Contrastive Learning for Representation Degeneration Problem in Sequential Recommendation阅读笔记
动机
本文是2022年WSDM的一篇文章。基于深度学习的序列推荐模型生成的物品embedding可能会退化,在语义上高度相似,使得这些物品区分度降低。对比学习是缓解这一问题的方法,但以往的对比学习通常是依赖数据级的增强,它不能提供很好地提供语义一致性的增强样本(按照我的理解就是进行数据增强后得到的正样本与原样本语义上不相似了,对比学习效果不好),本文提出了DuoRec模型是模型级的增强,通过dropout使增强后的数据语义更好保存,可以改善物品embedding的分布。
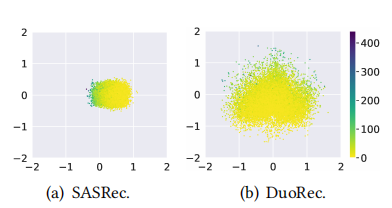
图中是亚马逊衣物的一个数据集,DuoRec得到的物品embedding明显分布更均匀一些,在预测的时候有助于区分不同的物品。
算法
对比学习的两个特性Alignment and Uniformity,从字面上较难理解是什么意思,在网上查到的理解是,Alignment:一个正对中的两个样本的特征应该相似,即它们投影获得的embedding应该是相似的,Uniformity:物品特征向量应均匀分布在超空间内,以保存更多的信息。本文的重点就是所提出的对比学习方法。
序列编码
假设一个embedding矩阵为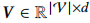 ,它代表一个序列
,它代表一个序列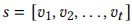 。还有一个位置编码矩阵
。还有一个位置编码矩阵 ,N为最长序列的长度。我们将物品embedding和位置embedding相加得到时间t的交互表示
,N为最长序列的长度。我们将物品embedding和位置embedding相加得到时间t的交互表示
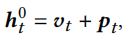
假设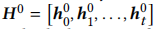 为一个序列的隐向量表示,可以通过一个多头transformer编码器编码这个序列
为一个序列的隐向量表示,可以通过一个多头transformer编码器编码这个序列
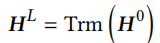
序列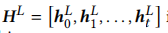 最后一个\(h^L_t\)为这个序列的表示。
最后一个\(h^L_t\)为这个序列的表示。
预测
预测分数可以用所有物品embedding矩阵与序列embedding相乘,再用softmax函数得到
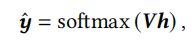
\(\hat{y}\)其实就是该序列下一个点击物品的概率。最终损失由交叉熵损失函数获得
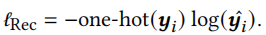
对比正则化
对比正则化主要通过无监督增强和监督正采样两部分实现。
无监督增强目标是通过无监督的方式提供有意义的语义增强数据,它通过在两个地方设置dropout掩码实现生成语义相似的数据。第一个是在此处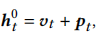 设置掩码得到\(h^{0'}_t\),之后再将其输入transformer encoder中,此处也有dropout
设置掩码得到\(h^{0'}_t\),之后再将其输入transformer encoder中,此处也有dropout
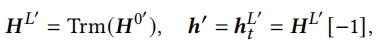
监督正采样。有相同下一个点击物品的序列是语义相似的,可以从相似语义序列中采样为正样本\(H^{0'}_s\),则监督正采样数据增强为
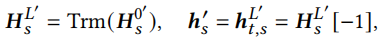
负采样。一个batch数据个数为|B|,因为无监督数据增强的原因,一个batch有2|B|个隐向量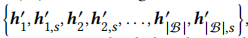 ,对于一个正对来说(自身增强及正采样共两个向量),其余2(|B|-1)个向量均为负样本(如果有序列和当前序列的下一个点击物品相同,需要将该序列从负样本集合中除去)。比如对于第1个序列来说,它自身增强和正采样构成正对\(h_1^{'}和h^{'}_{1,s}\),
,对于一个正对来说(自身增强及正采样共两个向量),其余2(|B|-1)个向量均为负样本(如果有序列和当前序列的下一个点击物品相同,需要将该序列从负样本集合中除去)。比如对于第1个序列来说,它自身增强和正采样构成正对\(h_1^{'}和h^{'}_{1,s}\),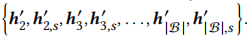 构成负样本集合。
构成负样本集合。
最终对比正则化可由以下公式计算得出
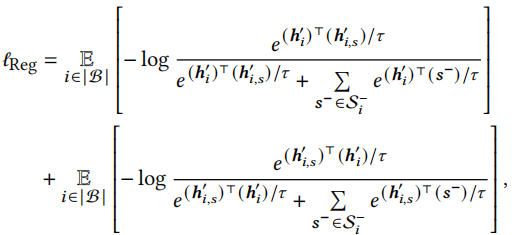
优化
模型总的损失函数为
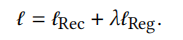
\(\lambda\)是超参数。
结果
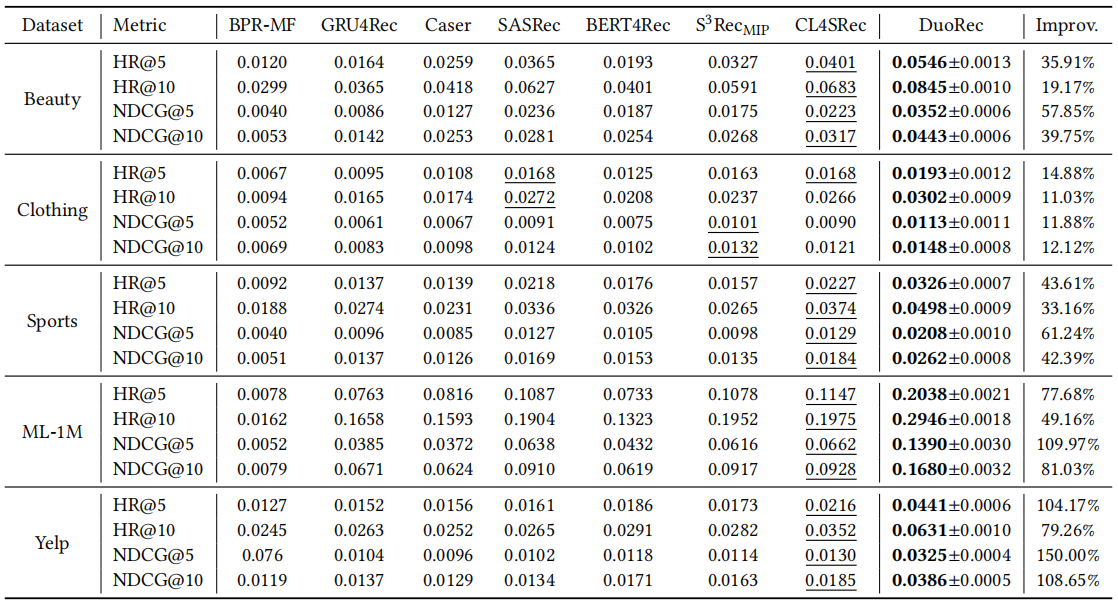
本文提出的模型在五个数据集上均取得最好结果,而且结果提升非常明显,我认为这应该是得益于作者所提出的对比学习更好地落实了Alignment and Uniformity这两方面。
总结
总的来说,这篇文章中最重要的地方就是作者所提出的对比学习的方法,作者也通过将物品embedding投影到二维空间并与其它模型的物品embedding对比,确实本模型的embedding分布更均匀,保留了更多的信息。我认为可以将该对比方法和其它sota模型(本模型的embedding生成部分是基于attention机制的)组合,或许会有更好的效果。或者进行难负样例挖掘,以获得更好效果的对比学习。

