
高精地图技术专栏 | 基于空间连续性的异常3D点云修复技术
1.背景
1.1 高精资料采集
高精采集车是集成了测绘激光、高性能惯导、高分辨率相机等传感器为一体的移动测绘系统。高德高精团队经过多年深耕打造的采集车,具有精度高、速度快、数据产生周期短、自动化程度高、安全性高、信息量大等特点。
为了保证高精地图制作的精度,在高精采集车中,我们使用了目前业界最先进的激光测距仪,具有测量距离远、点云密度大等优点,扫描频率可以达到每秒100万点。
1.2 激光MTA问题
高速的扫描频率带来高质量数据的同时,也引入了一些特有的噪声和干扰,MTA就是其中的一种。什么是MTA(Multi-Time-Around)呢?我们可以看一下图1,通过上下两图的对比可以看到,MTA问题实际就是激光的测距问题,激光将远处的点错误的拉到了近处,导致远处的楼房成为了近处路面上的噪声。
MTA问题会给后续资料处理、自动识别、地图制作等工艺流程带来很大的困难,导致识别以及人工流程出现错误。
我们需要通过激光的内部机制和数据处理算法,将这些噪声恢复到它本来的位置。本文会从MTA问题产生的原理、激光应对MTA的内部机制、数据处理算法三方面来介绍高精资料处理是如何解决这个问题的。
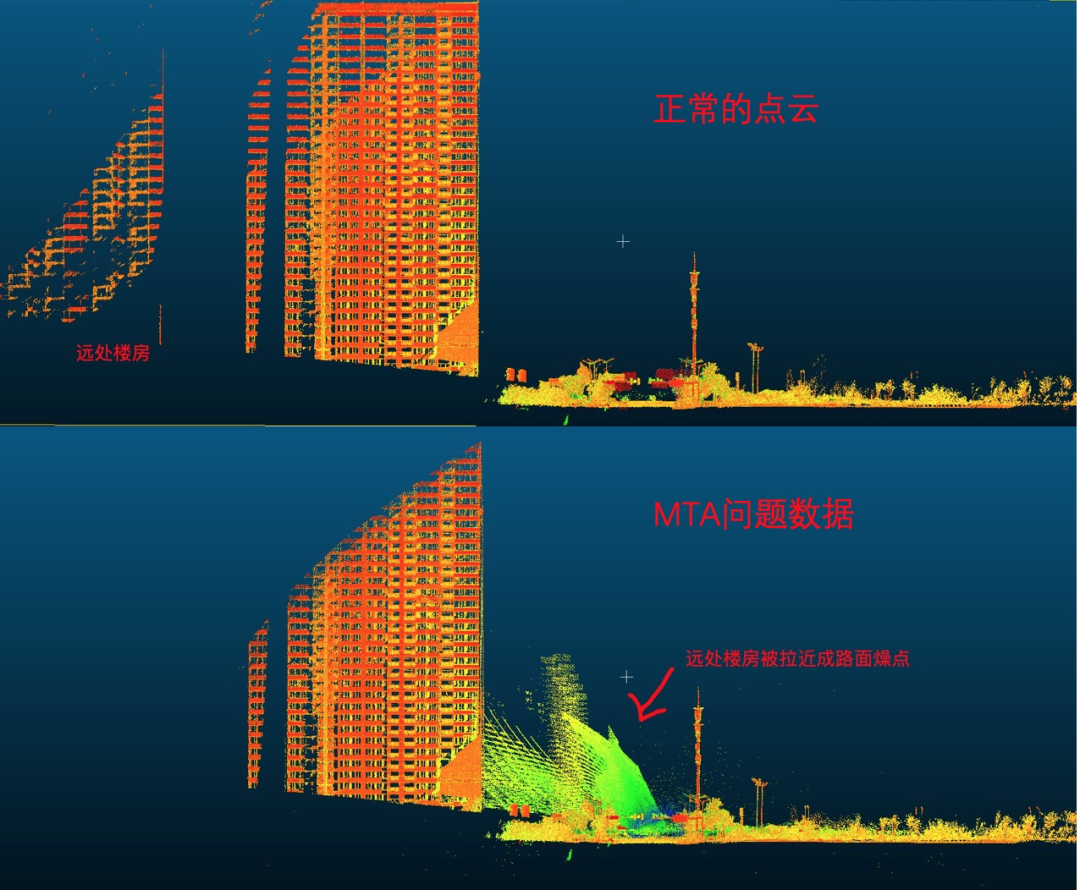
图1 MTA问题数据
2.MTA原理
那么,MTA究竟是怎样产生的呢?这要从激光的测量原理说起。
2.1 激光测距原理
典型的激光扫描仪是采用TOF(time of flight)原理进行测量的,即激光传感器在测量时每隔固定时间发射一个脉冲,然后测量返回的脉冲能量,根据发射和接收的时间差计算点的距离:
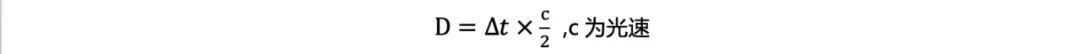
通过周期性地“发射激光-接收回波”,即可根据光飞行参数得到一系列测量点距离,结合激光自身的位置和姿态即可计算出反射点的位置。
2.2 MTA多区间
激光受自身功率的限制,通常能够探测到的最远物体距离有限,为Dmax。而激光脉冲的发射间隔为dt,在下一个脉冲发射前,当前激光脉冲能够探测到的最远距离为:
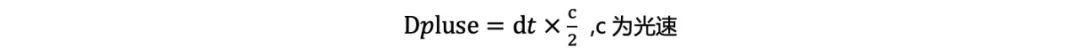
高精采集车使用的激光频率为100万点/秒,对应的Dpluse为150m。
通常情况下,激光的发送和接收是按顺序进行的,即发送-接收-发送-接收,空中始终只有一个激光脉冲,接收和发送是一一匹配的。
但是,当Dmax大于Dpluse时,如果测量物体比较远,就可能在空中出现多个脉冲,多个脉冲到达接收器的顺序不再和脉冲发射的顺序一致,接收器无法正确计算脉冲的TOF,从而不能正确的得出物体的测距。这就是MTA(Multi-Time-Around),如下图2所示。
通常将反射信号可能跨过的收发周期数称为“MTA区间”,匹配时间上最近的一个发射信号为MTA1,次近的发射信号为MTA2…依此类推。
Dpluse就是每个MTA的区间长度。如果物体离激光的距离超过这个长度,就会发生MTA问题,高精采集车激光的MTA区间长度是150m,因此对于超过150m的远处高楼就发生了MTA现象。
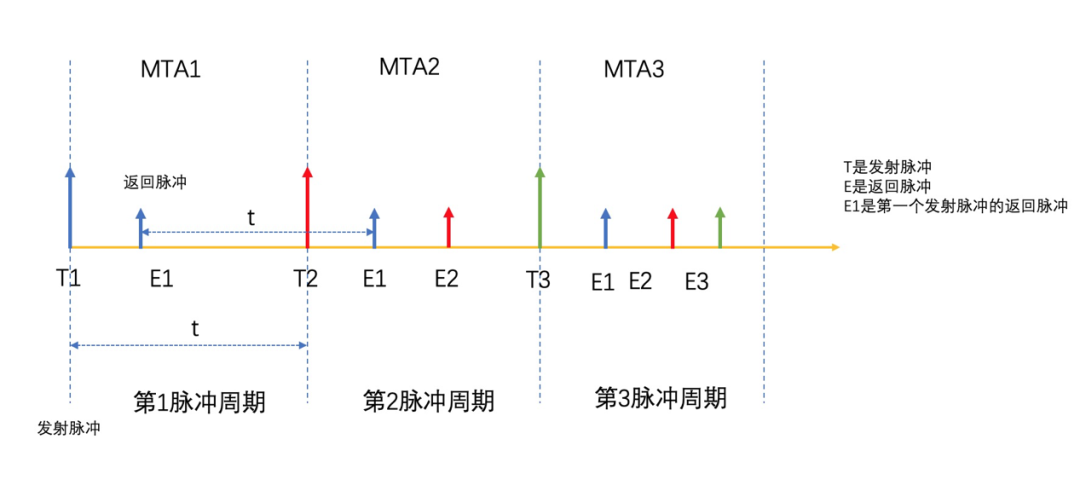
图2 MTA区间
3.激光应对MTA的内部机制
为了应对MTA问题,激光厂家也做了一些努力,通过利用测量物体的表面连续性的假设和变周期测量技术,找到了一些解决思路。
3.1 邻域连续性假设
在现实世界中大多数物体,例如道路、标牌、建筑物等人造物,这些实物都具有表面连续性,一般不会出现剧烈的几何变化和纹理。因此,连续的激光脉冲测距应该变化不大,如图3所示。
如果能够找到一种办法,使得当激光测距放错MTA区间时,相邻激光点不再具有连续性的特征,就可以将点云放到正确的MTA区间。变周期测量技术就是基于这一思路而产生的。
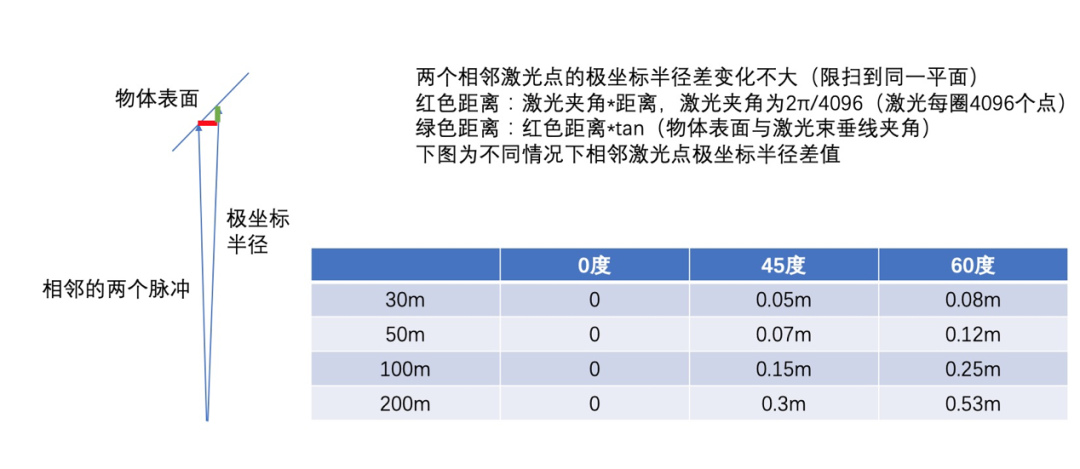
图3 相邻激光点测距连续性
3.2 变周期测量技术
为了识别MTA问题,激光厂商设计了一系列专利技术,其核心是“激光发射间隔可变”,即相邻激光脉冲发射的时间间隔是不同的,如图4。而且这个发射间隔的变化具备周期性,其周期特点如图5所示。当将点云放错MTA区间时,其测距不再是连续的,而是如图5中列表第3列所示,来回跳跃。如图6,错误的MTA区间,相邻点来回跳跃,形成图中的分层。
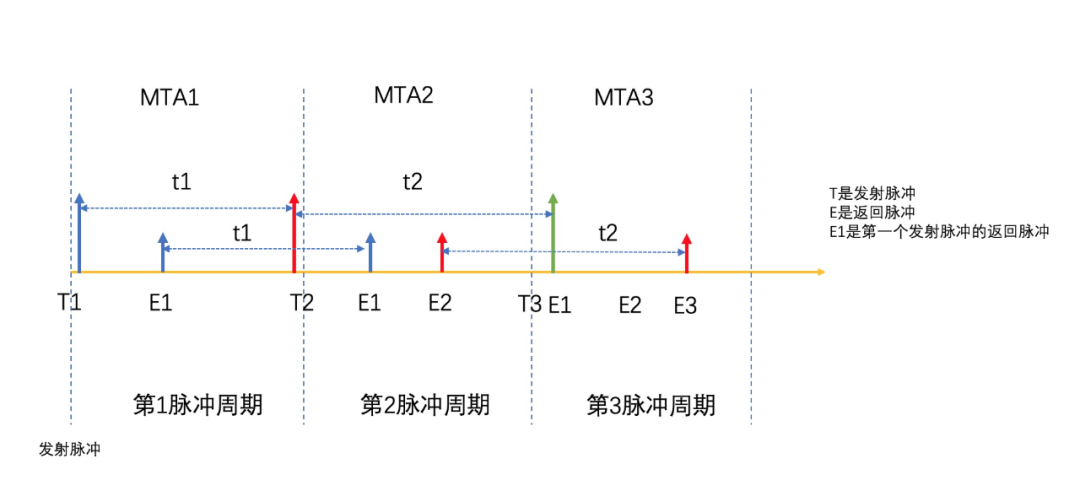
图4 变周期发射技术
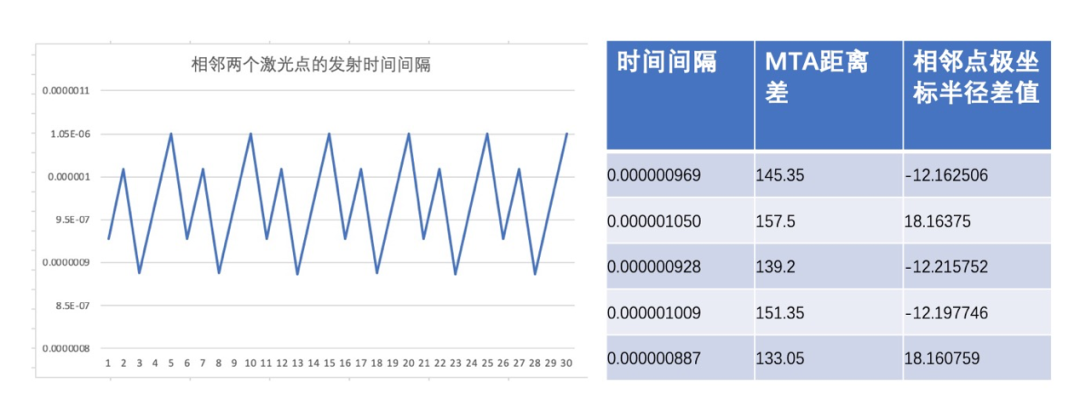
图5 变周期参数

图6 错误MTA区间
4.MTA修正算法
根据MTA问题的原理以及邻域连续性假设,结合硬件上的变周期测量技术,确定MTA问题处理方案。首先进行邻域划分,找到相邻激光点,然后对相邻点计算放到不同MTA区间的统计权值,权值大的为真实MTA区间。同时为了提高算法性能,利用激光本身安装位置参数避免不必要的权值计算。
4.1 邻域设置与检测
首先确定邻域,因为Lidar是一圈圈扫描的,既要考虑时间上连续的点相邻,也要考虑连续圈的相邻。其基本思路如下:
- 数据分圈:以一个圆周(线)为基本处理单元;
- 连续性计算区域:对于某个点,取其当前圈的邻近点以及前后相邻两圈的邻近点作为连续性计算区域,如图7;
- 对每个点计算其测距连续性权值以及反射率连续性权值,即与方差成反比例然后得出MTA区域。
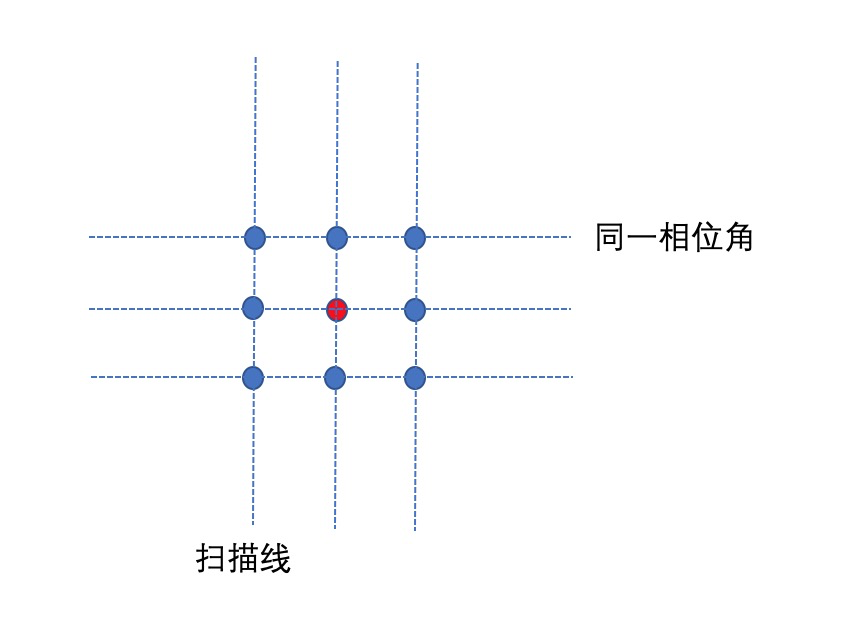
图7 邻域查找
4.2 加权统计策略
总的加权策略是距离方差越大,权重越小;反射率方差越大,权重越小。具体权值选择采用高斯函数或三角函数。
经过实际大批量数据统计分析,距离方差的权重采用高斯函数,其中u=0,δ=0.25,反射率方差的权重也采用高斯函数,其中u=0,δ=4
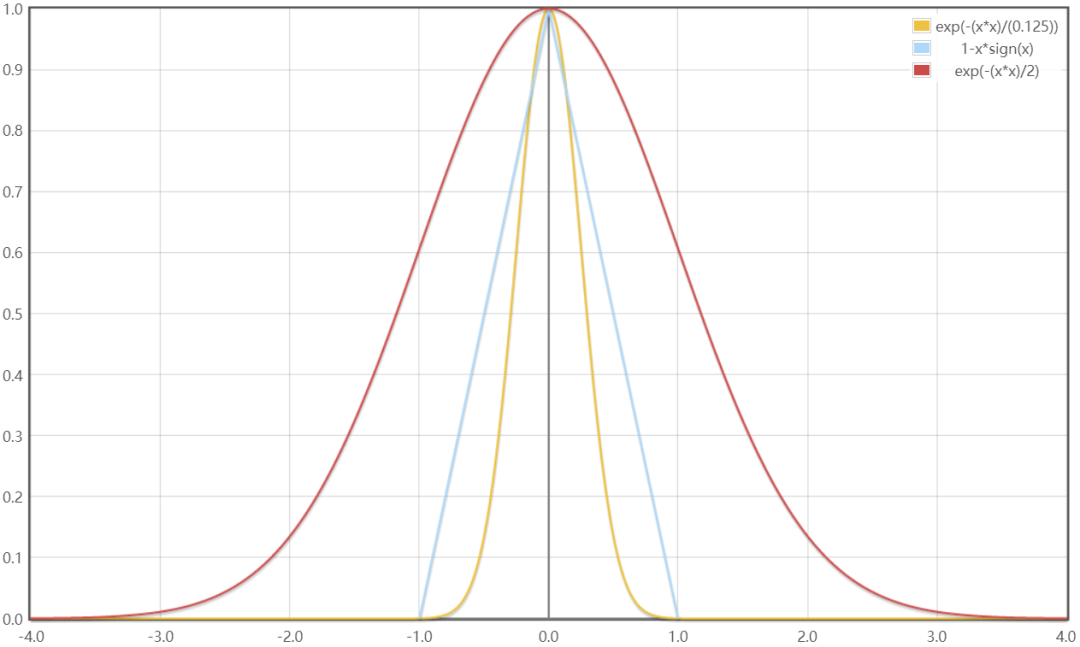
图8 加权函数选取
具体计算过程如下:
- 对每个点,分别获取其作为MTA1与MTA2的测量数据,主要为测距值、反射率;
- 对每个点,分别获取其MTA1与MTA2邻居点集合;
- 计算每个点的每个邻居的测距权值和反射率权值,然后求和,最终根据权值大小确定MTA区域。
4.3 处理效果
算法的处理效果如下图9,图10.

图9 MTA处理效果:未处理MTA

图10 MTA处理效果:MTA恢复结果
4.4 性能优化
使用基本的处理方案可以较好地恢复MTA错误问题,但是由于搜索区间较大,而且必须逐点处理,效率很低,不能满足效率的要求,需要进行优化。考虑的优化方向包括减少搜索区间和算法优化两方面。
4.4.1 减小搜索区间
我们使用的激光设备探测范围参数如下,不超过300m,也就是2个MTA区间,因此可以只考虑MTA1和MTA2区间两种可能,这就大大降低了计算量。
设备探测范围参数:
- 探测距离最大 235m(80%高反射率);
- 低反射率物体不到 100m;
- 针叶林 100m;
- 柏油沥青 120m;
- 阔叶林 150m;
- 建筑砖头 200m左右;
- 白色灰泥 250m。
4.4.2 算法优化
根据扫描特性进一步进行算法优化。
- 考虑到发生MTA错误都发生在地面以上,即激光实际能扫描到的很远的物体都在地面以上,可先根据车高信息剔除地面附近点;
- 对于多次回波,点的连续性只取第一次回波来计算;
- 分圈后按扫描角和测距值判断空间相邻;
- 分圈处理,多线程并行加速;
- 对于不同区域的连续性都很差的点作为孤立点进行剔除。
5.总结与展望
MTA处理算法作为点云解算模块的一部分,是采集资料处理上云的重要环节,不解决MTA问题,就无法实现采集资料处理的自动化。同时MTA处理算法去除了资料处理环节对激光厂商软件的依赖,为公司节省了大量成本。
在算法设计阶段尝试利用SVM,RF等机器学习手段按点云分类思路解题,初步测试发现样本制作困难、正负样本量级差异过大等问题。另一方面,机器学习方法批次处理需要考虑合适的空间范围,对于每个分块动辄亿级的点数,其处理效率将无法满足产线需求。
在算法效果评估阶段,原本打算使用厂商处理的结果作为真值。但评测下来发现,厂商处理结果的效果不如自研算法,不能作为评测真值。最终我们结合产线工艺需求,专门制作了评估方案,算法目标对焦到业务需求,从而客观、可靠、快速地完成了算法的评测工作。
目前MTA处理算法已经进入了线上生产,处理了上万公里点云数据,目前运行稳定,达到预期。
关于高精地图业务中心
高精地图是高德最具创新性的业务之一,致力于用传感器丈量世界,用算法理解世界,用数据重新定义世界。我们几乎涵盖最热门前沿学科,高精地图和自动驾驶是多学科交叉的应用工程体系。基于感知理解,三维重建,融合定位,计算几何技术自动化生成高精数字化三维地图。利用边缘计算,大数据处理,云服务,进行实时海量数据地图重建。通过5G/V2X信息交换,实现地图对象间的数据互通,构建一张活地图。我们不仅仅是数据制作者,更是新生活的定义者。加入我们,未来“由”你。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号