
一、汉字区位码、国标码和机内码
1、区位码
为了使每一个汉字有一个全国统一的代码,1980年,我国颁布了第一个汉字编码的国家标准: GB2312-80《信息交换用汉字编码字符集》基本集,这个字符集是我国中文信息处理技术的发展基础,也是目前国内所有汉字系统的统一标准。
所有的国标汉字与符号组成一个94×94的矩阵。在此方阵中,每一行称为一个"区",每一列称为一个"位",因此,这个方阵实际上组成了一个有94个区(区号分别为0 1到94)、每个区内有94个位(位号分别为01到94)的汉字字符集。一个汉字所在的区号和位号简单地组合在一起就构成了该汉字的"区位码"。在汉字的区位码中,高两位为区号,低两位为位号。
在区位码中,01-09区为682个特殊字符,16~87区为汉字区,包含6763个汉字 。其中16-55区为一级汉字(3755个最常用的汉字,按拼音字母的次序排列),56-87区为二级汉字(3008个汉字,按部首次序排列)。
需要注意的是:区位码通常都是用十进制表示的,例如“诚”字的区位码为1947,也就说它位于19区第47个字符。
摘自:《汉字区位码》
2、国标码
国家标准代码,简称国标码,是中华人民共和国的中文常用汉字编码集。国家标准强制标准冠以“GB”。
现时中华人民共和国官方强制使用GB 18030标准,但较旧的计算机仍然使用GB 2312。国标码 = 区位码(16进制化--区码和位码分别进行16进制转化)+2020H
3、机内码
计算机只识别由0、1组成的代码,ASCII码是英文信息处理的标准编码,汉字信息处理也必须有一个统一的标准编码。 汉字交换码(国标码)主要用于汉字信息交换,我国国家标准局于1981年5月颁布了《信息交换用汉字编码字符集——基本集》,代号为GB2312-80,共对6763个汉字和682个图形字符进行了编码。
其编码原则为:汉字用两个字节表示,原则上,两个字节可以表示 256×256=65536 种不同的符号,作为汉字编码表示的基础是可行的。但考虑到汉字编码与其它国际通用编码,如ASCII 西文字符编码的关系,我国国家标准局采用了加以修正的两字节汉字编码方案,只用了两个字节的低7位。这个方案可以容纳128×128=16384 种不同的汉字,但为了与标准ASCII码兼容,每个字节中都不能再用32个控制功能码和码值为32的空格以及127的操作码。所以每个字节只能有94个编码。这样,双七位实际能够表示的字数是:94×94=8836个。
机内码 = 国标码 + 8080H
机内码 = 区位码(16进制化--区码和位码分别进行16进制转化) + a0a0H摘自:《机内码》
4、相互转换
- 内码转换为区位码
区位码: 区码=内码高字节-0xa0
位码=内码低字节-0xa0
例如:“国”内码为:0xb9,0xfa
16进制表示的区位码:0x19,0x5a
其区位码(默认为10进制):2590
- 区位码转换为内码
内码: 内码高字节=区码+0xa0
内码低字节=位码+0xa0
例如:“海”区位码为:2603
16进制表示的区位码:0x1a,0x03
其内码(默认为16进制):0xba,0xa3
二、字模
汉字在显示的时候,是以点阵的形式显示出来的,常见到的有16*16点阵、24*24点阵、32*32点阵。比如说“啊”的16*16点阵字模如下,共256Bits,占用32 Bytes:
0x00,0x00,0xf7,0x7e,0x95,0x04,0x95,0x04,0x96,0x74,0x96,0x54,0x95,0x54,0x95,0x54, 0x95,0x54,0xf5,0x54,0x97,0x74,0x04,0x04,0x04,0x04,0x05,0x04,0x04,0x14,0x04,0x08
字模显示的时候,以两个字节表示一行像素点,16行就构成了一个完整的字模。屏幕在显示的时候,1显示为亮色,0显示为背景色,这样就能把字体显示出来。用C测试程序,把1的地方显示为“*”,0的地方显示为空,效果如下:
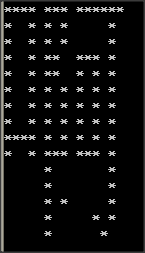
三、字库
字库,就是所有汉字字模的集合。显然,在编排这些字模的时候需要一定的顺序(规则),而这个规则就是“机内码”。根据机内码的汉字布局,将对应的汉字字模进行整合,形成字库文件。在使用的时候,应用程序根据汉字的机内码,从字库中找到对应的存储位置,取出字模,进行显示。机内码就是汉字在字库中的索引。
在区位码中,01-09区为682个特殊字符,16~87区为汉字区,有效汉字6768个。在制作字库的时候把特殊字符删除,只使用有效汉字区。也就是说我们从第16区的第1位开始进行字模收集,当第16区收集结束,紧接着收集第17区,直到第87区编排结束。总共收集6768个汉字,占用空间216576 Bytes。


☆ 机内码与字库偏移量的关系
偏移量 = ((机内码高字节-0xb0)*94+机内码低字节-0xa1)*32
四、测试程序


#include <stdio.h> void ShowOneWord(const char *str); int GetGBKCode(unsigned char* pBuffer,const char * c); void ShowWords(const char *str); /** * @brief main function * @param Nove * @retval Nove */ int main(void){ ShowWords("测试汉字显示"); return 0; } /** * @brief Show multiple Chinese Words * @param str : point to Chinese location code * @retval Nove */ void ShowWords(const char *str){ if(NULL == str) return; while(*str != 0){ ShowOneWord(str); str += 2; } } /** * @brief Show one Chinese Word * @param str : point to Chinese location code * @retval Nove */ void ShowOneWord(const char *str){ unsigned char buffer[32]; int i,j; unsigned char k; GetGBKCode(buffer,str); for(i=0;i<16;i++){ for(j=0;j<8;j++){ k = buffer[2*i] << j; if(k & 0x80){ printf("*"); } else{ printf(" "); } } for(j=0;j<8;j++){ k = buffer[2*i+1] << j; if(k & 0x80){ printf("*"); } else{ printf(" "); } } printf("\n"); } printf("\n\n"); } /** * @brief Get type matrix from HZLIB.bin based on Chinese location code * @param pBuffer: point to 32 bytes type matrix buffer * c : point to Chinese location code * @retval 0(success) -1(fail) */ int GetGBKCode(unsigned char* pBuffer,const char * c){ unsigned char High8bit,Low8bit; unsigned int pos; FILE * fp; High8bit=*c; Low8bit=*(c+1); pos = ((High8bit-0xa0-16)*94+Low8bit-0xa0-1)*2*16; //get type matrix location fp =fopen("HZLIB.bin","r"); //open type matrix file if (fp != NULL) { fseek (fp,pos,SEEK_SET); //set read start point fread(pBuffer,1,32,fp); //read 32 bytes fclose(fp); return 0; } else return -1; }
五、注意
1、汉字在程序中是以机内码进行表示,英文字符则是ASCII,汉字的机内码占两个字节
2、汉字表示的时候,以双引号括起来代表一个字符串,只有一个汉字的字符串,实际占用3个字节的存储空间。
附eclipse测试代码: Chinese_Test.zip
参考资料:《STM32库开发实战指南》

