Ollama+DeepSeek+Dify本地知识库搭建指南
最近经常听到知识库构建这个事情,于是在网上学习了一下关于本地知识库搭建的知识,目的是提高内部信息检索速度,提高信息管理。于是用Ollama+DeepSeek+Docker+Dify搭建了本地知识库,以下是我学习总结,供需要的同学参考。关于Ollama+docker 搭建在我上一篇博客https://www.cnblogs.com/amberdyy/p/18716252中有总结,这里就不重复写了。
一 Dify介绍
Dify 是面向AI的应用工具,专注于帮助用户快速构建、部署和管理基于大语言模型(LLM)的AI应用。主要目标帮助用户轻松利用大语言模型来创建定制化的AI应用。
主要功能
- 快速构建AI应用:Dify提供了一个可视化界面,用户可以通过简单的配置和拖拽操作,快速创建AI应用,无需编写复杂的代码。它支持多种任务类型,如文本生成、问答、翻译、分类等,适用于不同的业务场景。
- 提示工程支持:Dify支持提示工程,用户可以通过界面设计和优化提示,提高模型的输出质量。它还支持少样本学习,用户可以通过提供示例来引导模型更好地完成任务。
- 数据管理:Dify支持上下文管理,用户可以为模型提供额外的背景信息或历史对话,帮助模型更好地理解任务。它还提供对用户输入和模型输出的分析功能,帮助用户优化提示和模型表现。
- 部署与集成:Dify支持一键部署,用户可以将构建的AI应用快速上线。它提供API接口,用户可以将AI应用集成到现有的系统或产品中。Dify支持多个大语言模型,用户可以根据需求选择不同的模型。
- 可视化与监控:Dify提供对模型性能和用户交互的实时监控功能,帮助用户了解应用的运行情况。它还通过反馈机制优化模型的表现,持续改进AI应用。
二 Dify的环境安装
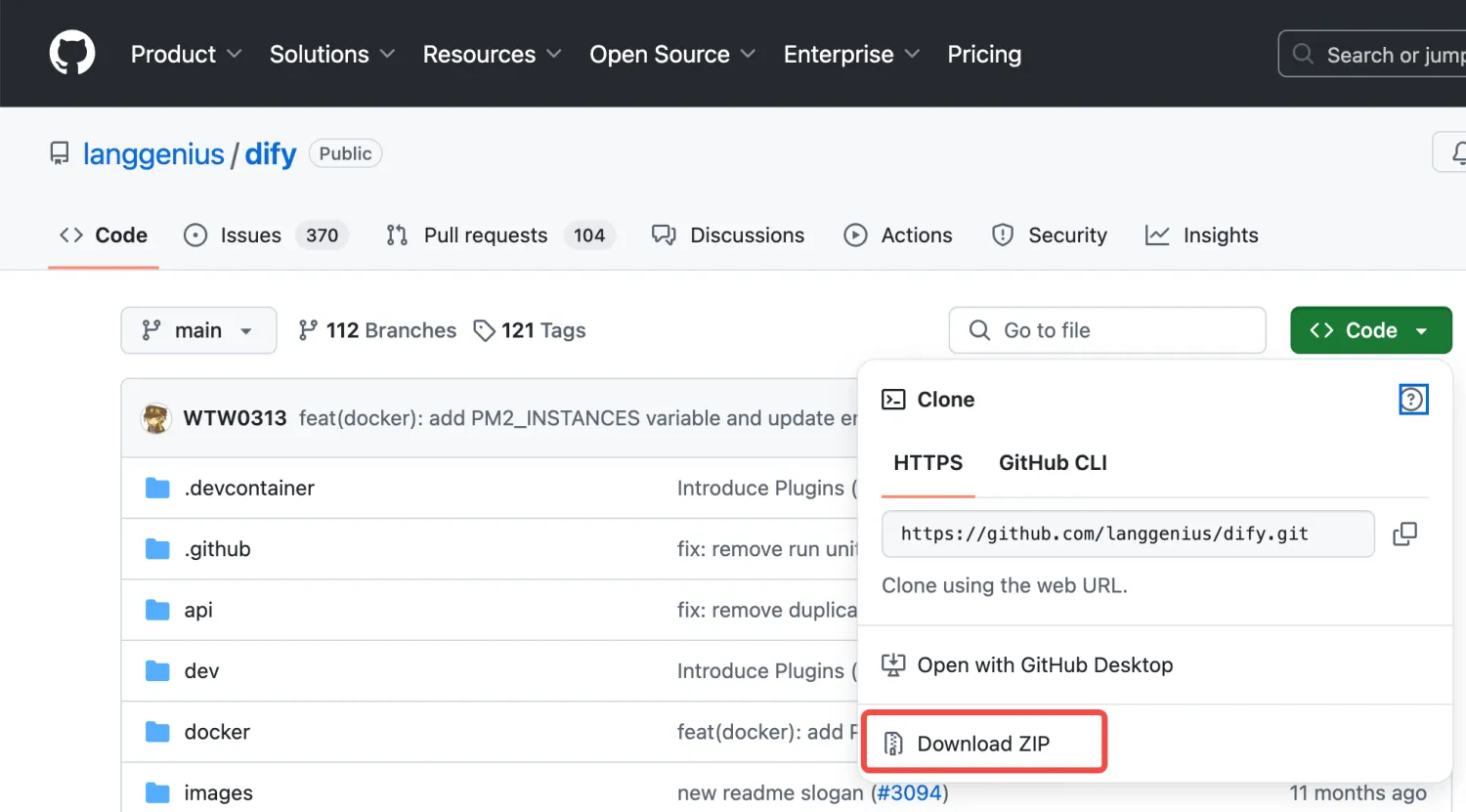
1.在浏览器中访问Github地址(https://github.com/langgenius/dify)后,下载Dify项目压缩包,如下图:
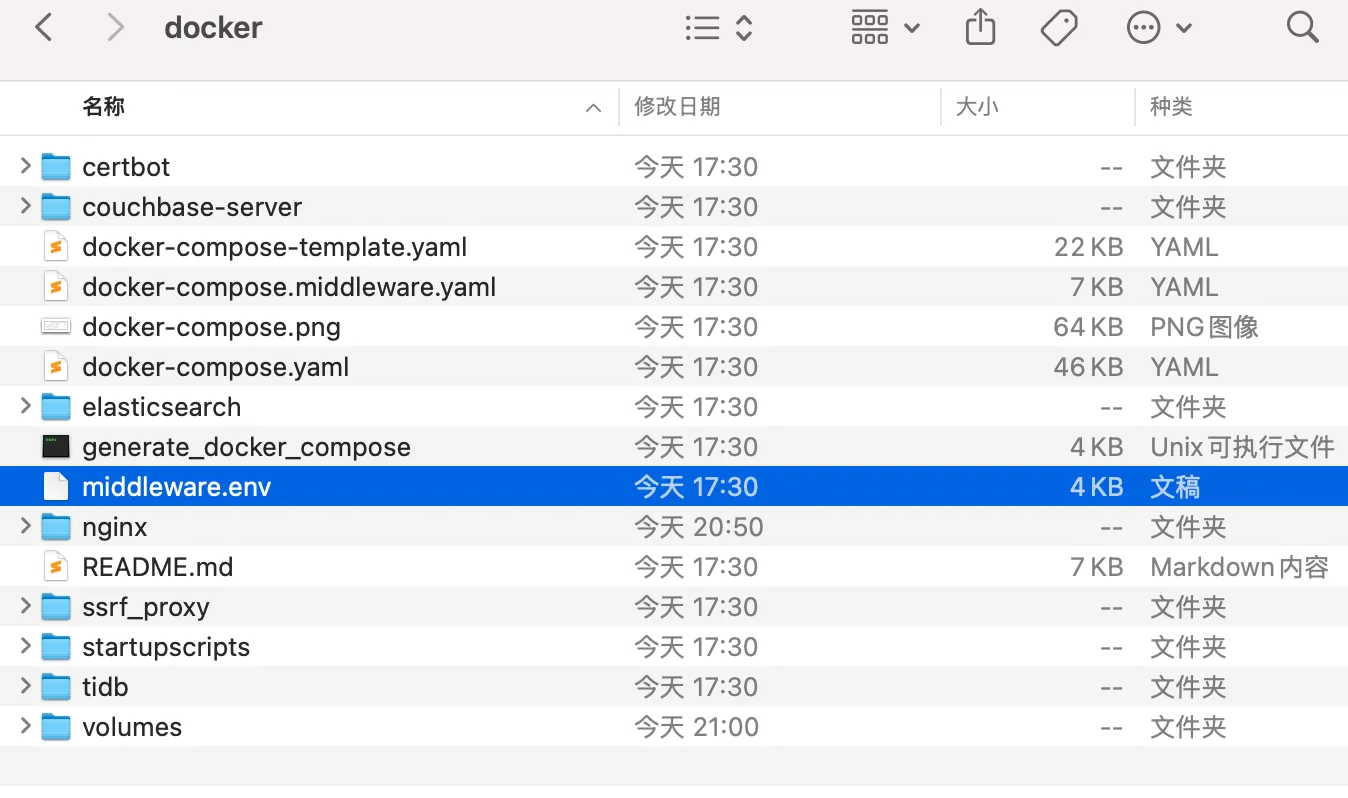
2.将压缩包解压以后,进入docker 目录下,将middleware.env.example”重命名为“middleware.env”
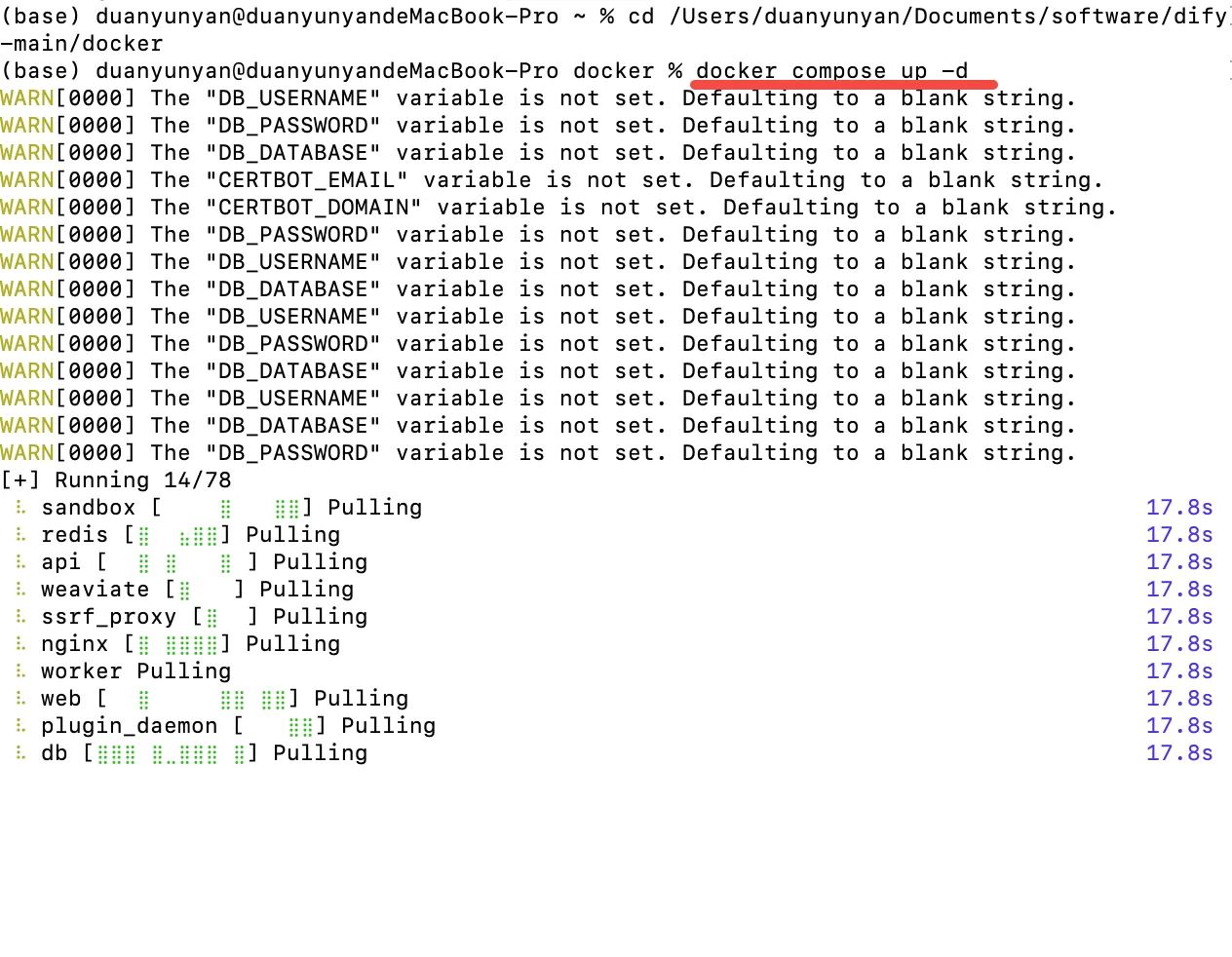
3.在终端,输入下面的命令运行docker环境
docker compose up -d
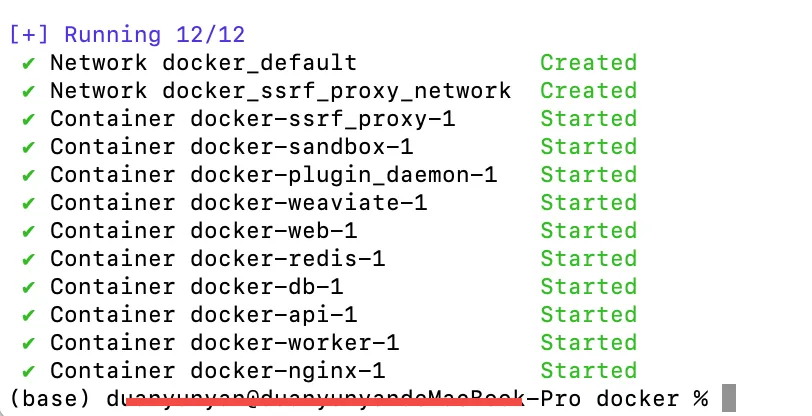
出现下面的代表启动了Dify所需要的所有容器环境。
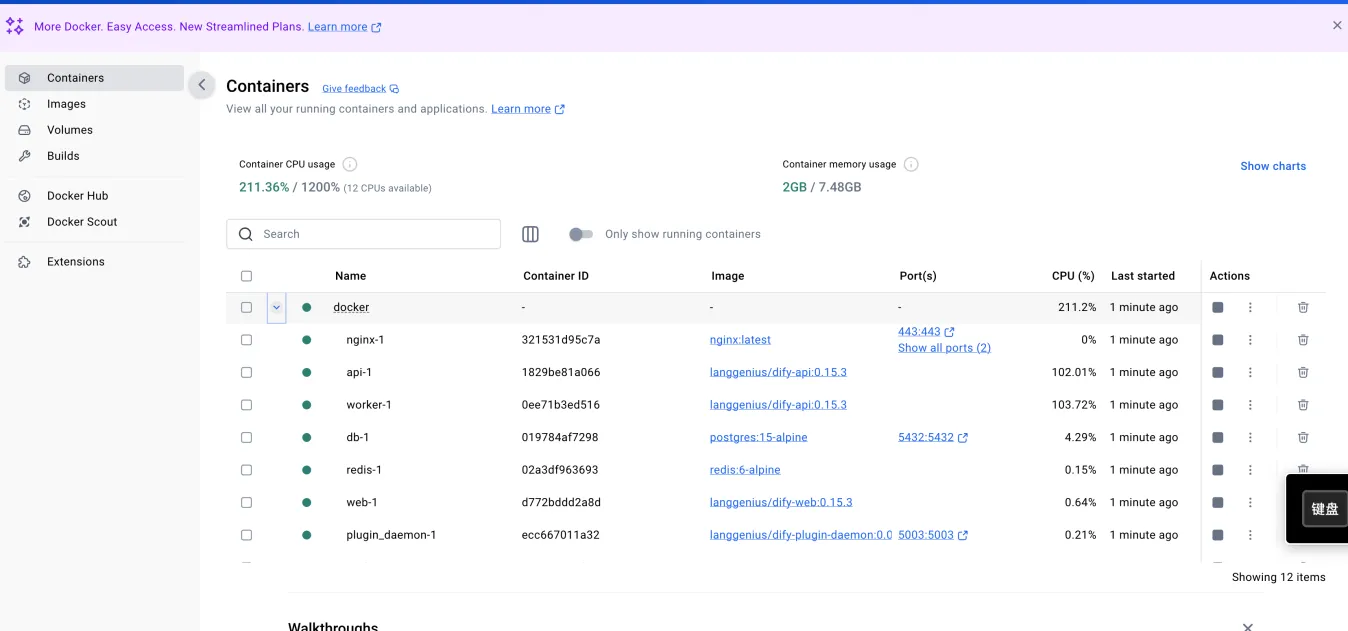
4.在桌面启动docker桌面客户端,可以看到所有dify所需要的环境都已经运行起来了,如下图:
二 安装Dify
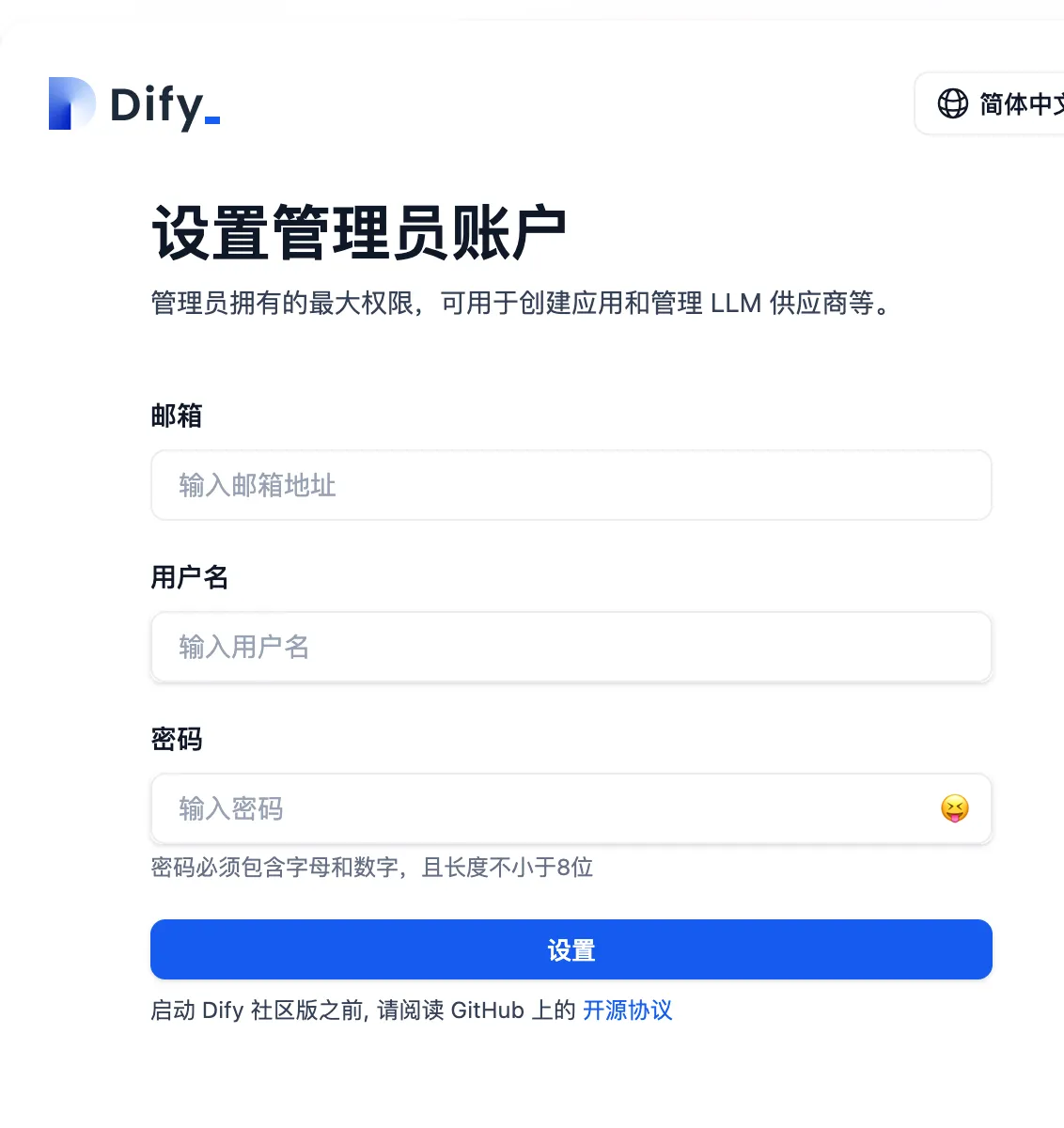
1.在浏览器地址栏中输入“http://localhost/install”,首次安装,需要设置,如下图:
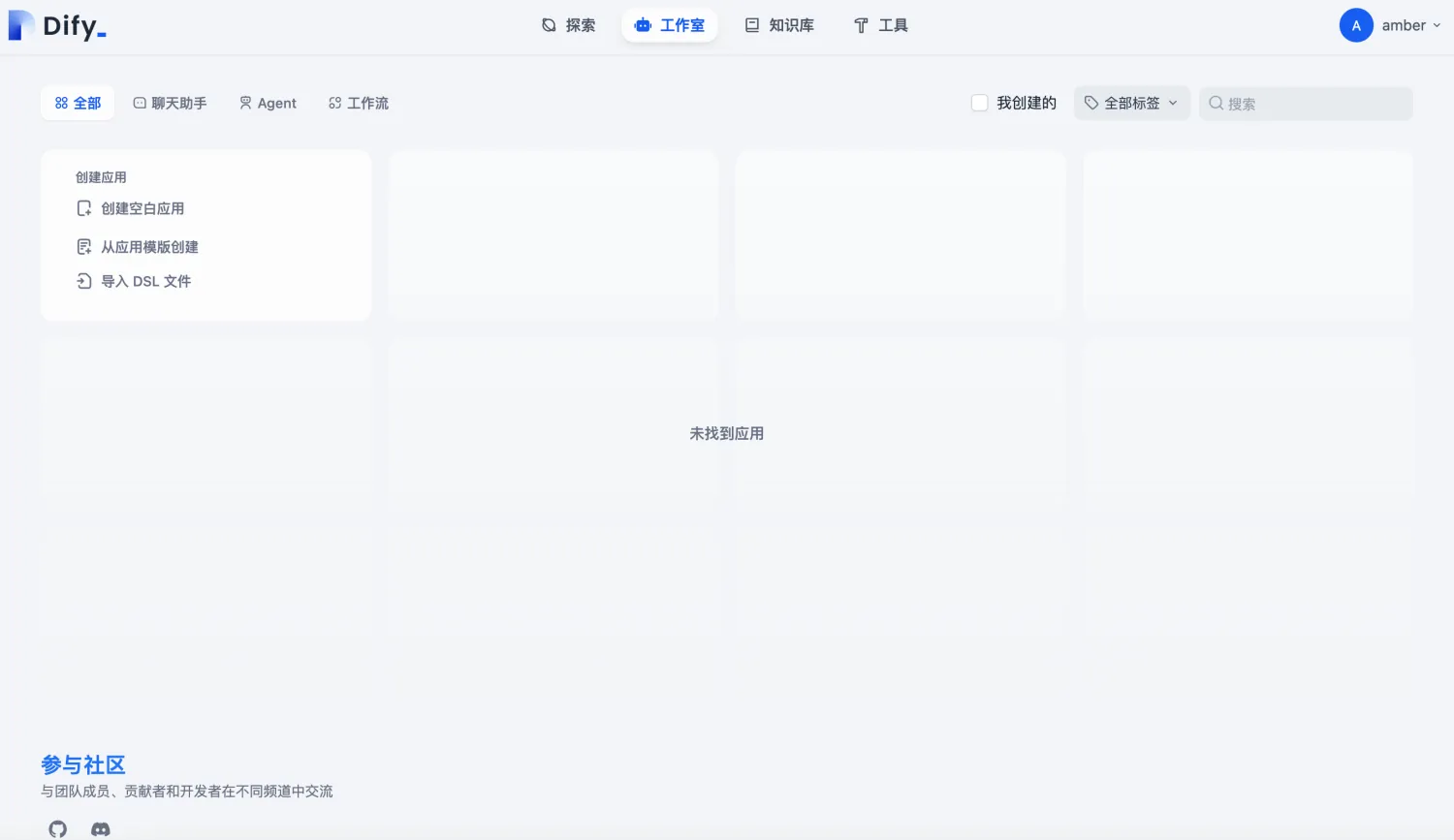
2.登陆成功进入主页,如下图:
四 将本地大模型与Dify进行关联
Dify 是通过Docker部署的,而Ollama 是运行在本地电脑的,得让Dify能访问Ollama 的服务。
1.配置Dify
在Dify项目-docker-找到.env文件,在末尾加上下面的配置:
# 启用自定义模型
CUSTOM_MODEL_ENABLED=true
# 指定 Olama 的 API地址(根据部署环境调整IP)
OLLAMA_API_BASE_URL=host.docker.internal:114342.配置大模型
1)在Dify的主界面 http://localhost/apps ,点击右上角用户名下的【设置】
2)在设置页面--Ollama--添加模型,如下:
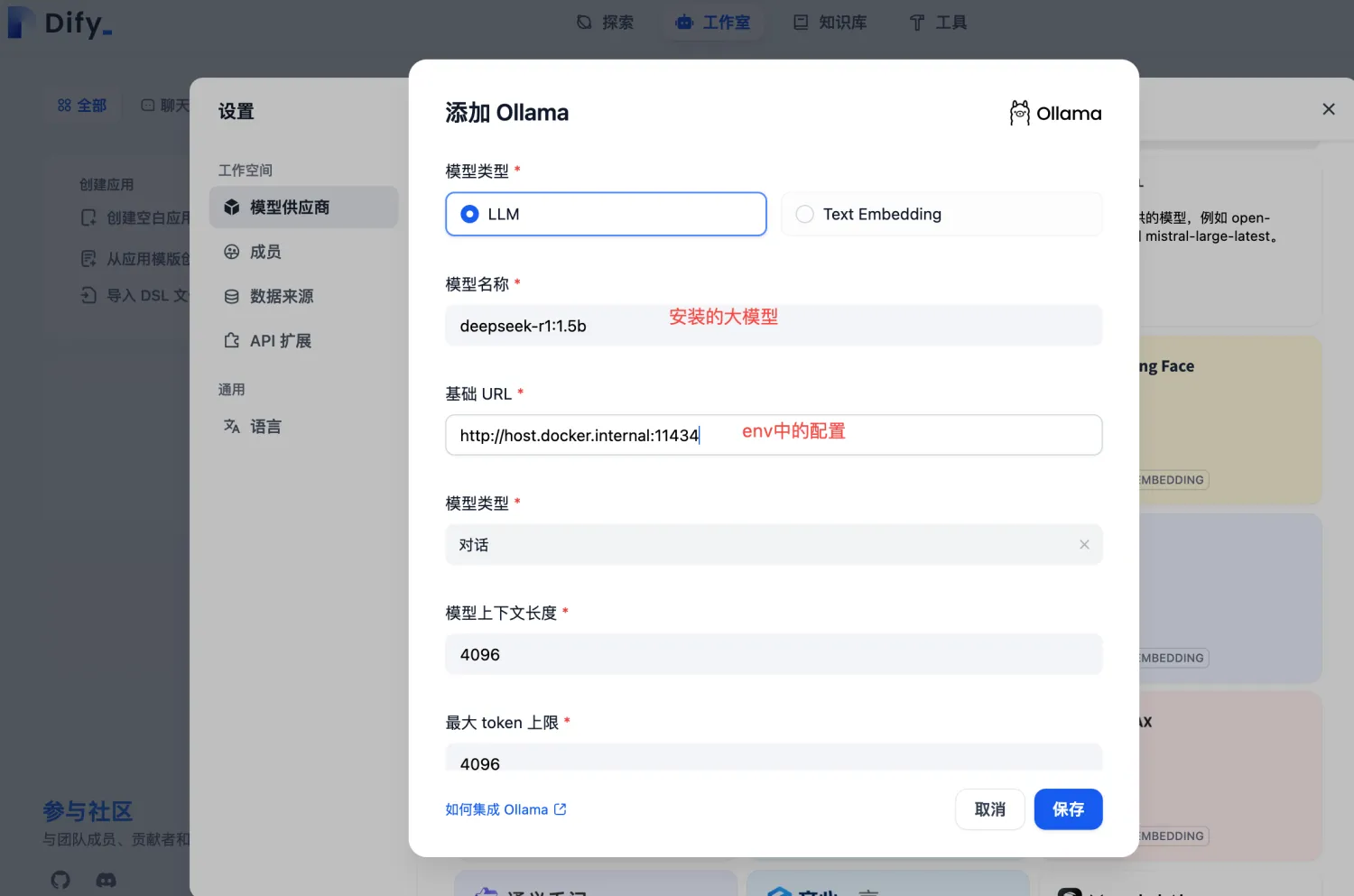
3)填写deepseek 模型信息相关信息后保存,如下:
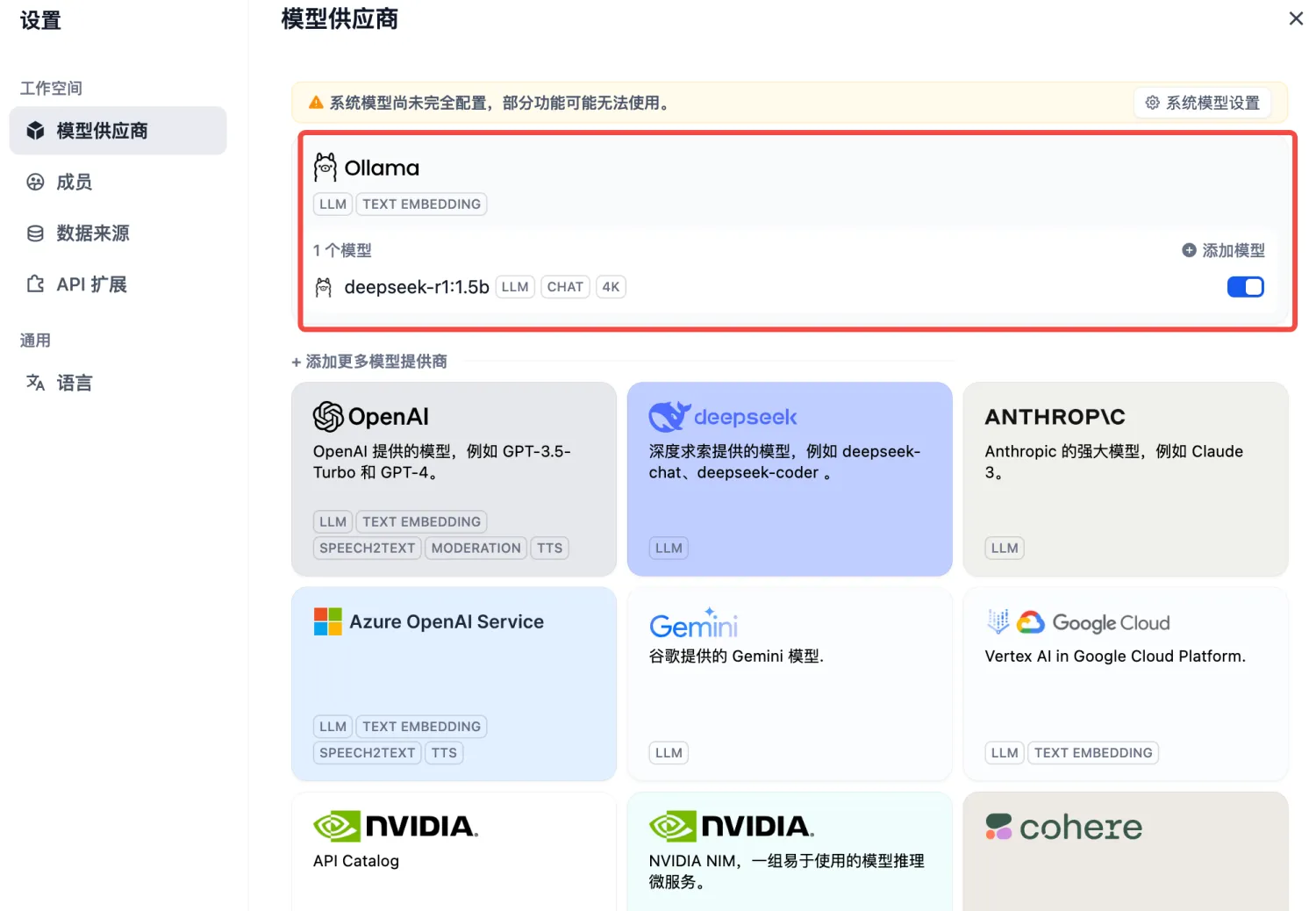
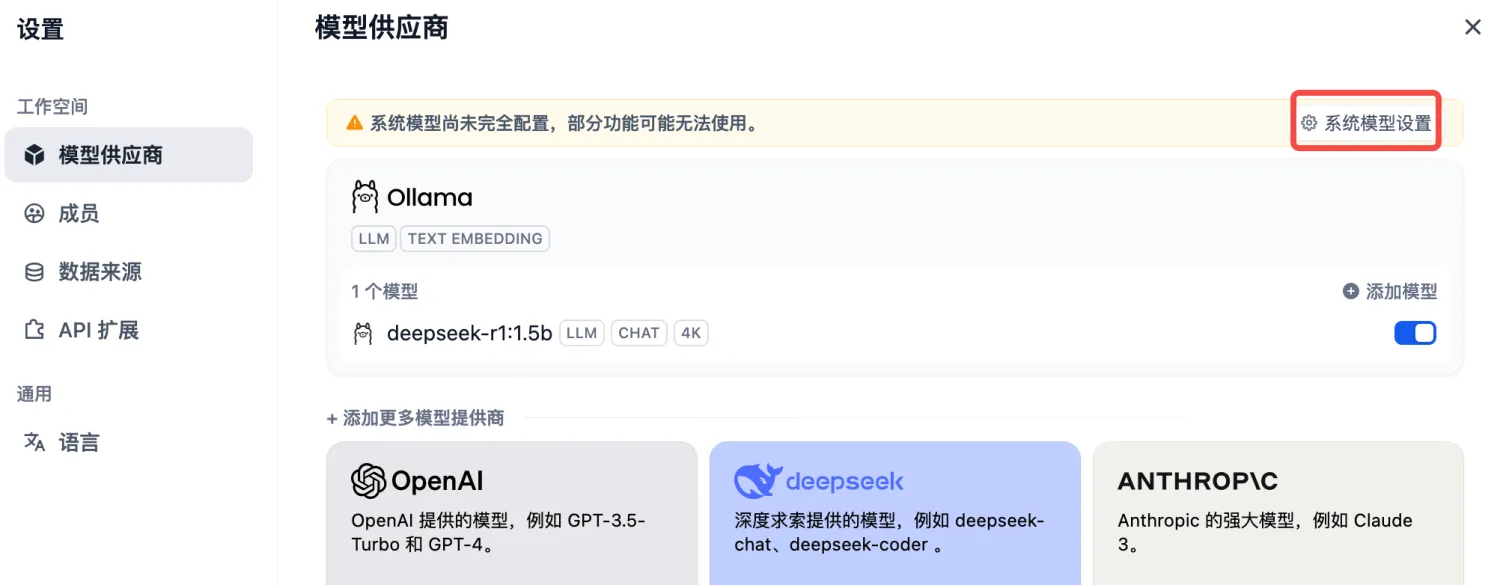
4)模型添加完成以后,刷新页面,进行系统模型设置。步骤:输入“http://localhost/install”进入Dify主页,用户名--设置--模型供应商,点击右侧【系统模型设置】,如下:
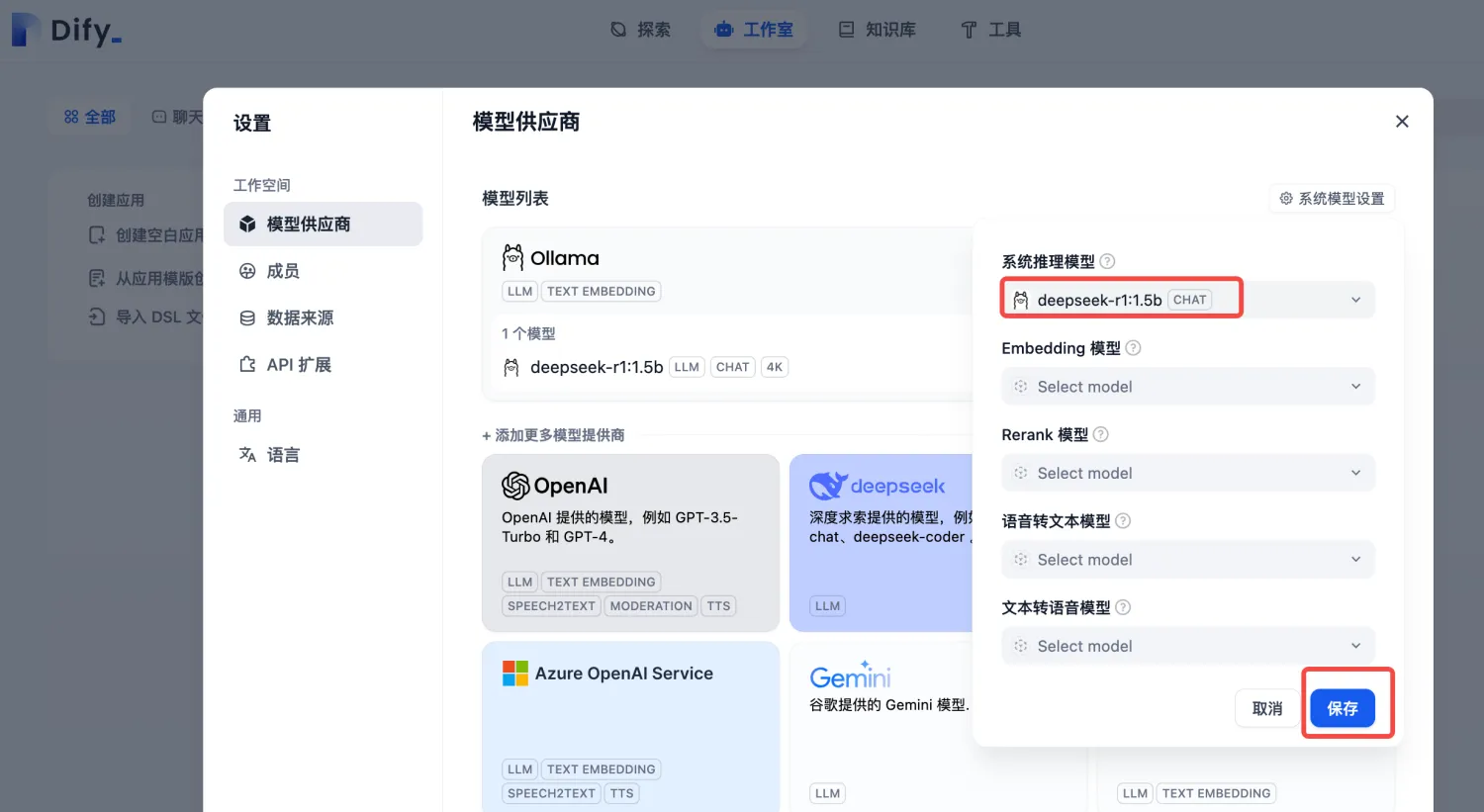
此时,Dify与前面部署的本地大模型关联起来了。
五 创建应用
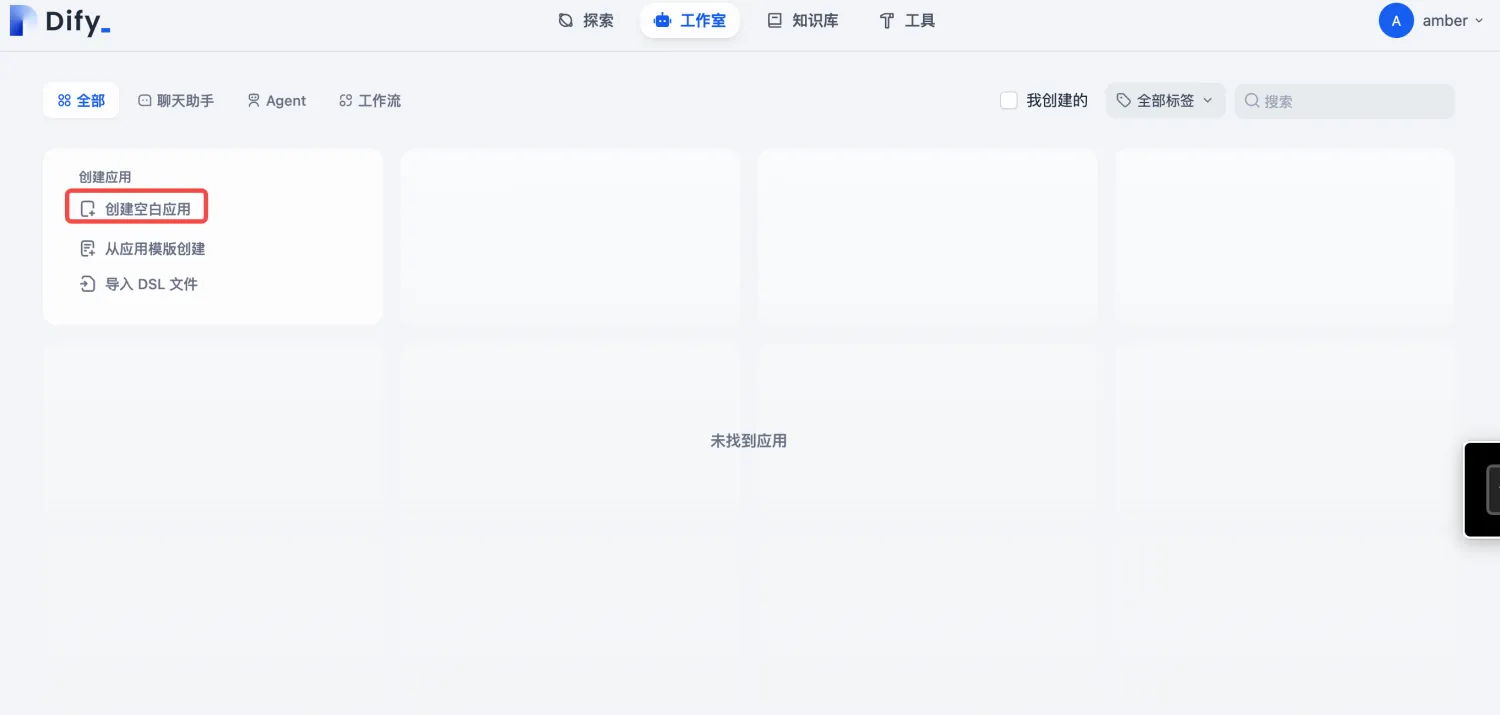
1.创建空白应用
进入Dify 主界面,点击【创建空白应用】,如下图:
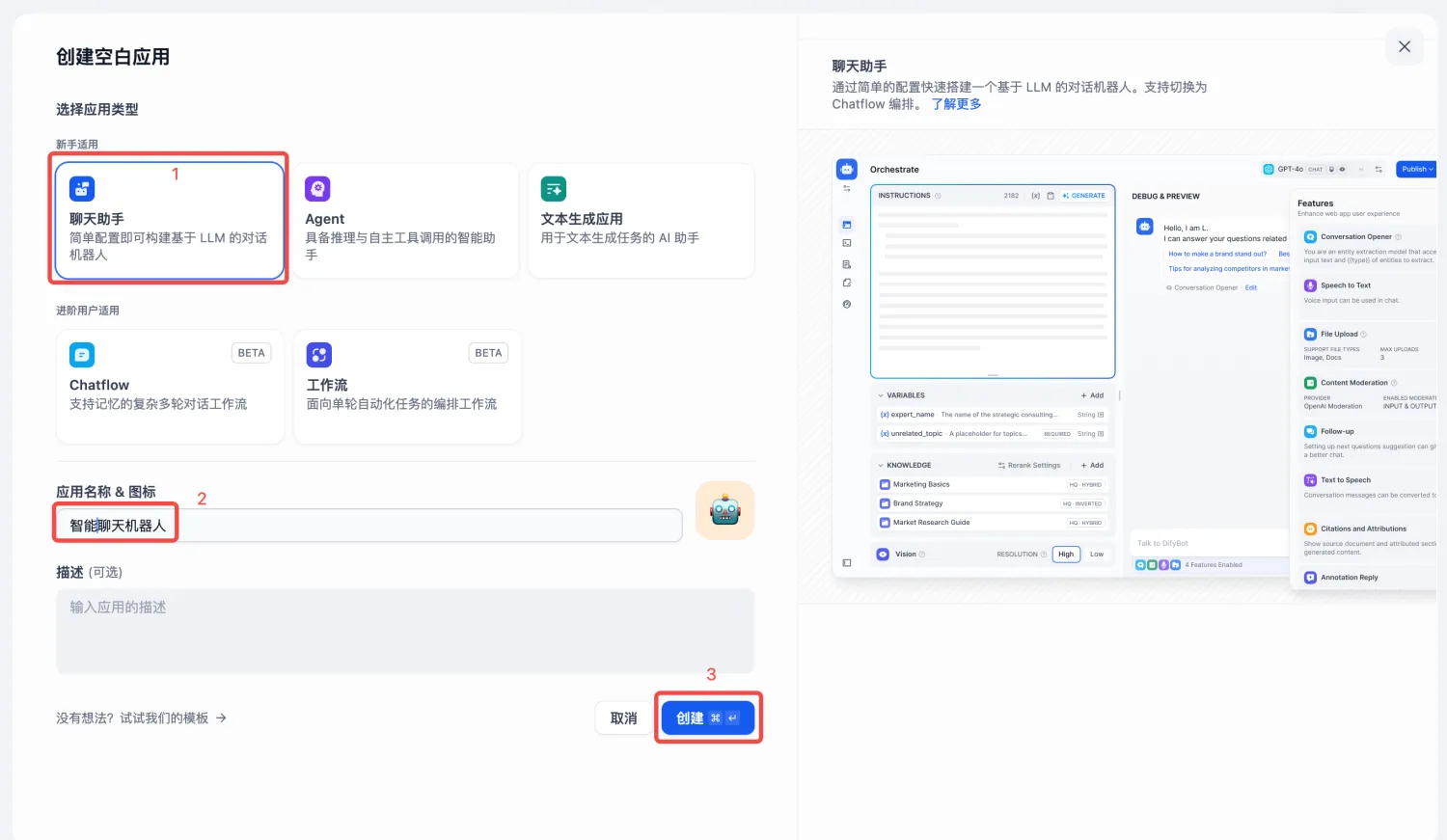
2.应用配置
选择【聊天助手】,输入自定义应用名称和描述,点击【创建】
3.配置大模型
右上角选择合适的模型,进行相关的参数配置
4.测试
输入英文,回复英文;输入中文,返回中文。此时说明Dify 与本地部署的DeepSeek大模型已经连通了
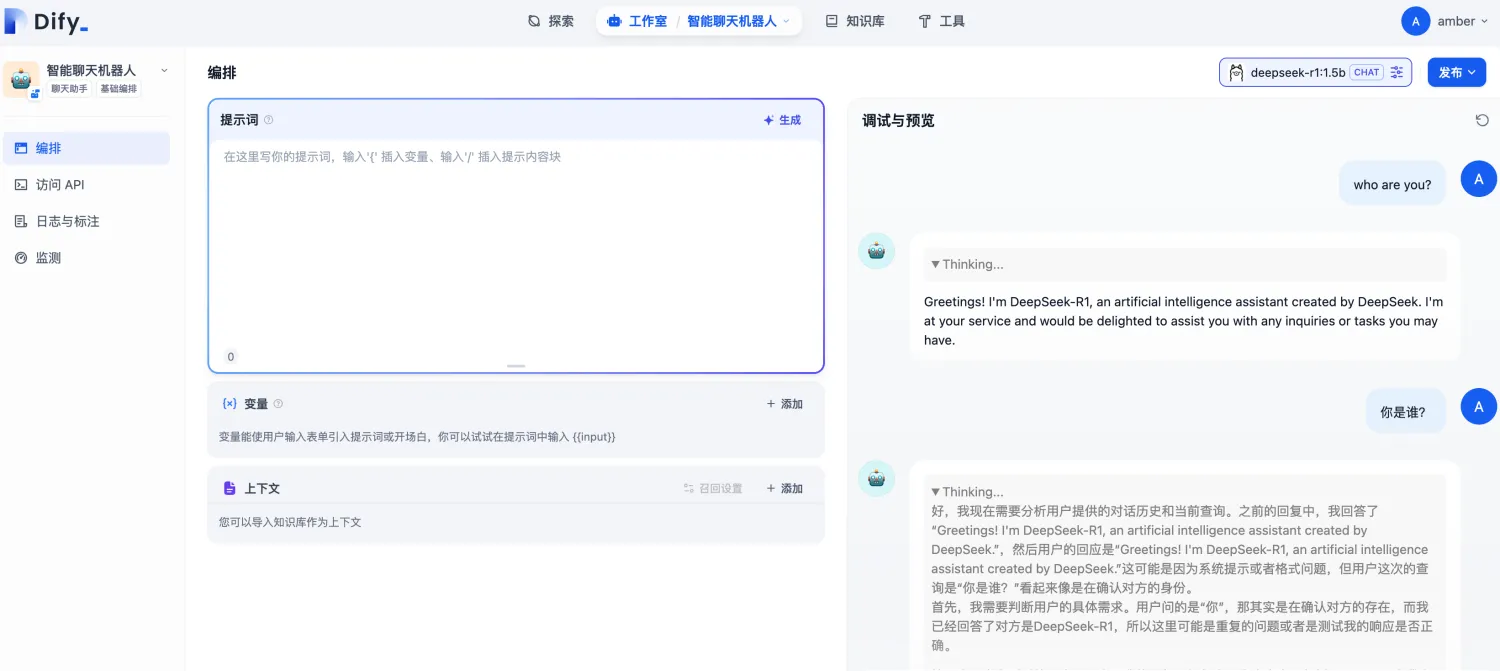
此时有个不足之处:如何让回答根据具体的背景材料去回答呢?此时就需要用到本地知识库了。通过将私有资料(文档,笔记等)上传到知识库,
让Dify在回答问题时结合这些材料作为上下文,这样就能给出更符合需要的答案了。
六 创建本地知识库
1.Embedding模型介绍
Embedding模型是一种将数据转换为向量表示的技术,核心思想是通过学习数据的内在结构和语义信息,将其映射到一个低维向量空间中,使得相似的数据点在向量空间中的位置相近,从而通过计算向量之间的相似度来衡量数据之间的相似性。
Embedding模型可以将单词、句子或图像等数据转换为低维向量,使得计算机能够更好地理解和处理这些数据。在NLP领域,Embedding模型可以将单词、句子或文档转换为向量,用于文本分类、情感分析。机器翻译等任务。在计算机视觉中,Embedding模型可以用于图像识别和检索等任务。
2.添加Embedding模型
点击右上角用户名--设置--模型供应商--右上角【添加模型】,填写相关配置信息如下:
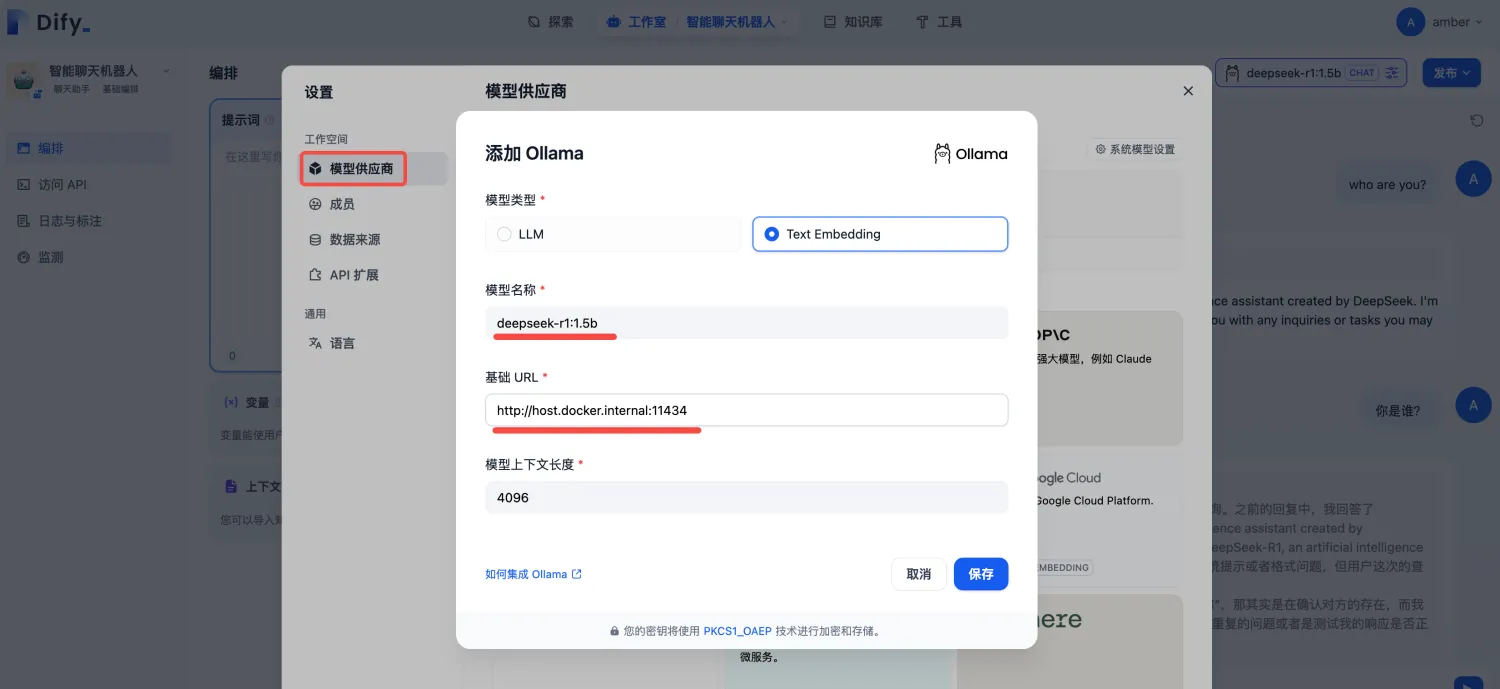
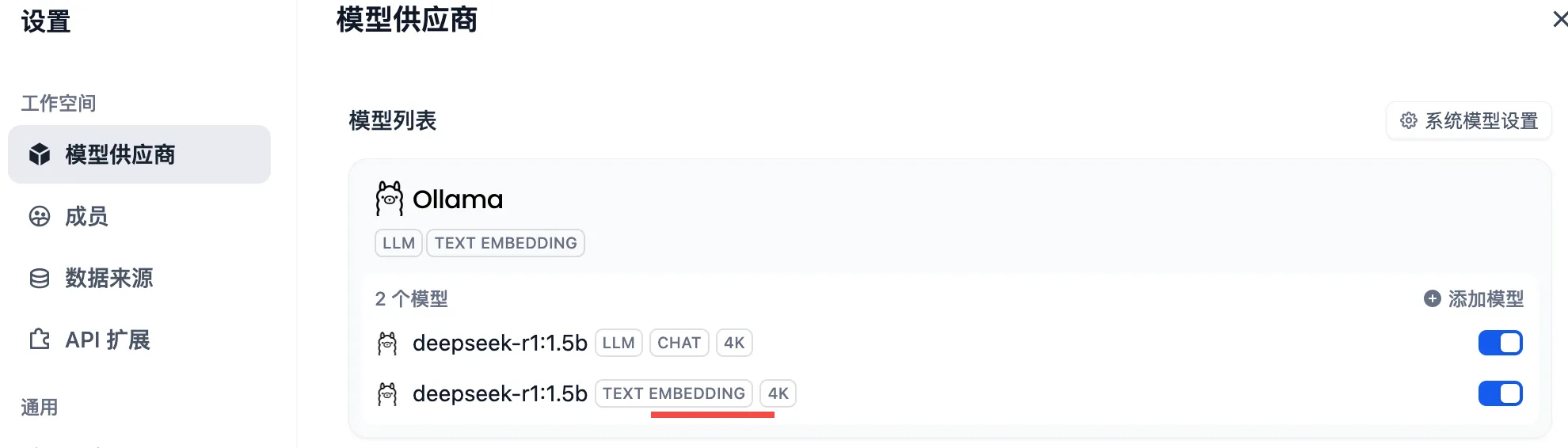
3.创建知识库
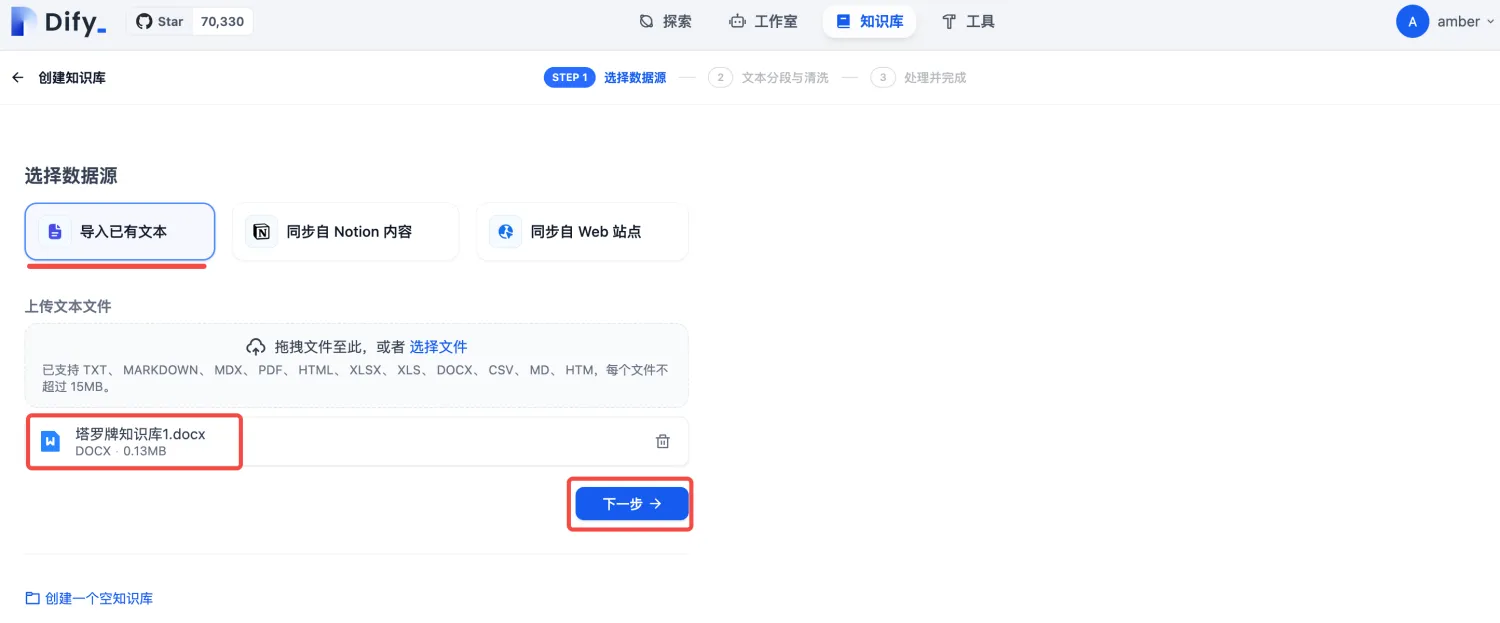
1)在Dify主界面,点击上方的【知识库】,点击【创建知识库】
2)导入已有文本,上传资料,点击【下一步】
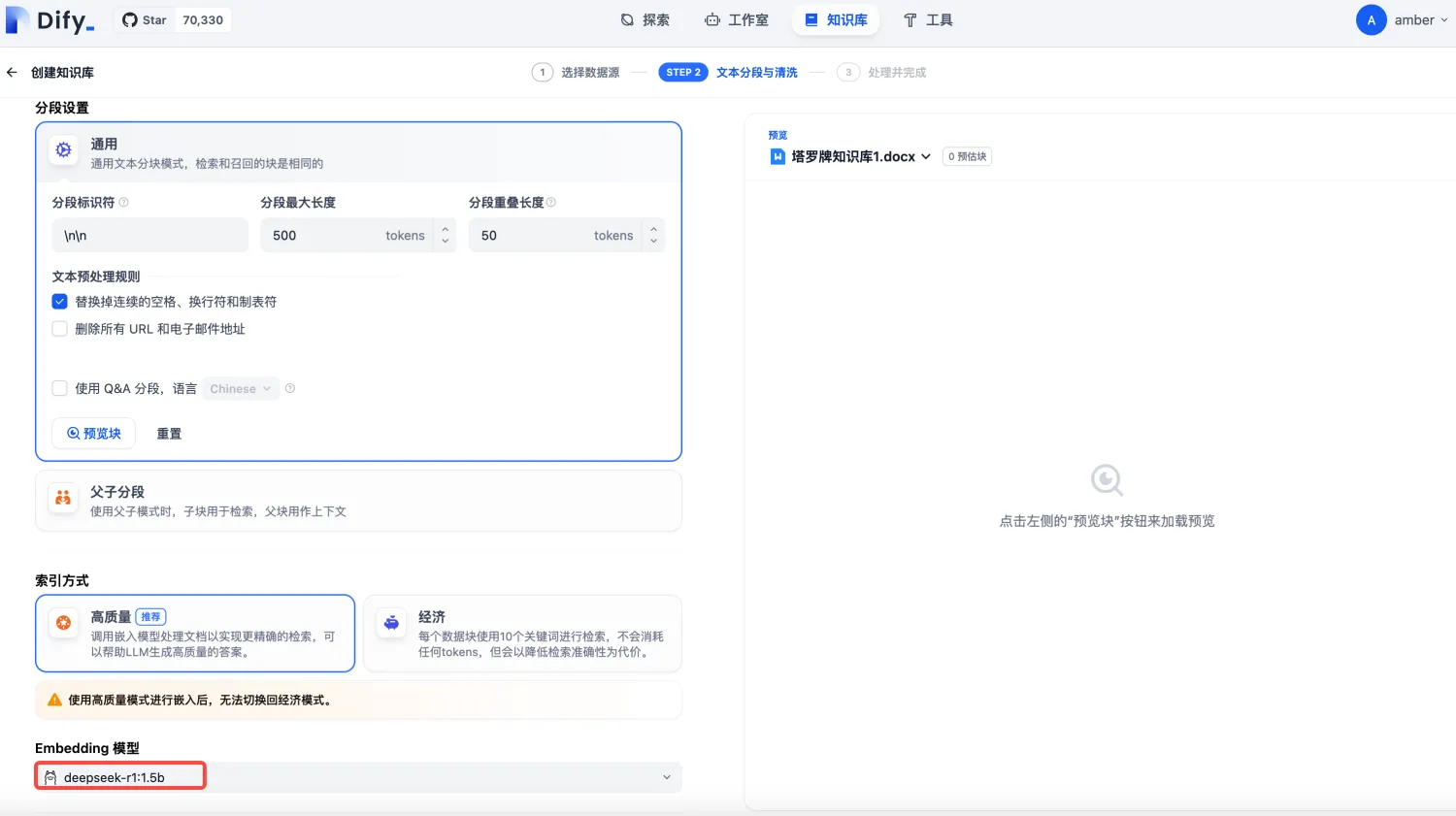
3)Embedding模型默认是前面配置的模型,参数信息配置完,点击保存即可
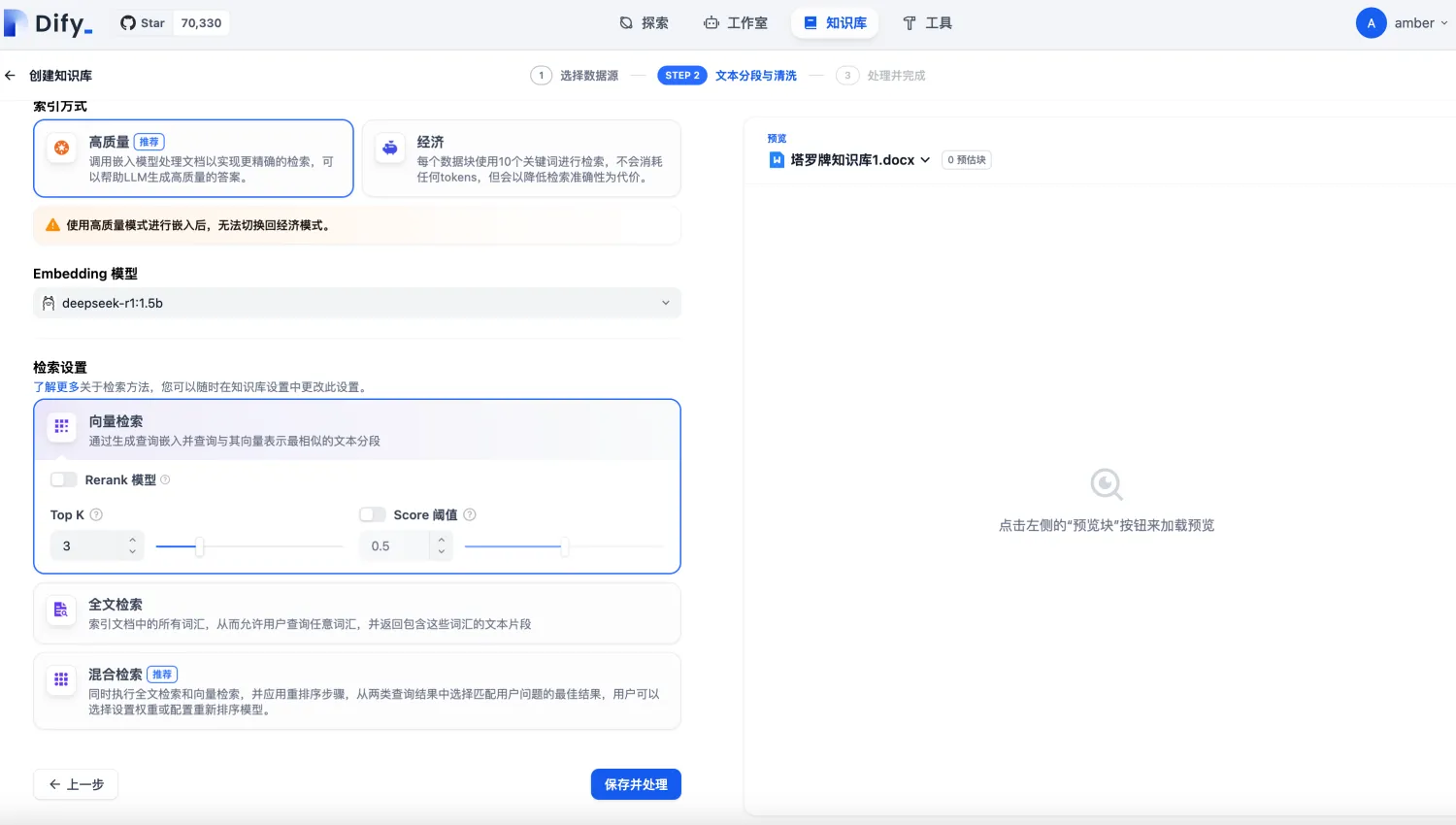
此时系统会自动对上传的文档进行解析和向量化处理,需要耐心等待几分钟。
4)创建成功以后,如下图,可以点击【前往文档】,查看分段信息,如下图:
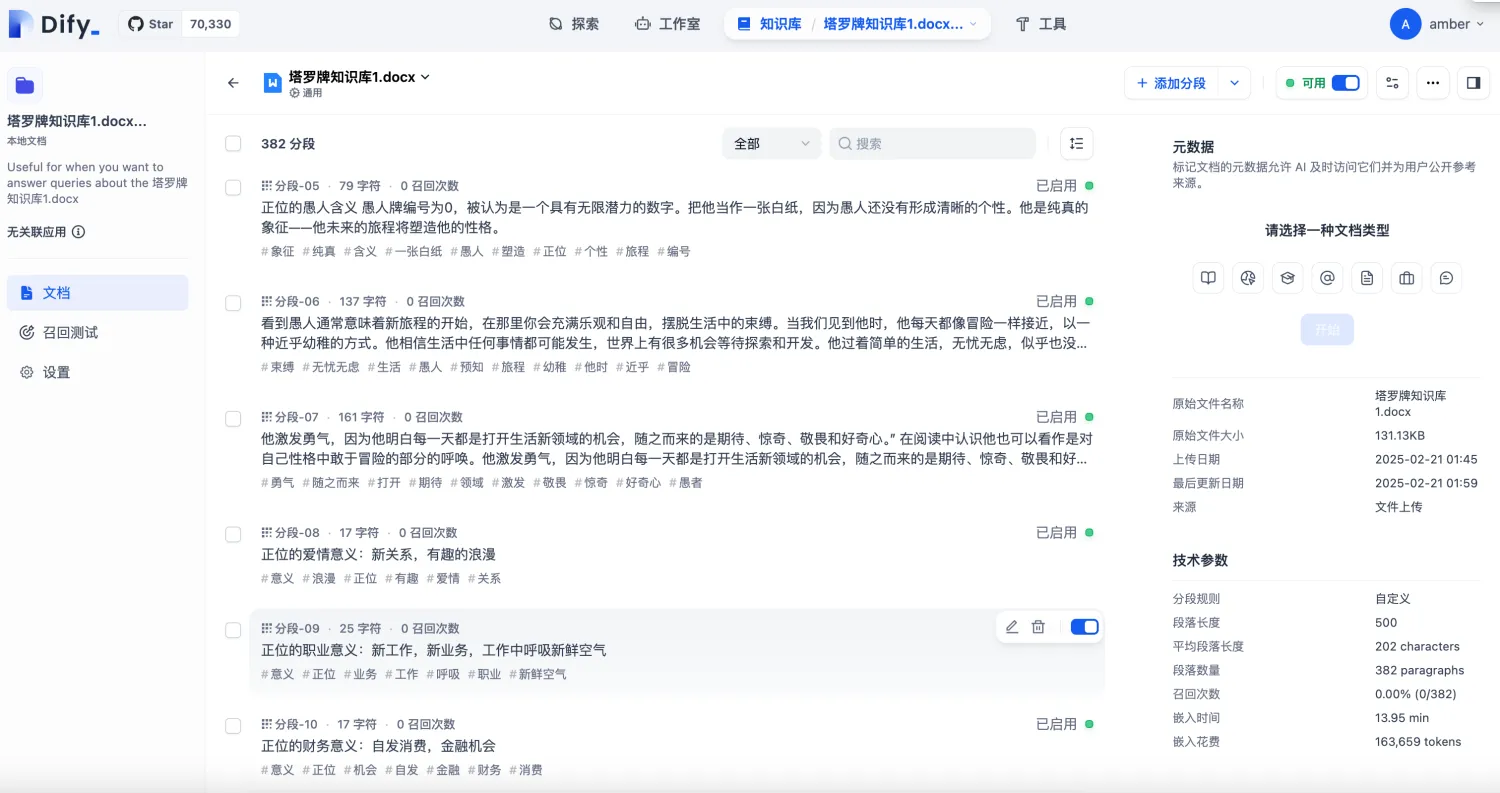
5)点击【通用】,可以看到分段信息,如下图:
七 添加知识库为对话的上下文
1.应用内添加知识库
在Dify主界面,回到刚才的应用聊天页面,工作室--智能聊天机器人--添加知识库,如下图:
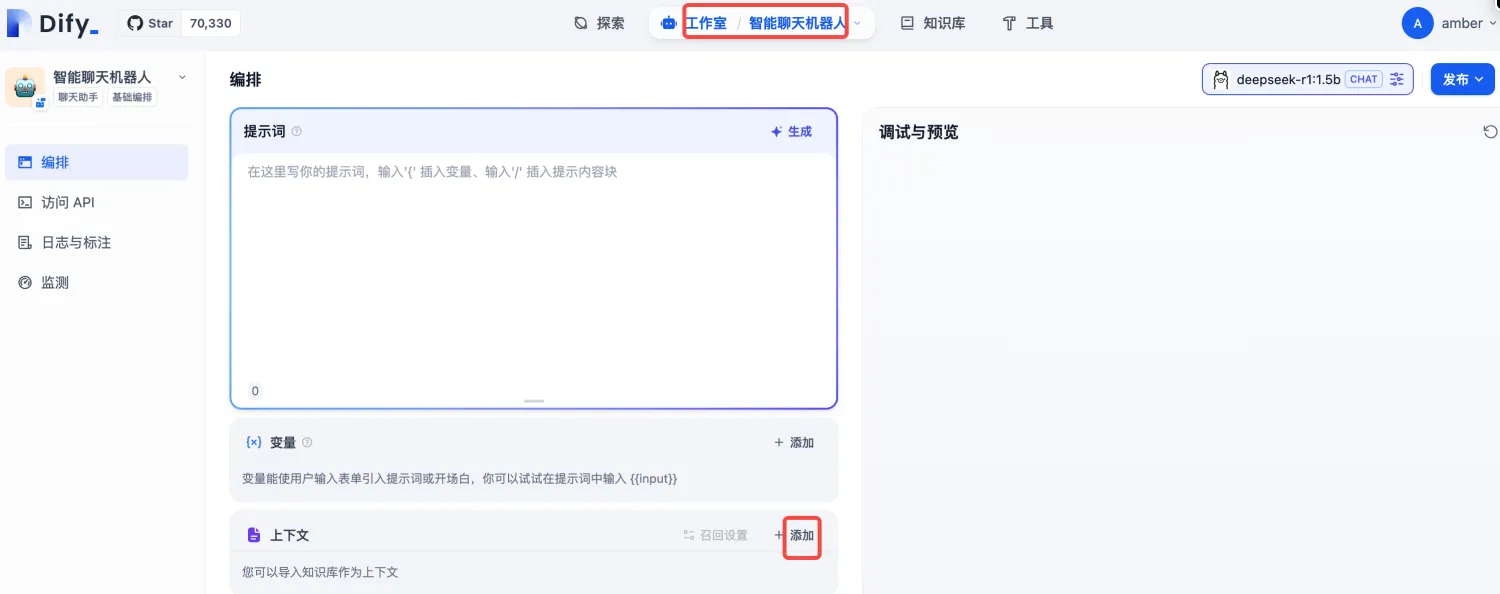
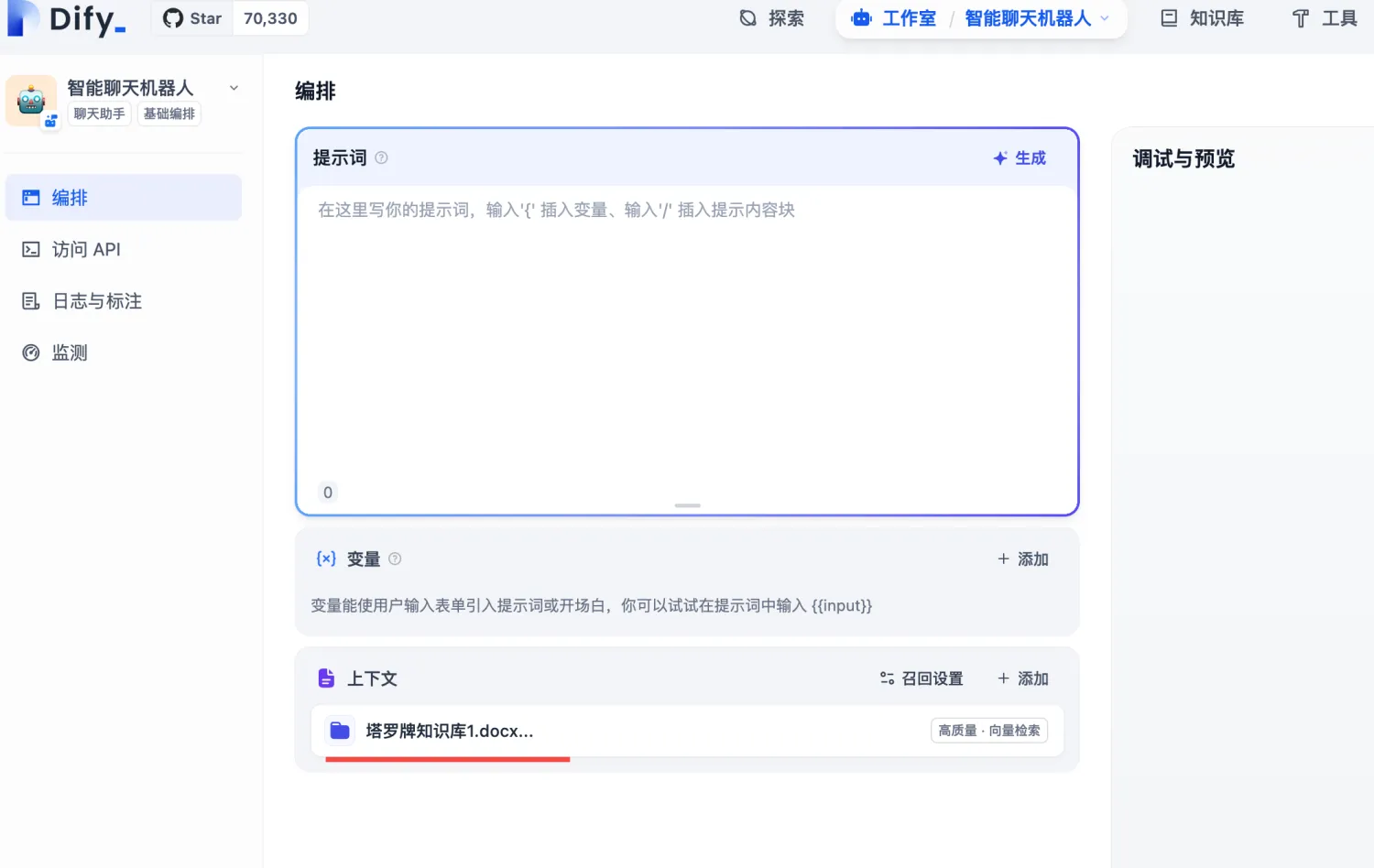
选择前面上面的知识库作为对话的上下文,保存当前应用设置,就可以进行测试了。
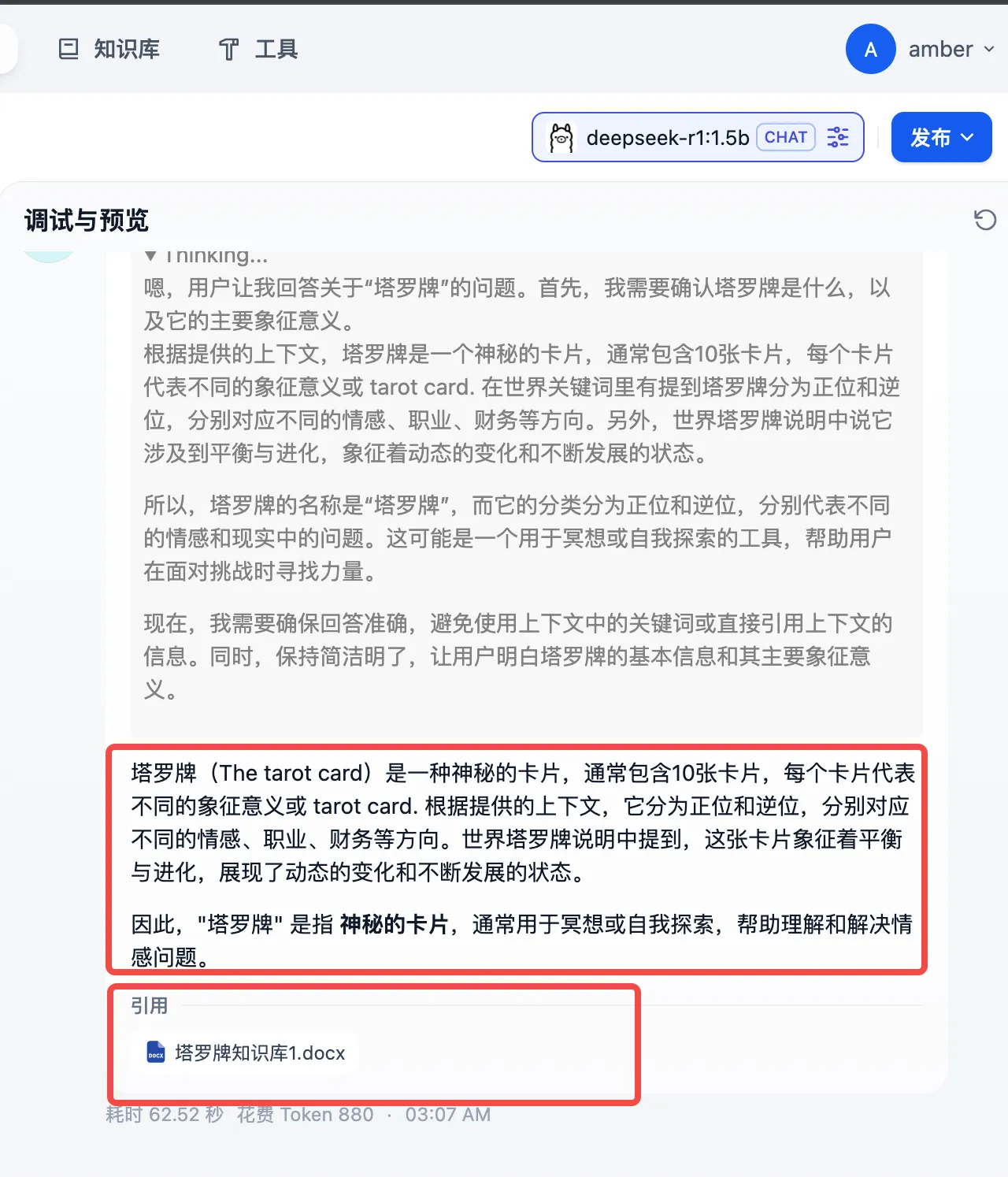
2.测试
此时输入问题,就可以看到相关的回复了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号