Self-supervised Graph Learning for Recommendation阅读笔记
动机
本文是2021年SIGIR上一篇文章。基于图卷积网络(GCN)的推荐系统模型大多数都有以下问题:1.稀疏的监督信号。2.倾斜的数据分布,高度的节点对表征学习影响更大。3.节点表示容易收到噪声交互的影响。在本文中作者通过在用户-物品图上引入自监督学习来改善GCN在推荐系统上的准确率和鲁棒性,将其称为Self-supervised Graph Learning(SGL),并应用在LightGCN模型上。SGL是模型无关的,并通过辅助自监督任务来补充监督任务中的信息以达成上述目的。
算法
SGL有两个关键点:1.数据增强。数据增强通过减少高度节点影响力来缓解度数倾斜问题,它为每个节点生成多个视图,多个视图增强模型的鲁棒性,抗干扰能力更强。2.对比学习。对比学习鼓励同一节点的不同视图相似,不同节点的不同视图不相似,它提供了额外的监督信号。下面内容都是围绕这两方面展开的。
图结构的数据增强
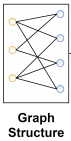
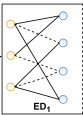
有三种方法,首先是node dropout节点丢弃。
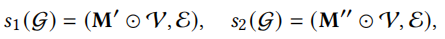
s1,s2是应用在图上的随机选择,M'和M''是屏蔽向量,屏蔽节点集合V中的一些节点以生成子图,在不同子图上每个节点有不同的表示,因此可以得到一个节点的多个视图,以下数据增强方法同理。
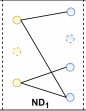
第二种方法是edge dropout边丢弃。
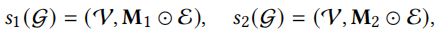
\(M_1\)和\(M_2\)是屏蔽向量。
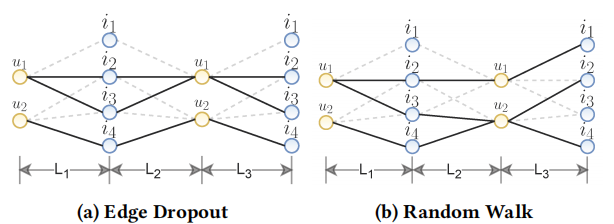
第三种方法是random walk随机游走
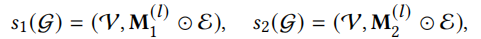
\(M_1\)和\(M_2\)是屏蔽向量。它与edge drop方法相似,但是上述node drop和edge drop在每个图卷积层都生成相同的子图,而random walk是在每一层都使用edge drop生成新的子图,可以通过该图更清楚看出random walk和edge drop的区别。
对比学习
通过上述数据增强,我们可以得到每个节点的多个视图,可以将一个节点的多个视图组合看作一个正样本对
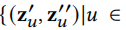
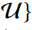
不同节点的视图组合看作负样本对
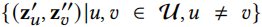
对比学习的目的就是最大化正样本对的一致性,最小化负样本对的一致性,用户部分的损失函数如下,个人觉得这个损失函数不完整,因为一个用户有两个视图表示,损失函数中分母部分仅考虑该用户其中一个视图与其它用户的其中一个视图组成的负例,另一个视图与其它用户视图组成的负例没考虑到,即没考虑到\(s(z^{'}_v,z^{''}_u)\)这种组合。
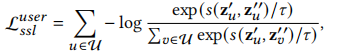
再考虑到物品部分的损失,对比学习损失可写为
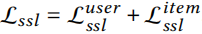
多任务训练
因为自监督训练任务是辅助主任务的(本次实验是LightGCN中的模型损失),因此总体模型损失可写为下式
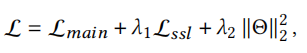
结果
在LightGCN中使用本文提出的SGL,结果如下图所示,有自监督辅助训练的LightGCN比原始LightGCN效果均有提升,而且edge drop方法通常情况下会更好,其次是random walk,node walk效果最不明显。node drop如果丢弃了一个度数高的节点,就会大幅度改变图结构,因此它非常不稳定。
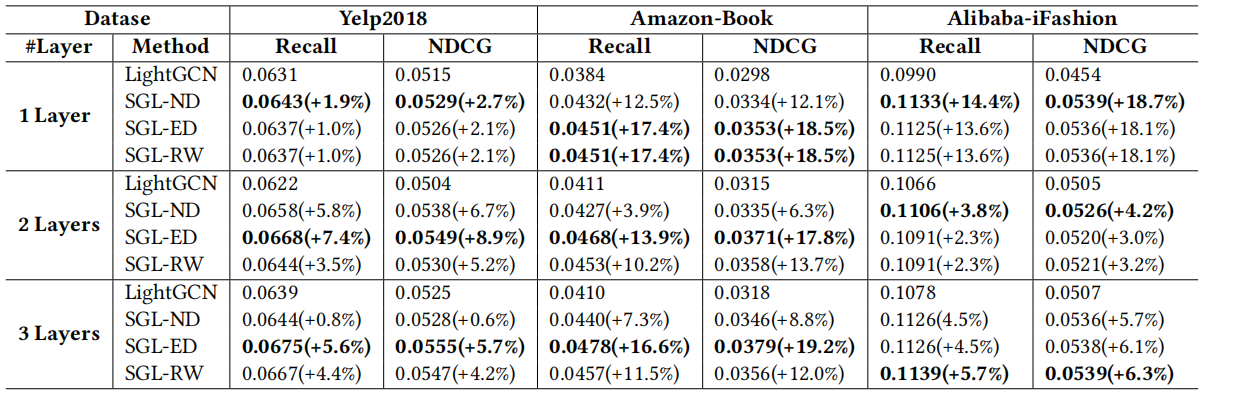
对于鲁棒性,下图Ratio是数据集被污染的比例,可以看出SGL-ED相比与原始LightGCN,即使数据集被污染了,它性能下降也没有LightGCN幅度大。
SGL也提升了对长尾物品预测的性能。
总结与展望
本文提出的SGL框架是模型无关的,它通过构建辅助任务补充监督信号,使模型拥有更好的性能和更好的鲁棒性,同时可以更高效地训练,也在一定程度上缓解长尾物品的推荐问题。或许未来可以像NLP中的bert一样构建出推荐系统中的预训练模型,根据不同的下游任务只需要微调这个模型就可以。SGL还具备挖掘难负例的能力,难负例可以提供大且有意义的梯度引导优化。未来可以探索更好的方法去挖掘这些有影响力的节点。还有一个有前途的方向是更充分地发挥自监督的潜力去解决长尾物品的推荐问题。
