
深度学习在高德POI鲜活度提升中的演进
1.导读
高德地图拥有着数千万的POI(Point of Interest)兴趣点,如学校、酒店、加油站、超市等。其中伴随着众多POI创建的同时,会有大量的POI过期,如停业、拆迁、搬迁、更名。这部分POI对地图鲜活度和用户体验有着严重的负面影响,需要及时有效地识别并处理。
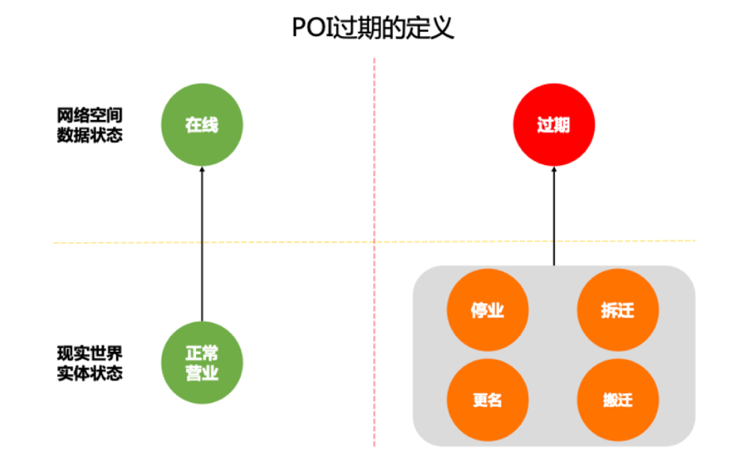
由于实地采集的方式成本高且时效性低,挖掘算法则显得格外重要。其中基于趋势大数据的时序模型,能够覆盖大部分挖掘产能,对POI质量提升有着重要意义。
过期POI识别本质上可以抽象为一个数据分布非对称的二分类问题。项目中以多源趋势特征为基础,并在迭代中引入高维度稀疏的属性、状态特征,构建符合业务需求的混合模型。
本文将对深度学习技术在高德地图落地的过程中遇到的业务难点,和经过实践检验的可行方案进行系统性的梳理总结。
2.特征工程
过期挖掘的实质是感知伴随POI过期而发生的变化,进行事后观测式挖掘,一般都会伴随着POI相关活跃度的下降。因此时序模型的关键是构建相关联的特征体系。同时在实践中我们也构造了一些有效的非时序特征进行辅助校正。
2.1时序特征
时序特征方面,建立了POI和多种信息的关联关系,并分别整合为月级的统计值,作为时序模型的输入;时间序列窗口方面,考虑到一些周期性的规律的影响,需要两年以上的序列长度来训练模型。
2.2辅助特征
辅助特征方面,首先是将人工核实历史数据进行有效利用。方式是构造一个时间序列长度的One-Hot向量,将最后一次人工核实存在的月份标记为1,其他月份为0。人工核实存在表示该时间结点附近过期概率较低,若人工更新在趋势下降之后,说明趋势表征过期的概率不高。
其次,调研发现不同行业类型的POI有着不同的过期概率,如餐饮和生活服务类过期概率较高,而地名或公交站点等类型则相对低很多。因此将行业类型编号构建为一个时间序列长度的等值向量,作为静态辅助特征。
第三种辅助特征是在分析业务中的漏召回问题时总结构造的。发现有相当部分的新诞生POI,其入库创建后至今的时长短于序列长度。意味着这部分序列前期存在较多数值为零的伪趋势,会对尾部的真实下降趋势造成干扰从而误判。对此提出了两种优化思路:
-
采用可变长度的RNN模型,只截取POI创建时间之后部分的序列作为输入。
-
序列长度不变,添加一维“门”序列特征,序列在POI创建时间之前的部分数值为0,之后为1。如图所示。
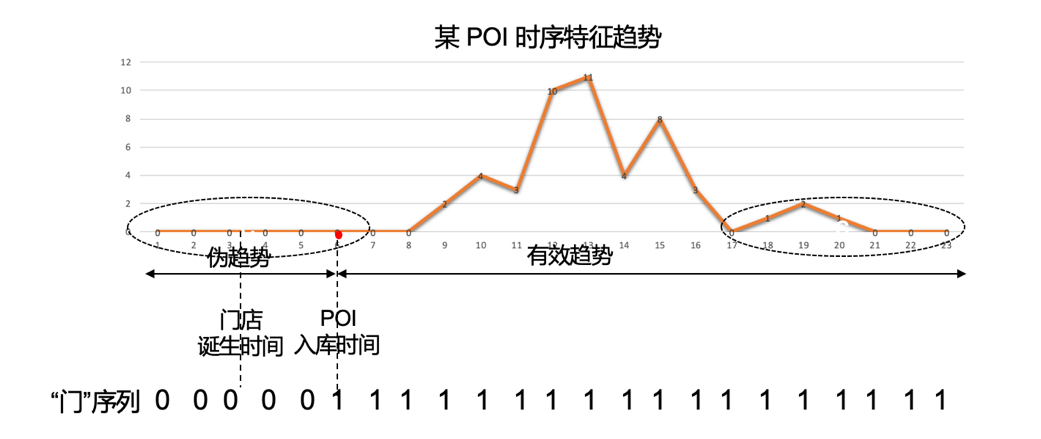
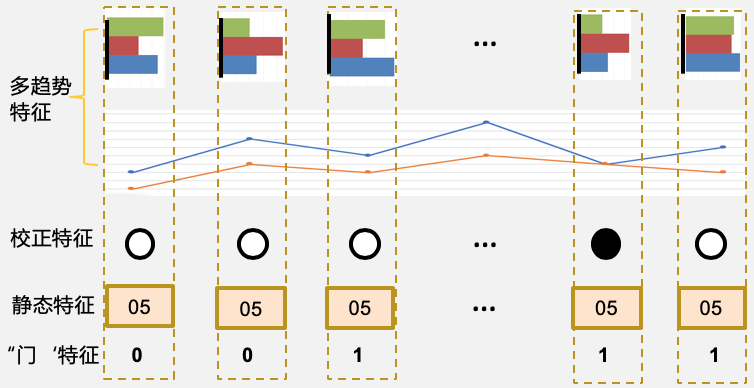
对比采用第二种方案效果更优。考虑到我们只有POI的入库创建时间信息,而不了解门店的具体诞生时间,直接按入库时间截取序列,会造成门店诞生和POI创建时间段内的特征信息损失;而添加“门”序列则可以在保持信息完备的同时约束高可信区间。最后构建的混合特征示意图如下所示。
3.RNN阶段
循环神经网络(RNN, Recurrent Neural Network)凭借强大的表征能力在序列建模问题上有非常突出的表现,业务中采用了其变种模型LSTM。
3.1RNN1.0
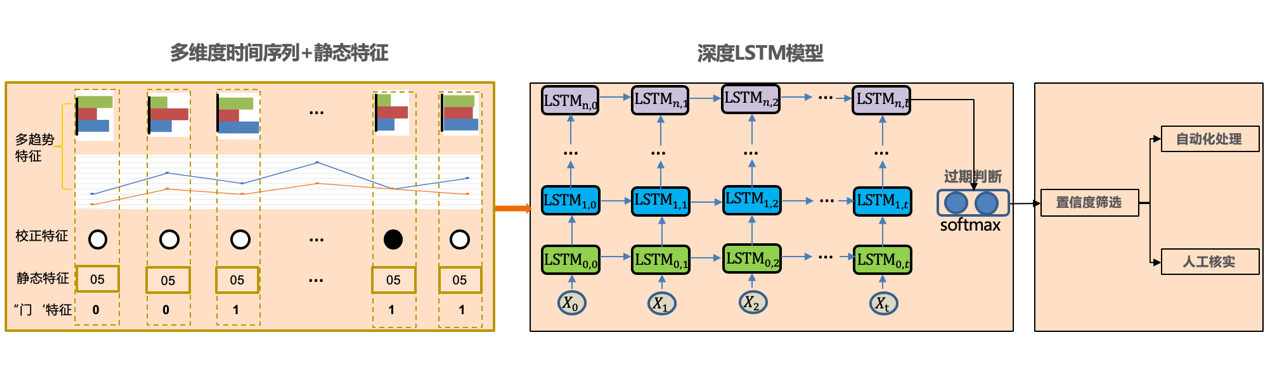
以前述的时序特征和辅助特征为基础,我们采用多层LSTM搭建了第一版RNN过期挖掘模型,结构如图所示。主要逻辑为,将逐时间点对齐后的特征输入到深度LSTM中,在网络最后时刻的输出后,接入一层SoftMax计算过期概率。最后根据结果匹配不同的置信度区段,分别进行自动化处理或人工作业等任务。模型初步验证了RNN在过期趋势挖掘领域落地的可行性和优势。
3.2 RNN2.0
高德地图基于导航、搜索或点击等操作频度对POI进行了热度排名。头部的热门POI如果过期但未及时发现对用户体验的伤害更大。2.0版本模型升级的主要目标便是进一步提升头部热门段位的过期POI发现能力。
分析发现热门POI的数据分布相比尾部有较大差异性。头部POI的数据量丰富,且数值为0的月份很少;相反尾部POI则数据稀疏,且有数值月份量级可能也仅为个位数。对于这种头部效应特别明显的状况,单独开发了高热度段特征的头部RNN模型,实现定制化挖掘。
另一方面,对于单维度特征缺失的情况,也区分热度采用了不同的填充方式。头部POI特征信息丰富,将缺失维度补零让其保持“静默”防止干扰;而尾部特征稀疏,本身已有较多零值,需要插值处理使缺失特征和整体保持相近趋势。方法为将其他维度的数据规范化处理后,采用加权的方式得到插值。

2.0版模型对头部和尾部的召回能力都有提升,对头部的自动化能力提升尤为明显。
4.Wide&Deep阶段
RNN模型能够充分发掘时序特征的信息,但特征丰富度不足成为制约自动化能力进一步提升的瓶颈。因此整合业务中的其他数据,从多源信息融合角度升级模型便成为新阶段的工作重点。主要的整合目标包括非时序的静态信息和状态信息,以及新开发的时序特征信息。
模型升级主要借鉴了Wide&Deep的思想,并做了很多结合业务实际情况的应用创新。首先我们要把已有的RNN模型封装为Deep模块后和Wide部分联合,相当于重新构建了一个混合模型,涉及到模型结构维度的整合。其次,既有Deep的时序信息,又有Wide部分的实时状态信息,涉及到数据时间维度的整合。最后是Wide部分包含大量的不可量化或比较的类型特征需要编码表征处理,涉及到数据属性维度的整合。
4.1 Wide & LSTM
-
特征编码
我们将非时序特征经过编码后构建Wide模块。主要包括属性、状态,以及细分行业类型三种特征。
考虑到某些POI属性存在缺失的情况,故编码中第1位表示特征是否存在的标志位,后面则为One-Hot编码后的对应的属性类型;对于状态特征,同样有一位表示是否特征缺失的标志位,而后面的One-Hot编码则表示最新时刻的状态类型;由于不同行业类型有着不同的背景过期率,我们将细分的行业类型做One-Hot编码后作为第三种特征。最后将各特征编码依次连接,得到一个高维度的稀疏向量。特征编码的过程如图所示。
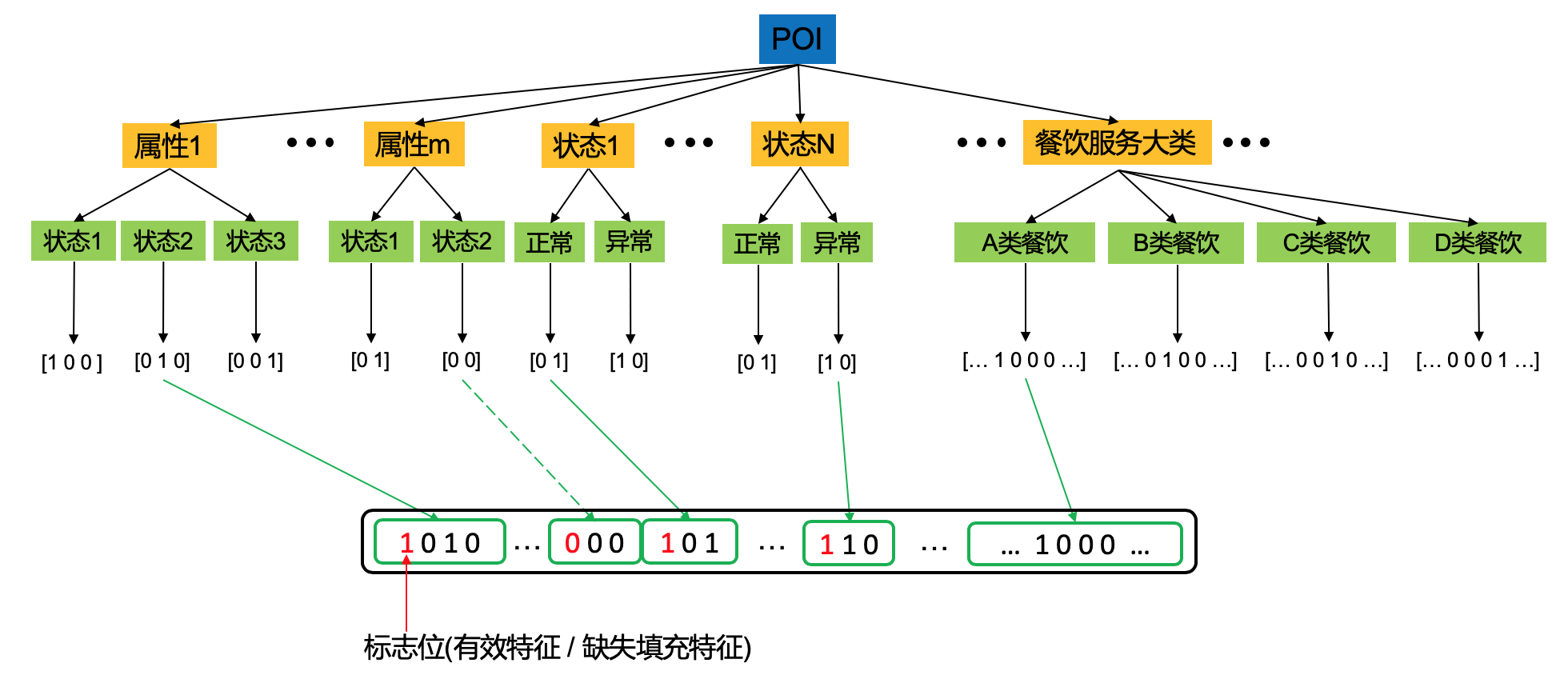
- 特征耦合
特征完备之后,将各类特征耦合及模型训练便成为关键。耦合点选在了SoftMax输出的前一层。对于Deep部分的RNN结构,参与耦合的便是最后时间节点的隐层;而对于Wide部分的高维度稀疏向量,我们通过一层全连接网络来降维,便得到Wide部分的隐层。最后将两部分的隐层连接,输出到SoftMax来计算过期概率。
模型采用同步输入Wide和Deep部分特征的方式联合训练,并调节两部分的耦合隐层的维度来平衡两部分的权重。过期挖掘场景的Wide & LSTM模型结构如图所示。
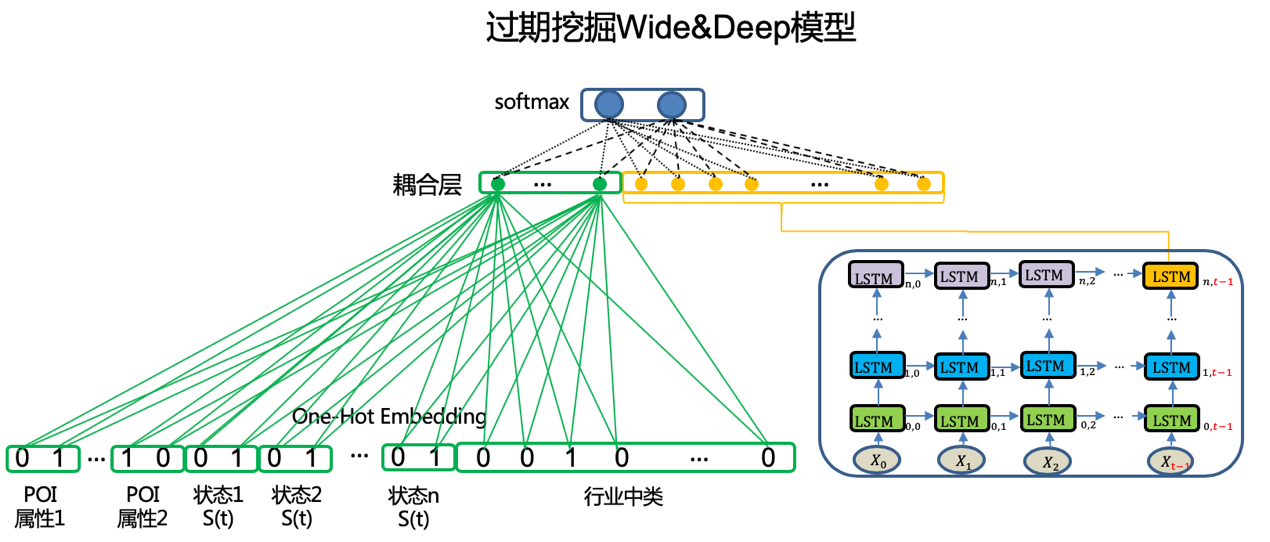
模型经过多次迭代优化后稳定投产,已成为过期挖掘业务中覆盖行业广、自动化解题能力突出的综合性模型。
4.2 Wide & Dual-LSTM
在做模型升级迭代的同时,基础特征的建设工作也在同步进行。在扩充新的趋势特征的时候面临这样一个问题,新特征维数较多且时间序列较短,这样将长时序特征和短时序特征逐时间点匹配时会出现很大部分的数值缺失。
由于新特征缺失部分较多且维度较大,缺失值填充的负面影响会过于严重而不适合采用。项目中采用了分而治之的方案,分别建立两个RNN模块,其中长RNN模块输入无新特征的长序列,短RNN模块输入有新特征的短序列,最后将双RNN的Hidden层和Wide部分一起耦合,得到了Wide & Dual-RNN模型,结构如图所示。
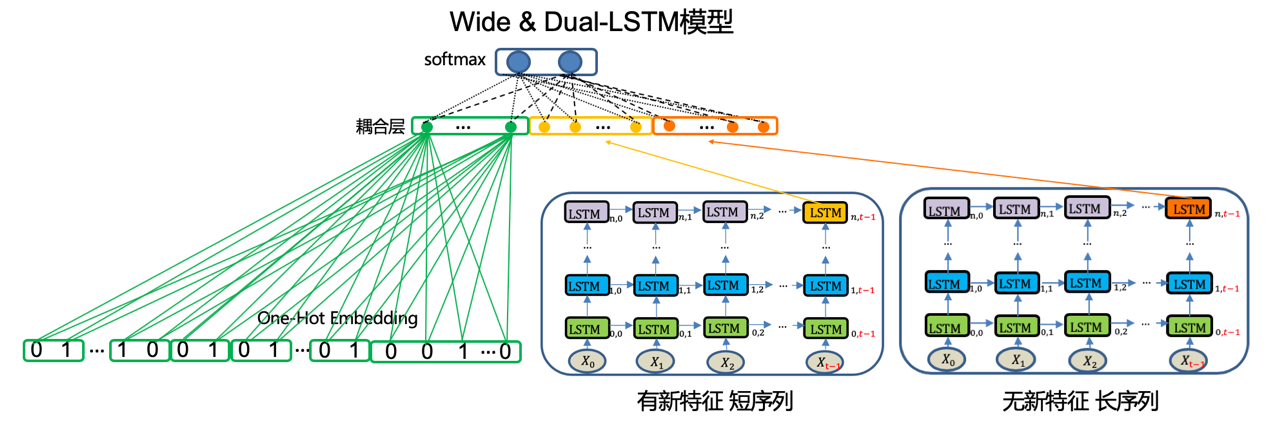
双RNN结构能够很好地将新特征融入到现有模型并提升判断准确率,不足的地方是结构较复杂影响计算效率。故后期进行了新阶段的研发,采用更灵活的时序模型TCN进行迭代。
4.3 Wide & Attention-TCN
TCN主要有如下三方面优点使其能胜任时间序列的建模:首先,架构中的卷积存在因果关系,即从未来到过去不会存在信息泄漏。其次,卷积架构可以将任意长度的序列映射到固定长度的序列。另外,它还利用残差模块和空洞卷积来构建长期依赖关系。
性能对比上,TCN可以将时间序列作为向量并行化处理,相比RNN的逐时间点顺序计算的方式有更快的计算速度。此外,TCN可以输入延展成一维的序列,从而避免了特征需要逐时间点对齐。因此在验证了Wide&Deep的思路有效后,我们尝试将Deep部分的RNN结构升级为TCN。
首先,对于输入部分的特征进行了Flatten处理,即将每个维度的时间序列依次首尾相连,如图所示,拼接成为一个长向量后作为输入。这样便实现了长特征和短特征的有效整合。
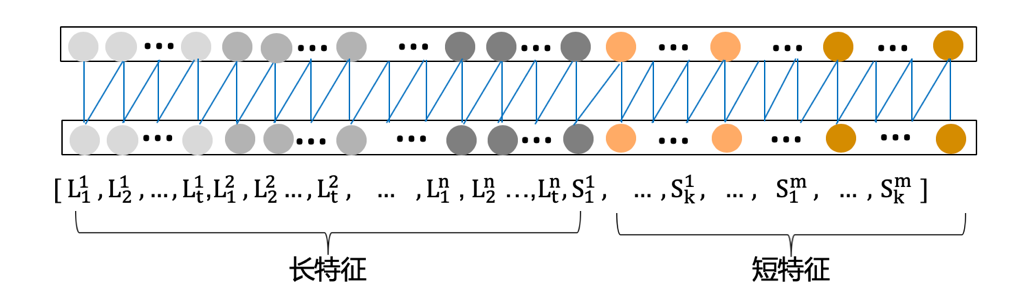
其次,对于输出结构,引入序列维度的Attention机制进行优化。主要思想是不再只读取序列最后节点的隐向量的浓缩信息,而是对所有序列节点的隐向量信息加权处理后,得到汇总的隐向量信息,使所有节点的学习结果得到充分利用。
最后将Attention-TCN后得到的汇总隐向量和Wide部分的隐层进行耦合,得到的Wide&Attention-TCN模型结构如图所示。
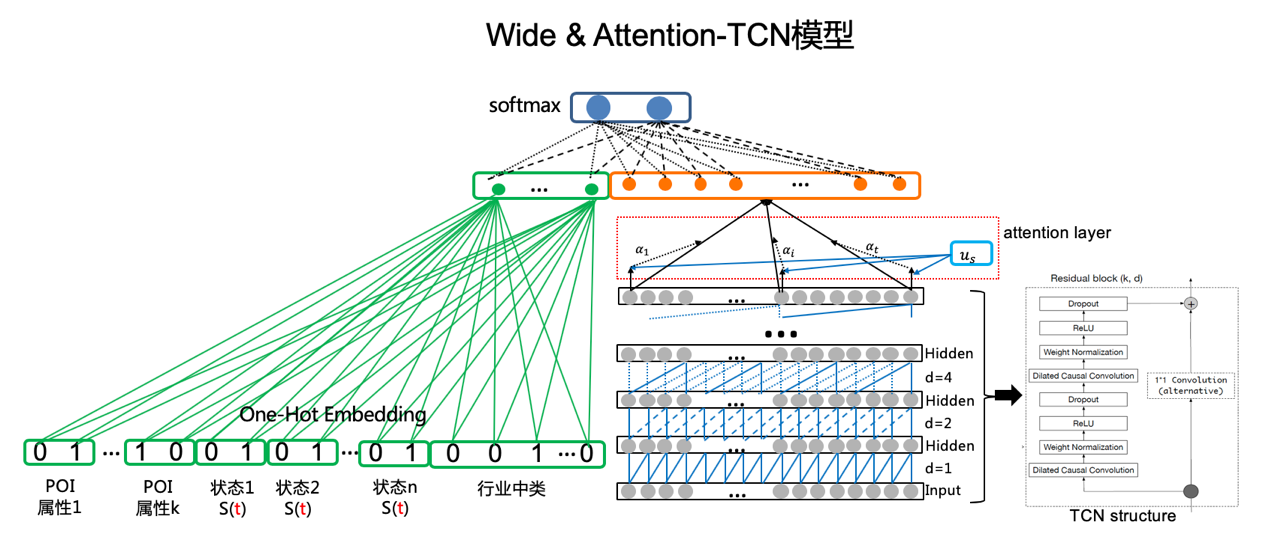
通过引入新的轻量TCN时序模型和Attention机制,新的模型性能有了进一步提高,但调优过程相对RNN更加复杂。多轮参数调整与结构优化后,最终落地版本与Wide & Dual-LSTM版相比,计算效率和业务扩招回能力均有可观提升。
5.总结与展望

深度学习在过期挖掘场景中的落地,经历了不断摸索尝试、总结问题、优化方案、验证效果的迭代演进的过程。期间以提升过期发现能力为核心目标,对特征扩展、特征构造和模型结构优化的角度都进行了探索,并总结了如上的业务场景落地经验。其中,丰富可靠的特征、合适的特征表征方式和符合场景的模型结构设计是提升业务问题解决能力的关键。
当前模型主要是基于信息和趋势进行宏观性的规律总结,并判断具备这类特征情况下的POI过期的概率。而现实生活中POI的具体地理环境、自身经营状况、周边竞争态势等个性化因素的影响往往不可忽略。因此,未来规划将综合考虑整体规律性特征和个体差异性,实现精细化挖掘。
6.参考文献
1.Sepp Hochreiter and Jurgen Schmidhuber, Long Short-Term Memory, Neural Computation 1997
2.B. Hidasi, A. Karatzoglou, L. Baltrunas, and D. Tikk. Session-based recommendations with recurrent neural networks. CoRR, abs/1511.06939, 2015
3.Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, GlenAnderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah. Wide&Deep learning for recommender systems. In Proc. 1st Workshop on Deep Learning for Recommender Systems, pages 7–10, 2016.
4. Paul Covington, Jay Adams, and Emre Sargin. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 191–198, 2016.
5.Bai S , Kolter J Z , Koltun V . An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling[J]. 2018.
6.Pappas N , Popescu-Belis A . Multilingual Hierarchical Attention Networks for Document Classification[J]. 2017.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号