Sequential Recommendation with Graph Neural Networks阅读笔记
动机
本文是2021年SIGIR的一篇论文。目前现有的工作在序列推荐面临着两个挑战:1.用户的历史行为序列通常是隐式反馈的且包含噪声,它们不能充分反映出用户真实偏好。2.用户动态偏好会随时间快速变化,因此很难捕获到用户偏好模式。本文提出一种名为SUGRE的图神经网络,它将稀疏的项目序列重构为紧密的项目兴趣图,并将不同种类的偏好在图上合并为簇。
算法
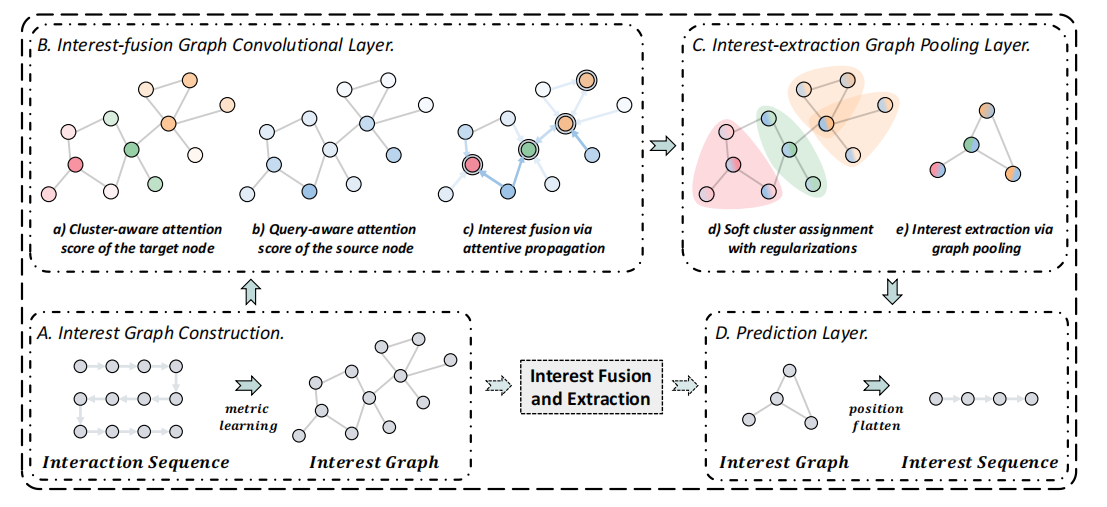
主要分为四个部分,分别是构建兴趣图、图卷积兴趣融合、兴趣提取、预测。
Interest Graph ConstructionE
对于每个交互序列可构成一个无向图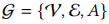 ,\(\mathcal V\)是点的集合,\(\mathcal E\)是边的集合,\(\mathcal A\)是n×n的邻接矩阵,这部分的目标是学习一个邻接矩阵\(\mathcal A\)。可以通过度量学习计算两个节点的相似度,通过节点相似度大小判断两个节点之间是否有链接,这里使用带权余弦相似度计算。
,\(\mathcal V\)是点的集合,\(\mathcal E\)是边的集合,\(\mathcal A\)是n×n的邻接矩阵,这部分的目标是学习一个邻接矩阵\(\mathcal A\)。可以通过度量学习计算两个节点的相似度,通过节点相似度大小判断两个节点之间是否有链接,这里使用带权余弦相似度计算。
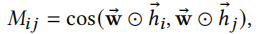
w是可学习的权重。为了增强表达能力和稳定训练过程,可以使用多头度量方法
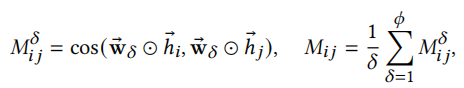
邻接矩阵A由以下公式计算得出
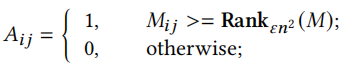
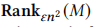 表示M中第\(\epsilon n^2\)大的值
表示M中第\(\epsilon n^2\)大的值
Interest-fusion Graph Convolutional Layer
该层的输入是一个序列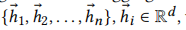 ,输出节点表示由以下公式计算
,输出节点表示由以下公式计算
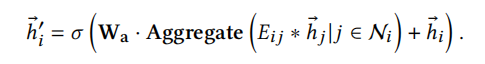
其中\(W_a\)是权重矩阵。采用多头注意力机制如下
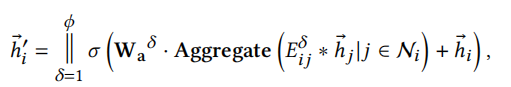
注意力系数\(E_{ij}\)计算公式为
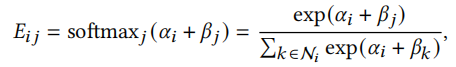
其中\(\alpha_i\)是簇感知注意力,它控制了目标节点能接收多少信息,计算公式如下
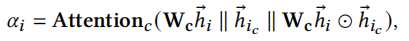
\(h_{ic}\)是节点i的k跳之内邻居的embedding平均值。
其中\(\beta_i\)是查询感知注意力,它控制了源节点能发送多少信息,计算公式如下
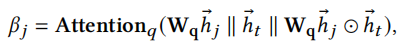
\(h_t\)是查询节点的embedding。
Interest-extraction Graph Pooling Layer
簇分配矩阵为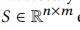 ,经过提取后的信息为
,经过提取后的信息为
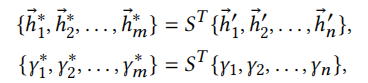
\(\gamma_i\)由对\(\beta_i\)使用softmax得到。
S的每一行代表一个节点,每一列代表一个簇,\(S_{ij}\)就是节点i分配到簇j的概率。计算公式如下
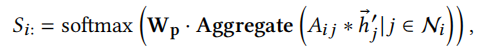
只有下游推荐系统传过来的梯度信息很难去训练概率矩阵S,因此我们使用以下三个正则化辅助训练。
相同映射正则化,使两个有很强连接的点被分到同一个簇
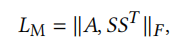
单个从属关系正则化,使每个点尽可能分到其中一个簇中
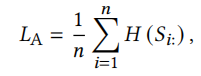
相对位置正则化,使位置较前的点分到位置较前的簇中,以此类推
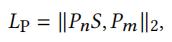
图的表示输出
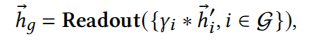
Prediction Layer
人的兴趣是会变化的所以要对兴趣演化建模
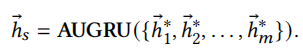
最终输出
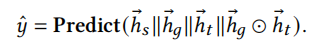
损失函数为
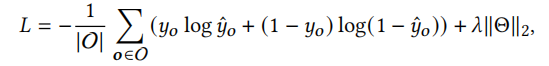
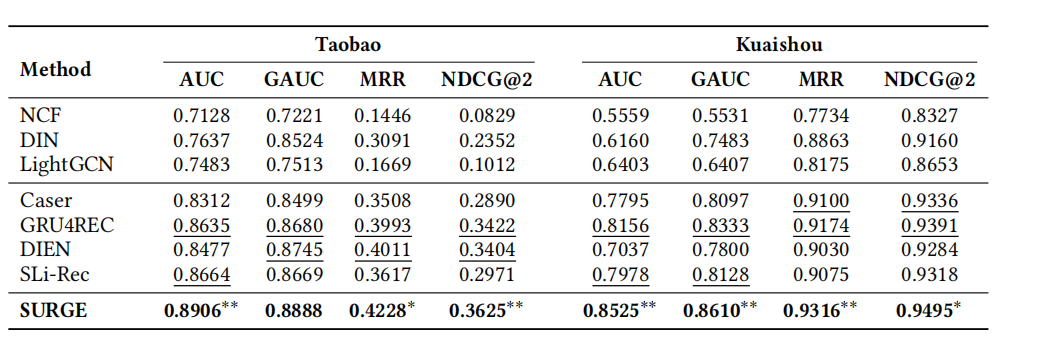
结果
作者在两个数据集上做了实验,本文提出的模型均取得最好效果。
总结
本文提出的模型是比较复杂的,多处用到了注意力机制,而且用的三个正则化很巧妙,一定程度上解决了图中缺乏顺序信息的问题。整体的流程图如下,整个过程就是将一个交互序列提取为信息浓缩的兴趣序列。之后可以用更多交互信息探索图的序列推荐。