【Redis深度历险】那些年Redis的数据结构
Redis端口号6379的来源
Redis的端口号是6379,但这个端口号并不是随机选择的,源于"MERZ",这个单词在手机当中的对应数字就是6379。"MERZ"在Redis作者Antirez的好友圈当中代表愚蠢的意思。
数据结构
Redis的key只能是字符串,value可以是String,Hash,List,Sorted Set(Zset)。
String
Redis的字符串是动态字符串(SDS Simple Dynamic String ),内部结构有点儿类似于java的ArrayList,都是采取预分配来减少内存的频繁扩容。如图len是实际字符串的长度,capacity是预分配的空间(数组容量)。创建字符串时,len和capacity一样长,使用字节数组存放内容。
struct SDS<T> {
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标识位
byte[] content; // 数组内容
}
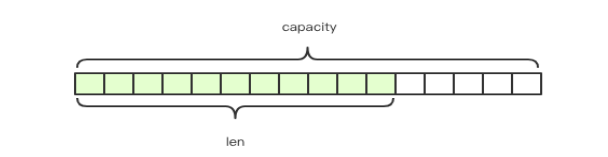
- 如果在1M以内,都是加倍扩充容量
- 如果超过1M则,每次扩容1M
- 字符串的最大容量是512M

String的一些基础操作
- 普通get set
127.0.0.1:6379> set name amber
OK
127.0.0.1:6379> get name
"amber"
127.0.0.1:6379> exists name
(integer) 1
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- 批量mset,mget
127.0.0.1:6379> set name amber
OK
127.0.0.1:6379> set name2 nick
OK
127.0.0.1:6379> mget name name2
1) "amber"
2) "nick"
127.0.0.1:6379> mset name3 wade name4 hellen
OK
127.0.0.1:6379> mget name name2 name3 name4
1) "amber"
2) "nick"
3) "wade"
4) "hellen"
127.0.0.1:6379>
- 设置过期时间
- 第一种 expire
127.0.0.1:6379> set name amber
OK
127.0.0.1:6379> expire name 5
(integer) 1
127.0.0.1:6379> get name
"amber"
//等待5s
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- 利用setex
setex name 时间 value
127.0.0.1:6379> setex name 5 amber
OK
127.0.0.1:6379> get name
"amber"
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- 自增自减
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> incr age
(integer) 19
127.0.0.1:6379> incrby age 5
(integer) 24
127.0.0.1:6379> incrby age -5
(integer) 19
127.0.0.1:6379> decr age
(integer) 18
127.0.0.1:6379>
List
Redis的list结构有点像Java中的LinkedList,但实际上地产不仅仅是简单的linkedlist,底层是quicklist(太深入了等待作者以后学习...)
特点
list的插入删除效率很高,时间复杂度为O(1),但是索引的定位就很慢,即O(n)
操作
- 左进右出(队列)
127.0.0.1:6379> lpush names amber nick wade
(integer) 3
127.0.0.1:6379> rpop names
"amber"
127.0.0.1:6379> rpop names
"nick"
127.0.0.1:6379> rpop names
"wade"
127.0.0.1:6379> rpop names
(nil)
127.0.0.1:6379>
当然你也可以左近左出(栈),可以自己实验一下。
- 索引操作
- lindex相当于java的get(int index)根据索引取值,但是因为要遍历链表,如果数据很大,导致开销增大
- ltrim key index1 index2 保留index1和index2之间的数据
127.0.0.1:6379> lpush names amber nick wade
(integer) 3
127.0.0.1:6379> lindex names 0
"wade"
127.0.0.1:6379> lindex names 1
"nick"
127.0.0.1:6379> lindex names 2
"amber"
127.0.0.1:6379> ltrim names 0 1
127.0.0.1:6379> lindex names 0
"wade"
127.0.0.1:6379> lindex names 1
"nick"
127.0.0.1:6379> lindex names 2
(nil)
127.0.0.1:6379>
hash(散列)
Redis的hash类似java中的HashMap
特点
Redis中的Hash进行rehash时区别于java中的HashMap。
在redis进行rehash时会同时保留新旧两个结构,并在后续的定时任务当中慢慢把旧的数据移动到新数据。
操作
127.0.0.1:6379> hmset person name amber age 18
OK
127.0.0.1:6379> hgetall person
1) "name"
2) "amber"
3) "age"
4) "18"
127.0.0.1:6379> hget person name
"amber"
127.0.0.1:6379> hset person gender 1
(integer) 1
127.0.0.1:6379> hgetall person
1) "name"
2) "amber"
3) "age"
4) "18"
5) "gender"
6) "1"
set
Redis中的set相当于java中的HashSet,内部相当于实现了一个字典
特点
value唯一
操作
127.0.0.1:6379> sadd names amber
(integer) 1
127.0.0.1:6379> sadd names amber
(integer) 0
127.0.0.1:6379> sadd names nick wade
(integer) 2
127.0.0.1:6379> smembers names
1) "amber"
2) "wade"
3) "nick"
zset(sorted set)
Redis中的zset相当于java中sorted set和HashMap的结合。在set的基础上还可以给value赋予score(排序的权重)
特点
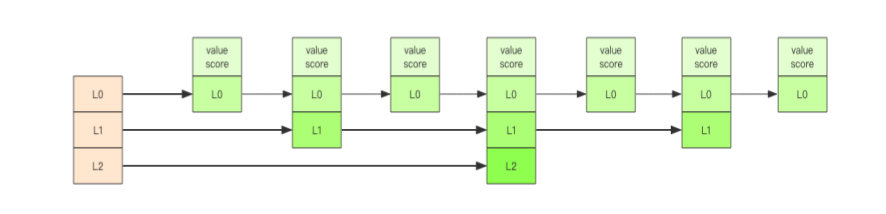
zset因为有score需要排序,但是采用普通的链表查找销量过低。因此zst采用层级制度。有点类似于国家->省级->市->xxx。最底层的乡镇肯帝就是我们的L0层级了,所有的元素都串联在一起,每个几个元素就选出市位于L2,同样的道理每隔几个L2层级的元素就选出省位于L3层级。当我们插入新的节点的时候,只需要从最顶层开始进行查找定位到相应位置就行了。是不是有点儿像数组的二分查找。
操作
其实还有一些操作,不过这里就不展示了
127.0.0.1:6379> zadd names 2 amber
(integer) 1
127.0.0.1:6379> zadd names 3 wade
(integer) 1
127.0.0.1:6379> zadd names 1 nick
(integer) 1
127.0.0.1:6379> zrange names 0 2
1) "nick"
2) "amber"
3) "wade"
127.0.0.1:6379>
数据结构知识点拓展
- redis的所有数据结构都可以设置时间
1. 设置时间
expire key 时间
2. 查看时间
ttl key


 浙公网安备 33010602011771号
浙公网安备 33010602011771号