Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning 阅读笔记
动机
本文是2022年的WWW的一篇论文。图协同过滤方法是一种有效的推荐方法,它很有效,但是它们面临着数据稀疏的问题。对比学习通常用来缓解这个问题,但是目前推荐系统中的对比学习通常是随机采样来构成对比数据对,它们忽略了用户(物品)之间的邻接关系,不能充分发挥对比学习的潜力。本文提出一种通用的框架NCL(Neighborhood-enriched Contrastive Learning),它明确地将潜在的邻居包含在对比对中,更具体的,它将用户(物品)结构上的邻居与语义空间上的邻居包含在正对比对中。结构上的邻居指的是在用户与物品交互图中的直接相连的或是经过多跳相连的,语义邻居指的是两个用户(物品)有相似的embedding。
算法
主干网络
本次实验中主干网络采取类似于LightGCN的结构,其中传播函数可写为
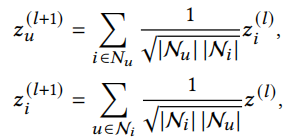
经过L层的传播后,最终的用户与物品表示为
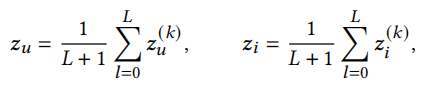
使用点积预测用户u有多大可能与物品i交互
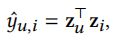
损失函数采用BPR loss
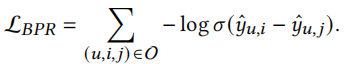
结构邻居的对比学习
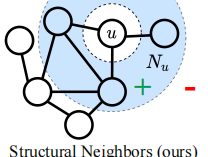
\(z^{(0)}\)可以看作用户(物品)最初的embedding,\(z^{(l)}\)可以看作聚合了l跳以内邻居信息的embedding。现在考虑将用户物品交互图看作二分图,我们可以将偶数跳的embedding看作是同质邻居,即用户的偶数跳邻居是用户,物品的偶数跳邻居是物品。由此,以用户为例,我们可以将用户与他的偶数跳邻居看作对比学习中的正对(positive pair),结构对比学习的目标是最小化以下函数
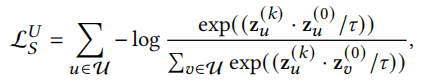
类似可以得到物品的损失函数
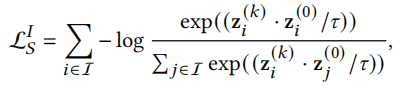
综合上面两个损失函数克的整体结构对比学习损失函数为
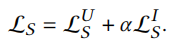
\(\alpha\)是超参数,用于权衡两部分损失。
语义邻居的对比学习
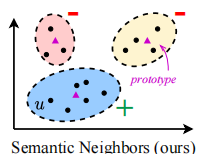
由于结构邻居对比学习平等对待所有同质邻居,这不可不免会引入一些噪声,语义邻居的对比学习可以减少噪声。相似的用户或者物品会在相邻的嵌入空间内,原型(prototype)是一组语义邻居集群的中心。我们可以使用聚类算法以得到用户或物品的原型,这个过程无法进行端到端的优化,这里通过EM算法学习。以用户为例,GNN模型需要最大化的似然函数为
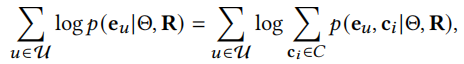
其中\(c_i\)可以看作用户u的原型,即用户u所在簇的中心。
语义对比学习的目标可以写作
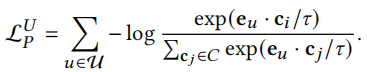
对于物品来说
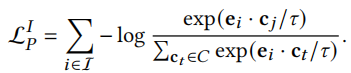
综合两部分损失函数得
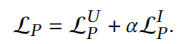
\(\alpha\)是超参数,用于权衡两部分损失。
优化
本次实验是多任务学习,整体优化目标如下
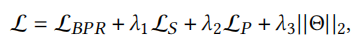 、
、
其中\(\lambda_1,\lambda_2,\lambda_3\)是超参数。
实验结果
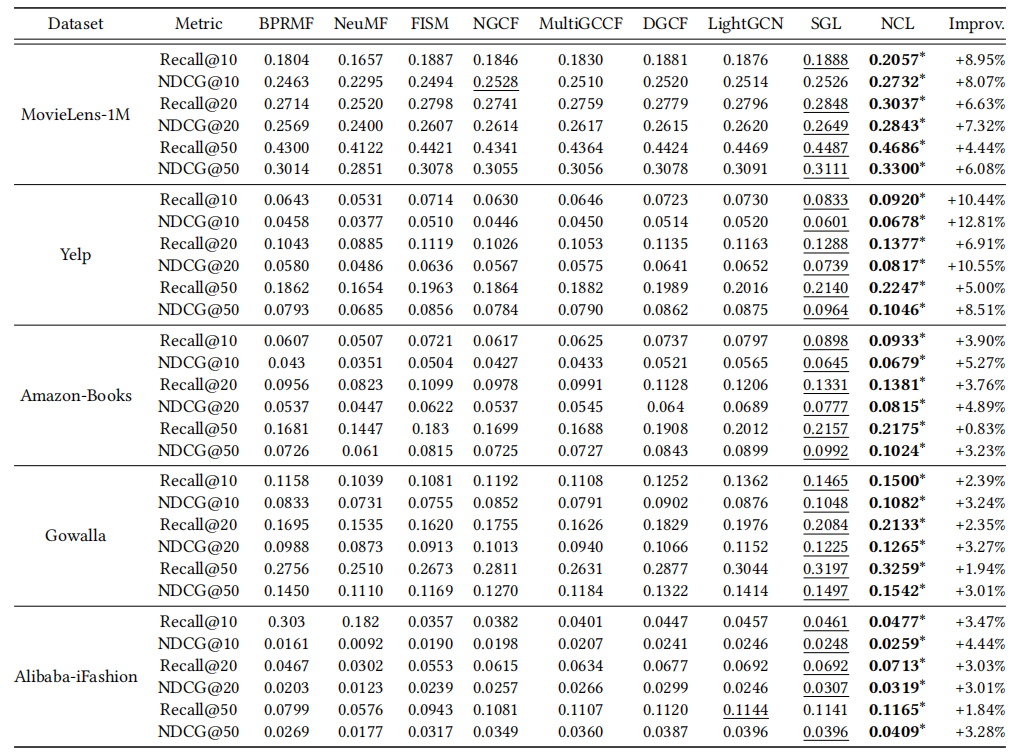
本次实验以LightGCN为主干模型,作者对比了一些经典的模型,在五个数据集上均取得最好效果。
总结与展望
本文提出了一种通用的框架,通过两种对比学习——基于结构邻居的对比学习和基于语义邻居的对比学习,捕获到更多潜在的用户物品之间的相关性信息。在未来,可将该框架用于序列推荐或更广泛的推荐中。另外,看完本论文后我有一个小疑问:结构邻居的对比学习中,作者在聚合每个node的时候,即便是偶数层,聚合得到的信息应该不是只有同质邻居的信息,还包括异质邻居的信息,如果有方法把异质邻居这部分信息削弱会不会有更好的效果。

