FedRec Federated Recommendation With Explicit Feedback阅读笔记
动机
本文是2020年的一篇论文。对于联邦学习框架,之前的工作FCF是针对隐式数据的,它将所有未产生评分的物品都当作是负样本,间接的保护了用户的隐私,但是对于显示数据(例如评分),它求导之后很容易被服务器识别出来,因为求导的式子中只包含有交互的物品(未交互的物品应该是为0),因此会泄露用户偏好物品。本文作者提出的FedRec就是针对显示数据的联邦学习推荐框架,可用来解决上述问题。
算法
对于显示评分的梯度,如果是用户未有过交互的,那么它的值就为0,上传到服务器很容易就能看出用户与哪些物品有过交互,因此泄露了用户的隐私。
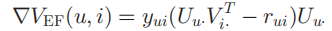
对于每个用户,我们可以另外抽样一个该用户未交互过的物品集合\(\mathcal I^{'}_u\),对于这个集合里的物品预测评分,有两种方式来填充,分别是平均填充和混合填充。
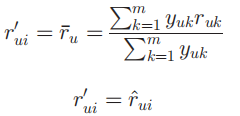
我们最终使用的数据集是有交互的物品和抽样出的无交互的物品的集合,即\(\mathcal I_u ∪ \mathcal I^{'}_u\)。
有了以上数据,我们使用概率矩阵分解模型为主干模型,有批量方式更新和随机方式更新两种方法。
批量方式的FedRec
在此方式中,服务器向每个用户发送所有物品的向量表示,用户可在本地更新自身的向量,并计算出其对应的物品的梯度(这里物品包含抽样出的未交互的物品,因此一定程度上保护了用户的交互隐私数据),上传至服务器,所有用户都上传梯度之后,服务器再更新所有物品的向量表示。
用户自身的梯度可表示为
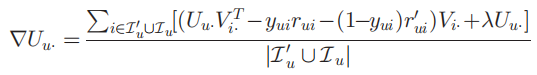
物品的梯度为
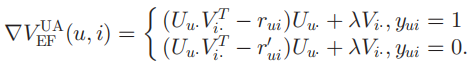
客户端算法流程为

服务器端的物品梯度
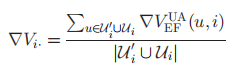
服务器端算法流程为

随机方式更新的FedRec
服务器端在每次随机抽取一个用户,向其发送物品向量数据,并从该用户获得返回的梯度,然后进行更新(批量方式是将n个用户返回的梯度聚合再更新),抽取n个用户(这n个用户都是随机抽取的,可以重复)为一个epoch,用户端每次使用一个物品向量更新自身梯度,然后再计算出该物品对应的需要返回到服务器的梯度。
服务器端算法流程

用户端算法流程

结果
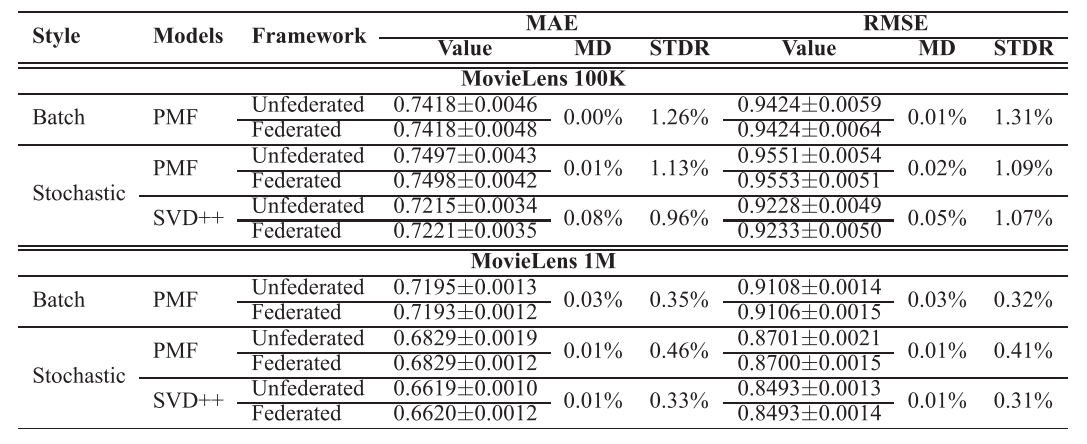
作者在两个数据集上将非联邦学习模型与联邦学习模型进行对比,两种模型的性能可认为是等效的。
总结
本文所提出的模型是对FCF模型的改进,使得其可用于显示数据。本文最关键的地方就是抽样未交互的物品,并对其赋予一个虚拟评分,将这些样本与有评分的物品组成用户的评分物品集。作者在该框架中使用了概率矩阵分解和SVD++模型,应该还有更多的模型可以在该框架中使用。另外,基于联邦迁移学习的跨域推荐也是未来值得研究的一个方向。

