Disentangling User Interest and Conformity for Recommendation with Causal Embedding论文笔记
动机
本文是2021年WWW上的一篇论文。现在的推荐系统模型大多是基于用户与物品的交互训练的,然而用户与物品的交互可能是因为用户对该物品感兴趣,亦或是该物品具有很高的流行度,用户的从众性(conformity)促使他与该物品产生交互。因此我们可以了解到流行度更高的物品通常会与更多的用户产生交互,但是这些用户可能并非真的是对该物品感兴趣,更多是因为这个物品很热门。这就产生了用户从众性影响用户真实兴趣的问题,现有解决该问题的方法通常是消除流行性偏差,重新赋予物品权重或用一小部分无偏数据进行训练,但是这些方法都忽略了一个问题:交互的不同原因被绑定在一起(可以理解为促使交互的兴趣和从众性被绑定在一起)。本文提出了一个通用的框架DICE,可以将交互的原因分离,及分别学习用户(物品)兴趣和从众性的表示,同时它还保证了推荐模型的鲁棒性和可解释性。此框架主要针对的是训练数据和测试数据不是独立同分布的情况。消除流行性偏差是很有必要的,否则推荐系统更容易推荐流行的物品,忽略流行度低的物品。
算法
该框架大致可分为三部分组成因果嵌入(Causal Embedding)、解构表征学习(Disentangled Representation Learning)、多任务课程学习(Multi-task Curriculum Learning)。
Causal Embedding
点击产生的来源可分为两部分:1.用户对物品属性的兴趣。2.用户对物品流行度的盲从性。
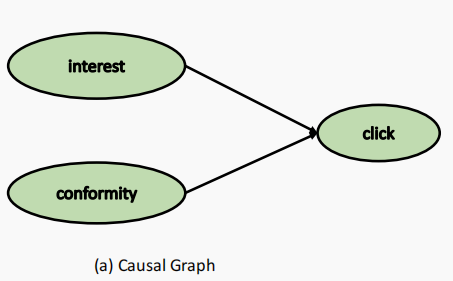
结构因果模型SCM可表示为
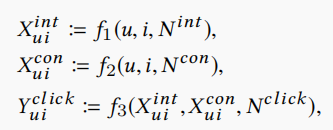
用户(物品)由两部分表示组成,分别为interest和conformity。
\(X_{ui}^{int}\)可以看作用户与物品的interest matching score,在本文中采用内积的方式得到,即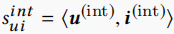 。
。
\(X_{ui}^{con}\)可以看作用户与物品的conformity matching score,在本文中采用内积的方式得到,即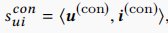 。
。
\(Y_{ui}^{click}\)是加性模型,将上面两部分得分相加得到,即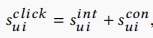 。
。
Disentangled Representation Learning
要分别训练出用户(物品)的interest embedding和conformity embedding需要从原始数据中分离出各自的训练数据,这里文章中称为Cause-specific Data。这里设置\(M^I\)为interest得分矩阵,\(M^C\)为conformity得分矩阵,形状均为M×N,M是用户数量,N是物品数量。下面涉及到一些因果推理的知识,根据对状结构的性质,在上面的因果图中,如果click未知,则interest和conformity互相独立,但是如果click已知,则interest和conformity呈负相关。这里举一个例子更容易理解这个性质,假设一个人是否受欢迎取决于它的外貌和脾气。外貌和脾气通常是不相关的,受欢迎程度是外貌和脾气的对撞。如果一个人受欢迎但是并不好看,那么他大概率脾气很好。如果一个人长得好看但是不受欢迎,那么他很有可能脾气很差。根据以上性质,我们可以得到两种情况:
1.用户与a有交互,与b无交互,且a比b有更大的流行度。在这种情况下,我们无法得出用户对a的兴趣是否比b更大,因此我们只能得出以下两个不等式。
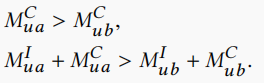
2.用户与c有交互,与d无交互,且d比c有更大的流行度。在这种情况下,我们由上面的对撞效应可以得出用户对c更感兴趣,因此能得出以下三个不等式。
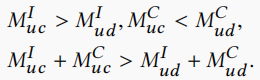
我们使用\(O_1\)表示第一种情况的数据,\(O_2\)表示第二种情况的数据。下面需要四个任务来学习用户与物品的embedding。
Conformity Modeling
在数据集\(O_1\)和\(O_2\)中,我们都获取了关于conformity的不等式表示,因此我们可以得到conformity部分的损失函数
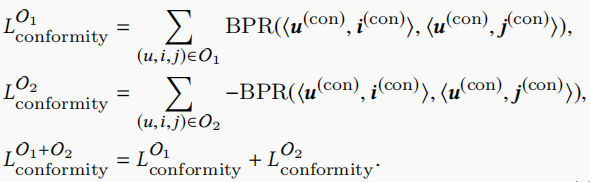
Interest Modeling
在数据集\(O_2\)中,我们获取了关于interest的不等式表示,因此我们可以得到interest部分的损失函数
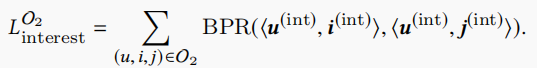
Estimating Clicks
这部分是推荐系统的主要目标,我们结合两部分的原因去估计点击,有以下损失函数
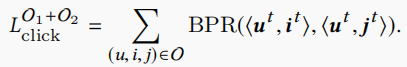
其中
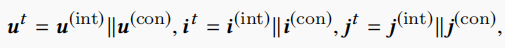
Discrepancy Task
Discrepancy Task执行对embedding的直接监督,强制interest和conformity分离。可以通过最大化用户(物品)interest和conformity嵌入的L1距离、L2距离、距离相关系数来实现。
下图展示了这四个任务。
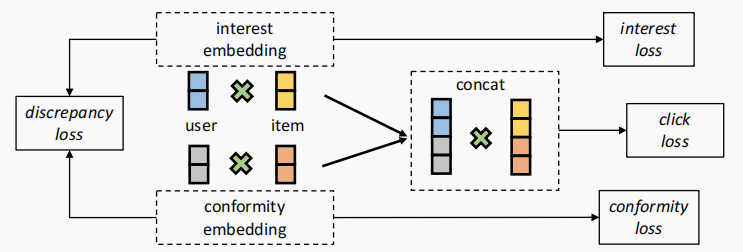
Multi-task Curriculum Learning
多任务学习将以上的损失联合起来
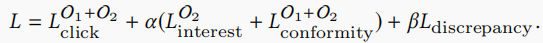
其中\(\alpha\)和\(\beta\)是超参数。
为了得到较高置信度的因果模型,作者使用PNSM负采样方法,假设与用户有交互的正样本流行度为p,我们抽取的负样本流行度需要大于\(p+m_{up}\)或小于\(p-m_{down}\),其中\(m_{up}\)和\(m_{down}\)是正的边缘值。
课程学习是一种从易到难的学习方法,可以通过降低边缘值和\(\alpha\)来实现。在\(m_{up}\)和\(m_{down}\)值较大时,模型有较高的置信度,因此此时的学习是简单的,之后通过降低边缘值和损失权重\(\alpha\)来实现增大学习难度。
结果
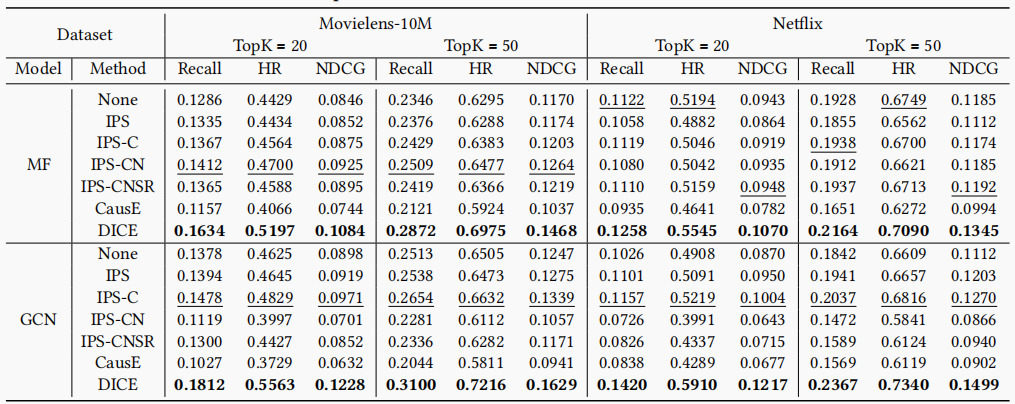
作者对数据集进行了干预处理,60%的数据使用的是原数据,剩下的40%数据从物品中以等概率的可能性抽取(物品采样的可能性为其流行度倒数,即流行度大的物品被采样的可能性降低)。训练集:验证集:测试集=70(60%原始,10%干预):10(10%干预):20(20%干预)。将本文提出的DICE与之前的sota因果推荐模型对比,DICE均取得了最好的效果。
总结和展望
本文主要讲的是消除流行性偏差的一个方法,提出了一个新的因果推荐框架,用于分离用户与物品交互的原因,即interest和conformity。该框架具有很好的解释性,并且有很好的鲁棒性去应对非独立同分布的数据。在未来的工作,可以将interest分解为更细的粒度,比如物品的价格、牌子等等属性。也可以将解构表示应用到更多的领域中。

