PyTorch创建简单神经网络
导包
导入必要的包
import torch
import torch.nn as nn
import torch.nn.functional as F
from matplotlib import pyplot as plt
创建数据集与预处理
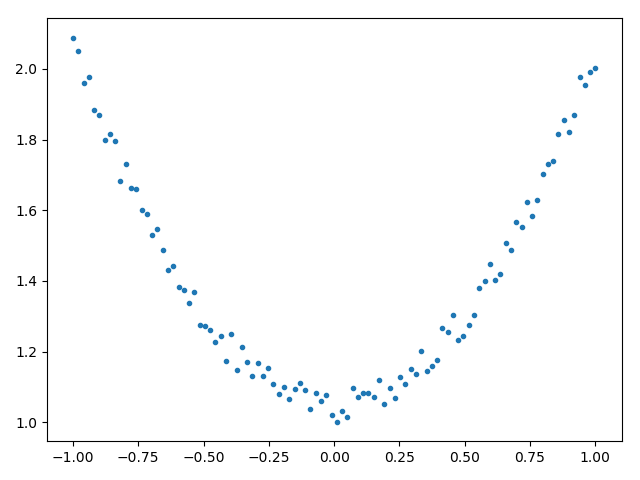
创建训练用的数据集,这里训练目标是预测 y = x^2+1 。
torch.manual_seed(42) # 设置PyTorch随机数种子,使下面每次神经网络参数随机初始化一致
x_train = torch.linspace(-1, 1, 100)
y_train = x_train * x_train + 1 + torch.rand_like(x_train)*0.1
plt.plot(x_train, y_train, '.') # 数据集可视化
plt.show()
x_train = x_train.unsqueeze(1) # 将x转换为2维数据,因为pytorch在前向传播时不接收一维数据
y_train = y_train.unsqueeze(1) # 为了在计算loss的时候保持y_train和神经网络的输出形状一致
创建网络(方法1)
# 定义一个有一个隐藏层,一个输出层的神经网络
class RegNet1(nn.Module): # 必须继承nn.Module
def __init__(self, n_features, n_hidden, n_output):
super(RegNet1, self).__init__()
self.hidden = nn.Linear(n_features, n_hidden) # 隐藏层接收输入层的数据
self.output = nn.Linear(n_hidden, n_output) # 输出层接收隐藏层的数据
# 前向传播过程,必须重写
def forward(self, x):
x = self.hidden(x) # 数据经过隐藏层
# x = F.sigmoid(x) # F.sigmoid(x)在当前PyTorch版本中已经不建议使用了
x = torch.sigmoid(x) # 数据经过激活函数
x = self.output(x) # 数据经过输出层
return x # 返会输出层结果
net = RegNet1(1, 10, 1) # 初始化网络对象,输入层每次只输入1个特征,隐藏层10个神经元,输出层1个神经元
创建网络(方法2)
这种方法更加简单直观,不用定义类,直接可以创建和上面一样的网络
net = nn.Sequential(
nn.Linear(1, 10),
nn.Sigmoid(),
nn.Linear(10, 1)
)
训练过程
criterion = torch.nn.MSELoss(reduction='mean') # 定义损失函数,采用均方误差
optimizer = torch.optim.SGD(net.parameters(), lr=0.3) # 定义优化器,采用SGD
for i in range(1000): # 迭代1000次
y_pre = net(x_train) # 前向传播
loss = criterion(y_pre, y_train) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 使用优化器更新梯度
if i % 10 == 0: # 每迭代10次打印一次loss
print(loss)
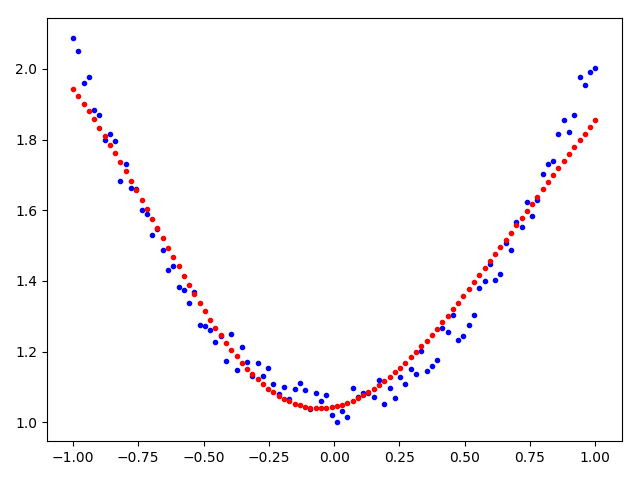
训练结果
# 可视化训练结果
plt.plot(x_train, y_train, '.b') # 绘制训练集
plt.plot(x_train, y_pre.detach().numpy(), '.r') # 绘制预测结果
plt.show()