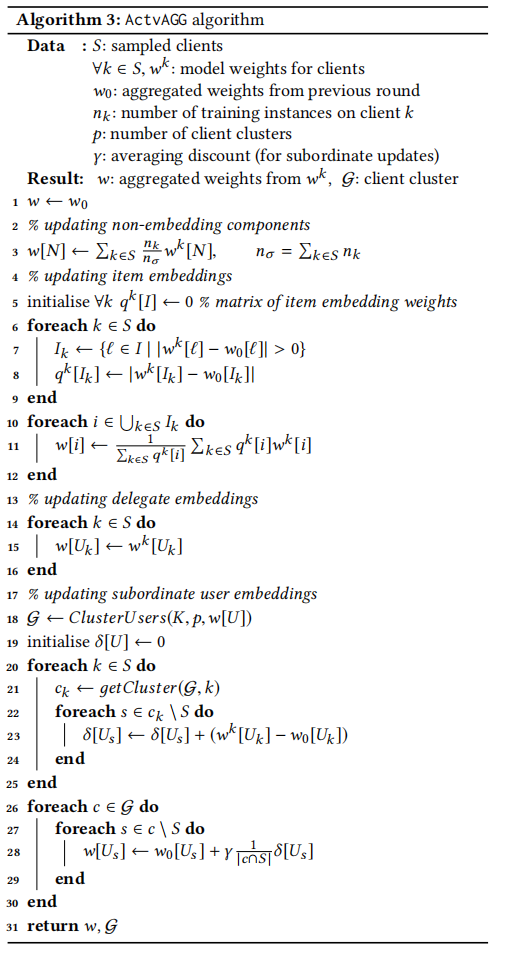
实验结果
作者在四个数据集上做了实验,在与FedAvg相同的参数设置下,FedFast表现均超越FedAvg。本文提出的FedFast是为了找出一种优于FedAvg的方法,无论是在速度还是精度上,并非要找出一种sota的联邦学习亦或是联邦推荐方法。
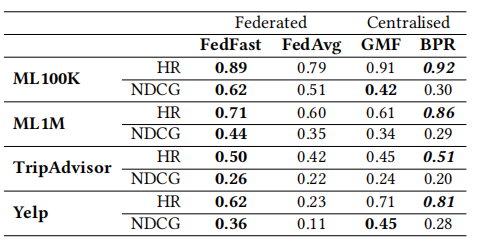
在收敛速度上,FedFast也全面超越FedAvg,在达到相同效果的时候,FedFast需要更少的更新轮次。
总结
本文的核心就是通过将客户端聚成多个类,均匀地从每个类中抽出一些客户端参与联邦学习,然后在每个类内,这些客户端的梯度可供当前类内所有客户端进行更新,从而减少计算量同时提高更新质量。未来可以尝试探索使用更少的客户端参与更新的方法,减少通信消耗。

