Cold-start Sequential Recommendation via Meta Learner阅读笔记
动机
本文是2021年AAAI的一篇文章。在序列推荐中,如果只有用户物品交互数据而没有其它辅助数据的情况下,以往的冷启动方法无法应用在序列推荐中。因此本文提出了一种基于元学习的序列推荐冷启动框架,称为Mecos。Mecos根据有限的交互数据来提取用户的偏好(只需要用户物品交互信息),并学习将冷启动项目匹配给潜在可能交互的用户。
根据我的想法,本文本质应该就是序列推荐的小样本学习,而元学习可以解决小样本学习问题。
算法
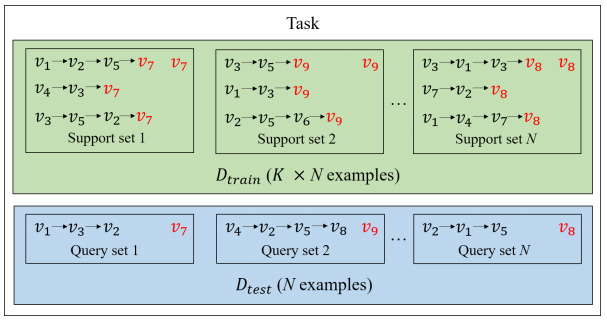
本文解决的是序列推荐中的项目冷启动问题。\(\mathcal{U}\) 和\(\mathcal{V}\)分别代表用户集合和物品集合,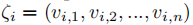 表示用户\(u_i\)按时间顺序的交互集。我们的目标是根据\(\zeta_i\)预测下一个点击物品\(v_{i,n+1}\)。
表示用户\(u_i\)按时间顺序的交互集。我们的目标是根据\(\zeta_i\)预测下一个点击物品\(v_{i,n+1}\)。
元学习数据集构建
假设冷启动物品为N个,我们首先选出冷启动物品,对于每个冷启动物品,采样K个序列,这样就构成pair(\(\zeta_i\),\(v_{i,n+1}\)),其中\(v_{i,n+1}\)就是冷启动物品,每个pair作为元学习中的support set。元学习中的query set可表示为(\(\zeta_i\),?),?是需要预测的物品,并且support set和query set不相交。下图是有N个冷启动物品且采样序列为3的情况。
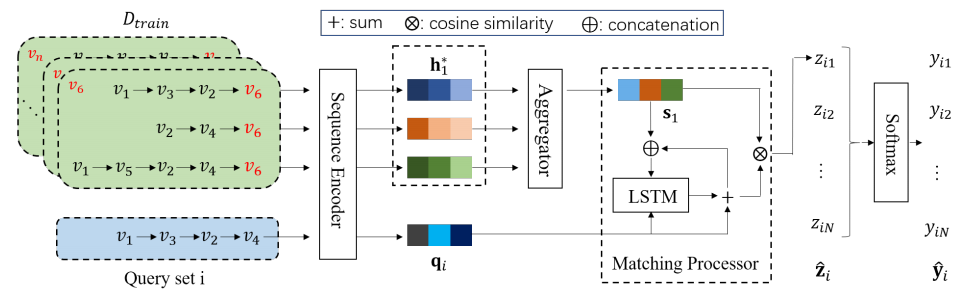
编码support set和query set
这里注意每个序列长度不一定相同,而且对于support set中的数据是有标签的,query set中的数据无标签,首先对support set进行编码。
\(v_{i,j}\)表示\(\zeta_i\)中第j个物品的embedding,维度为d,\(v_{i,n+1}\)是下一个点击的物品embedding。因此对于序列\(\zeta_i\)有如下表示
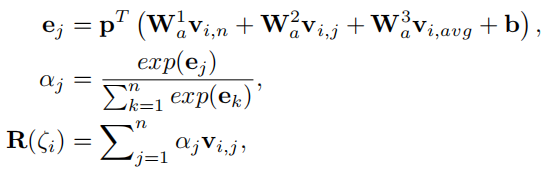
其中\(R(\zeta_i)\)表示序列\(\zeta_i\),\(P^T\)是投影向量,\(W_a^1,W_a^2,W_a^3\)是可学习的权重参数,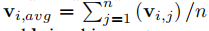 ,b是偏置向量。之后将序列表示和下一个点击物品embedding结合
,b是偏置向量。之后将序列表示和下一个点击物品embedding结合
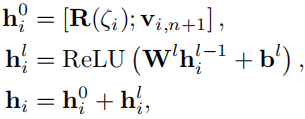
其中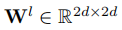 和
和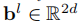 是第l层的权重和偏置。
是第l层的权重和偏置。
在编码了K个序列对后得到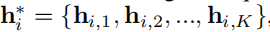 ,我们把这个集合中的元素聚合可得
,我们把这个集合中的元素聚合可得
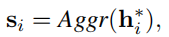
Aggr(·)是聚合函数,可以是mean pooling,max pooling,神经网络等。
在query set中,序列\(\zeta_i\)编码方式相同,但是对于序列对\((\zeta_i,?)\),因为缺失下一个点击物品,可将上式中\(h_i^0\)表示改为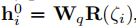 ,其余部分和support set中的方式相同。
,其余部分和support set中的方式相同。
匹配support set和query set
本文采用以下公式计算support set和query set的相似度,选择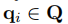 和
和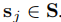 ,有以下公式
,有以下公式
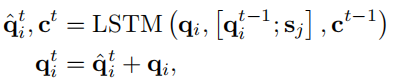
\(q_i\)为输入,\([q^{t-1}_i;s_j]\)为隐藏状态,\(c^{t-1}\)为cell状态。最终相似度的得分为
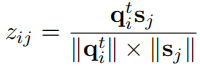
目标函数与模型训练
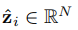 表示对于\((\zeta_i,?)\)每个候选(冷启动)物品的分数。对其应用softmax得
表示对于\((\zeta_i,?)\)每个候选(冷启动)物品的分数。对其应用softmax得
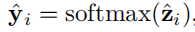
\(\hat y _i\)表示每个候选(冷启动)物品是序列\(\zeta_i\)下一个点击物品的可能性。最终损失函数为
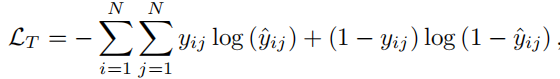
整个算法流程为

结果
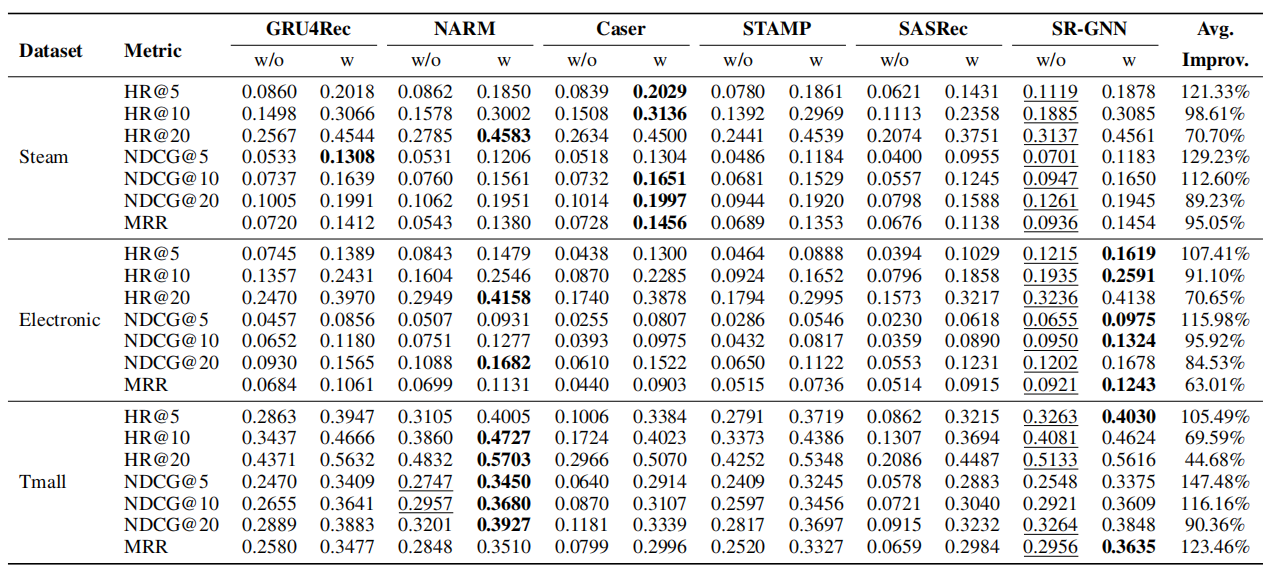
本文共使用到三个数据集,冷启动物品为分别在三个数据集中采样20%的物品,这些是交互最少的下一个点击物品。作者将原始模型和集成元学习的模型作为对比,都有较大提升。
总结
本文主要利用了元学习来缓解序列推荐的冷启动问题,与之前方法不同的地方是,只用到了用户与物品的交互数据,整体框架图如下。这是一个比较通用的框架,可以很好地与其它推荐模型融合。文章中使用到的一些数据增强、预训练等trick值得借鉴。