DeepFM: A Factorization-Machine based Neural Network for CTR Prediction 阅读笔记
动机
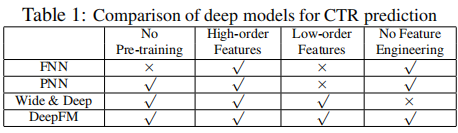
本文是2017年发表的一篇非常经典的推荐系统论文。本论文提出了一种新的模型DeepFM,解决了之前模型交叉低阶特征和高阶特征有很大偏差,或是需要耗费大量人力的特征工程的问题。它与之前谷歌提出的Wide&Deep模型相似,但是它不需要专家去进行特征交叉,是一个端到端的模型。它与当时先进的模型对比如下图所示,总而言之,它有以下优点:1、不需要预训练。2、可以交叉低阶特征。3、可以交叉高阶特征。4、不需要特征工程。
算法
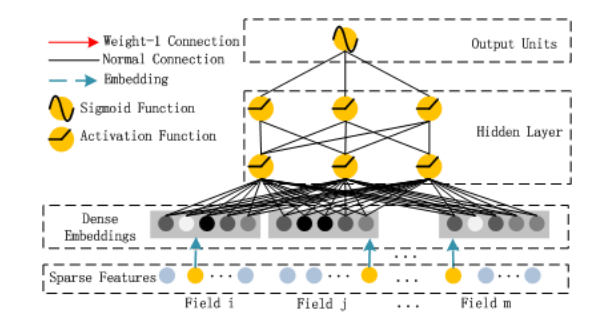
DeepFM可以分为两部分,一部分是FM组件,另一部分是Deep组件。因为本文是预测CTR,因此模型最终的预测形式是下面的公式。
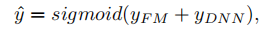
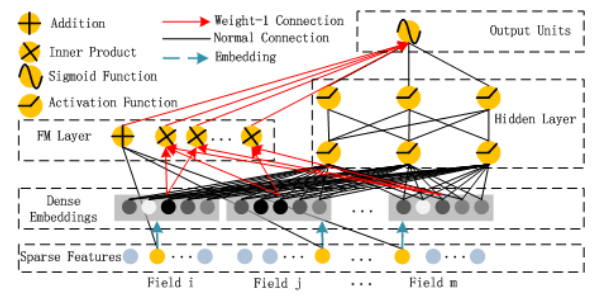
如图是DeepFM模型总体结构,左边是FM组件,右边是Deep组件,接下来分两部分详细介绍。
FM
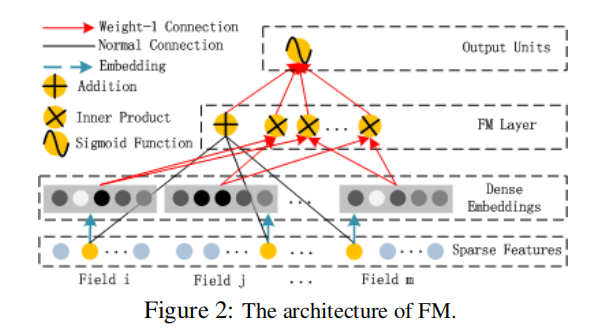
FM组件是一个因子分解机,用来学习用于推荐的特征交叉,它可以学习一阶特征交叉和二阶特征交叉,公式如下。
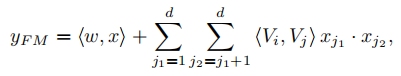
其中<w,x>计算的是一阶特征,其余部分计算的是二阶特征交叉。\(V_i\)是特征i的隐向量。
FM可以很好处理稀疏的数据,以往的模型计算特征i和j的交叉的前提是特征i和j必须同时出现,在FM中,特征i和j的交叉是通过它们的隐向量计算的。
Deep
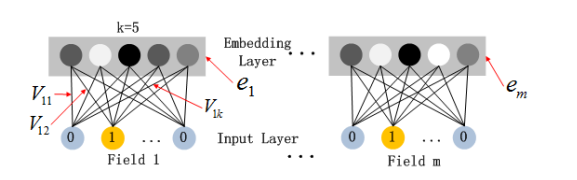
Deep组件部分是一个前馈神经网络,用于学习高阶特征交叉。因为原始数据是稀疏的,所以我们需要将每个不同的特征(原始各特征长度可以不相等)投影到一个对应的低维稠密的向量,这些低维向量长度相等,并且Deep部分的embedding和FM部分的embedding共享。embedding层具体结构如下,图中展示的是将原始特征投影到长度为5的向量中(每个特征都对应一个长度为5的向量)。
那么之后,我们得到的embedding层的输出可表示为如下
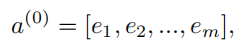
神经网络的传播可表示为
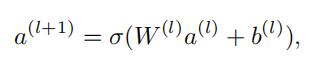
最终输出为
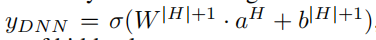
H为隐藏层层数。
结果
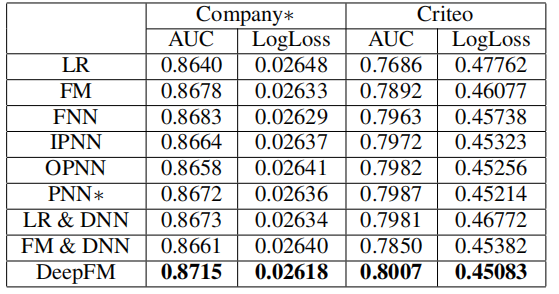
作者在两个数据集上做了实验,将当时最先进的模型和DeepFM模型进行对比,DeepFM在AUC和LogLoss两项指标上均取得最好的结果。
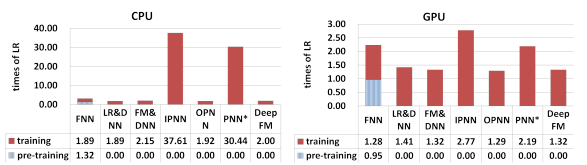
并且DeepFM训练效率非常高,这里时间是以LR模型训练时间为基准。
总结
DeepFM模型是Wide&Deep模型的改进版本,不仅让模型自动交叉特征,省去大量人力去人工交叉特征,而且让Deep部分和FM部分共享embedding层,这使模型同时学习了高阶特征交叉和低阶特征交叉。谷歌有一项数据统计,Wide&Deep模型AUC提升了0.275%,线上CTR提升了3.9%,在本次实验中DeepFM模型AUC和Logloss相比其余模型提升了至少0.37%和0.42%。尽管看起来似乎模型提升效果并不十分显著,但是这一点点的提升足以为一个大的公司增加上亿的收入。
