FAIR: Quality-Aware Federated Learning with Precise User Incentive and Model Aggregation阅读笔记
动机
本文是2021年infocom上的一篇论文。联邦学习面临着两大挑战:1.用户可能并不愿意参与到学习中,因为该学习消耗计算资源和精力。2.每个用户提供的更新质量不同,低质量的模型更新会破坏整体模型的性能。针对以上问题,作者提出了FAIR系统来解决上述问题,该系统通过评估用户学习质量来促进精确的用户激励和模型聚合。
算法
问题描述
在t时间段内,有N个计算节点 ,任务集合为
,任务集合为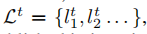 ,学习预算(给计算节点的报酬)为\(B^t_j\),节点i可以参与的任务集合为
,学习预算(给计算节点的报酬)为\(B^t_j\),节点i可以参与的任务集合为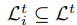 ,每个节点在每个时间段内最多只能参与一个任务。我们的目标是如何分配学习任务,支付报酬及聚合模型更新,使得聚合更新的模型质量最高。我们的质量感知联邦学习问题如下:
,每个节点在每个时间段内最多只能参与一个任务。我们的目标是如何分配学习任务,支付报酬及聚合模型更新,使得聚合更新的模型质量最高。我们的质量感知联邦学习问题如下:
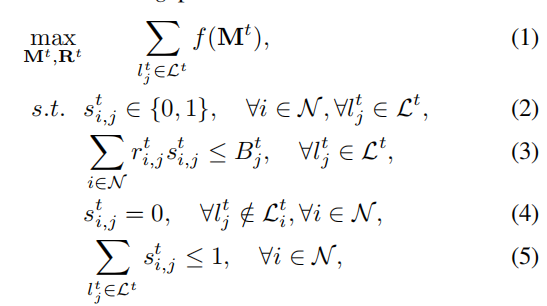
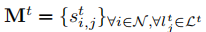 是任务分配矩阵,
是任务分配矩阵, 表示人物\(l^t_j\)在t时间段内是否分配给节点i。(3)表示t时刻内支出要小于学习预算,(4)表示节点i只能做它能参与的人物,(5)表示每个节点在一个时间段内至多参加一项学习任务。
表示人物\(l^t_j\)在t时间段内是否分配给节点i。(3)表示t时刻内支出要小于学习预算,(4)表示节点i只能做它能参与的人物,(5)表示每个节点在一个时间段内至多参加一项学习任务。
FAIR系统主要由三部分构成:1.学习质量估计。2.质量感知激励机制。3.模型聚合。
学习质量估计
我们利用每次训练的损失减少来量化训练的质量,假设训练开始时间为\(t_s\),结束时间为\(t_e\),则节点i的数据质量为

\(loss_{j}(t_s)\)表示在\(t_s\)时刻的全局模型平均损失,\(loss_{i,j}(t_e)\)表示在\(t_e\)时刻节点i局部模型的平均损失。
结合节点i的数据数量,那么节点i的学习质量为
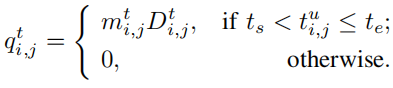
我们假设节点i在t0, t1, . . . , tr时刻学习质量为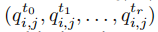 ,在t时刻,它的学习质量估计为
,在t时刻,它的学习质量估计为
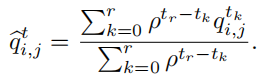
其中t>tr,0<ρ≤1。
质量感知激励机制
在这部分我们的任务是寻找一种任务分配方案,使得预估的学习质量和最大。

使用贪心算法求解本问题,大致思想是在每一轮将所有点按照\(q^t_{i,j}/b^t_{i,j}\)递减排序,按顺序遍历每个点,计算它们的报酬,如果当前报酬不超过预算就把点添加到这个任务的分配列表中,最后统计每个任务的学习质量,挑选出当前最大学习质量的任务并将该任务对应的节点分配给它,然后重复这一过程,直到没有节点可分配或者任务分配完毕。这里有几点需要注意,一个点在分配到任务后就不能再参与其它的任务,一个任务确定好分配后就不能再参与后续的分配计算。之后的问题是如何计算一个点的报酬,这里涉及到关键报酬的计算,关键报酬是使得这个点既能赢得拍卖(即参与到任务),又能保证自身利益最大化,计算公式如下
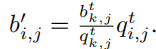
其中第k个节点就是竞拍失败但排名最高的点。
整体算法流程如下。

模型聚合
常用的联邦学习模型平均聚合公式为

但是上述公式没有考虑到模型质量,我们将模型质量加入到该公式中得
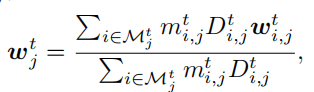
之后我们计算每个参与计算的节点的参数和全局模型参数的余弦相似度,然后计算上述余弦相似度的平均数,中位数,标准差,中位数可以反应高质量局部模型更新的方向。整体算法如下。

结果
作者在激励机制和模型聚合方法两方面证明了FAIR系统的优越性。
首先是激励机制,FAIR中模型精度接近理论最优解。

在模型聚合方法中,FAIR有更好的鲁棒性,在面对噪声、攻击等异常情况时比常用的平均联邦聚合有更好的性能。

总结与思考
本文提出的FAIR系统特点是考虑到节点学习的质量,并将估计出的学习质量结合激励机制和模型聚合,从而得到了一个效果很好的系统。这个系统是较为通用的,那么结合之前所学的知识,我认为它可以应用在推荐系统的领域,该系统提出的质量评估和反向拍卖的激励机制值得借鉴,之后我会思考如何将推荐系统模型加入到该系统中。

