Federated Collaborative Filtering for Privacy-Preserving Personalized Recommendation System阅读笔记
动机
本文是2019年华为发布的一篇论文,是首个基于联邦学习范式的推荐框架。传统的推荐系统需要把用户数据上传到服务器然后集中训练模型,但是随着用户的保护隐私意识逐渐加强和与隐私有关的法律颁布,用户可能并不愿意上传自己的数据到服务器,这就给训练推荐模型带来很大问题,因为数据会非常稀少。这时就需要一种方法既能使用户数据只保留在本地不上传到服务器,而又可以训练出与传统方法效果相似的模型。本文提出的基于联邦学习的推荐框架可以解决这个问题,它在用户终端训练模型,并把梯度上传回服务器以更新模型,这样子既可以保护用户隐私数据,同时可以训练出推荐模型。
算法
整体算法框架如图。
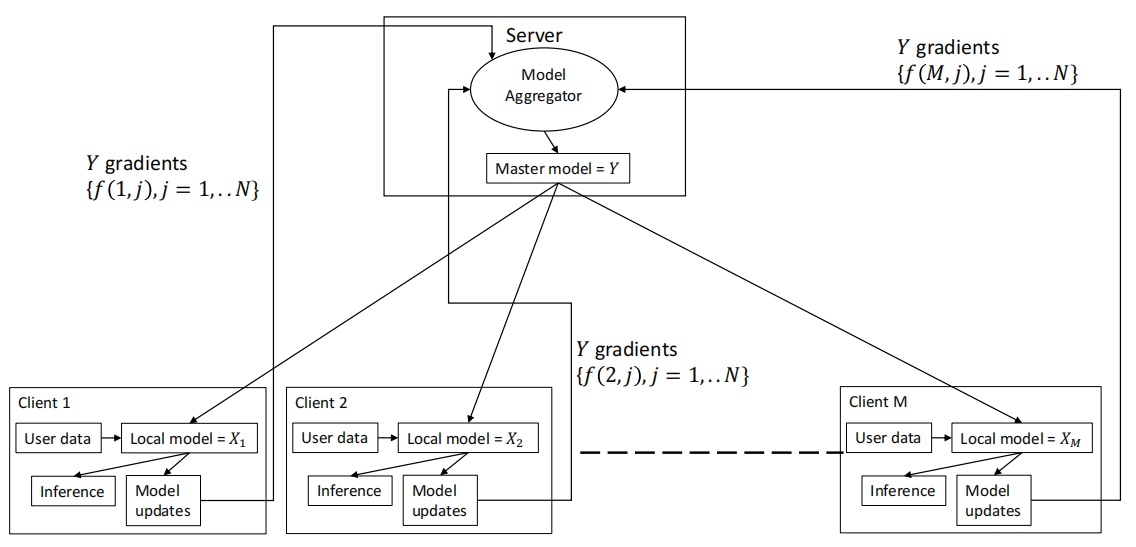
首先我们使用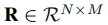 表示用户对物品的评分矩阵,可以使用矩阵分解方法将其分解为两个低秩矩阵
表示用户对物品的评分矩阵,可以使用矩阵分解方法将其分解为两个低秩矩阵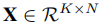 和
和 的乘积。
的乘积。
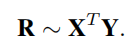
那么用户u对物品i的评分可以表示为
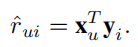
\(r_{ui}\)分数不同表示用户对该物品偏好程度不同,为了表达出这种不确定性,我们需要一个置信度参数
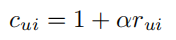
用户只要对该物品评分,我们就认为用户与该物品有交互
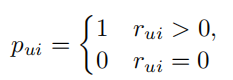
损失函数为
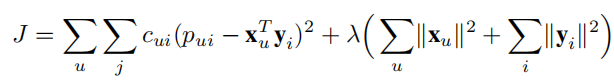
对\(x_u\)求偏导为
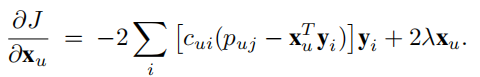
令偏导为0得
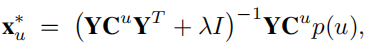
同理可得
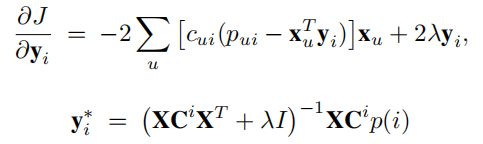
可通过迭代交替计算X和Y(交替最小二乘法)使损失最小。
以上是传统的推荐系统方法,如今我们在服务器端不能使用用户数据,即在计算y的时候不能直接使用x,那么该怎样更新模型?
用户因子更新
对于每个用户,服务器可以将物品向量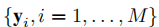 直接发给用户,用户可利用最小二乘法直接更新自身向量,与传统方法相同。
直接发给用户,用户可利用最小二乘法直接更新自身向量,与传统方法相同。
物品因子更新
我们不能直接使用用户向量去计算物品向量,因此,在这部分使用梯度下降来更新物品向量
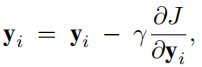
我们定义\(f(u,i)\)为
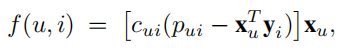
我们可以在每个用户客户端计算\(f(u,i)\),并将其上传至服务器,之后就可以更新物品向量
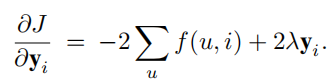
总体流程为

结果
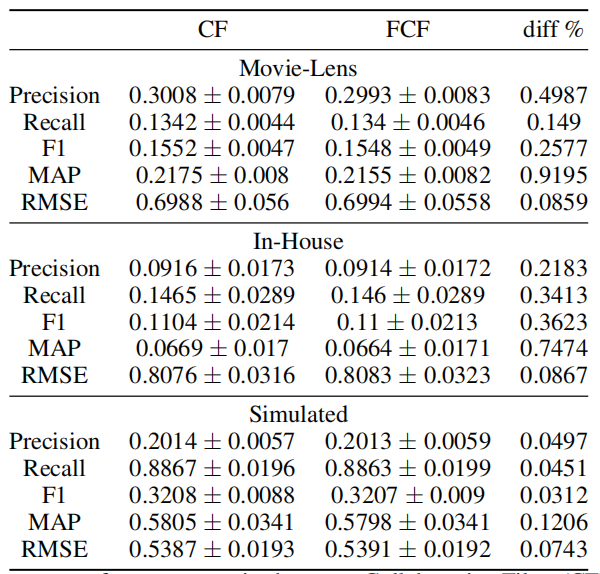
作者在三个数据集上做了实验,与传统的方法相比,联邦推荐系统几乎没有性能损失。
总结
本篇文章算是开创性的论文,是首个联邦推荐系统框架,技术上并不复杂,使用的是已经存在的方法,最基础的矩阵分解模型。比较有新意的点是不把数据集中起来做模型更新,而是从各个用户端获取梯度,把梯度集合起来更新模型,并且模型效果最后和传统方法相当。这是一个最基础的联邦推荐系统,后续应该会有很多方法对其进行改进。

