论文笔记[3] MASS: Masked Sequence to Sequence Pre-training for Language Generation
论文题目:MASS: Masked Sequence to Sequence Pre-training for Language Generation
论文传送门: https://arxiv.org/pdf/1905.02450.pdf
论文作者:Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu
Introduction
-
Seq2Seq: Encoder + Decoder frame
for Language Generation, e.g. machine translation. -
GPT
-
BERT
Pre-training + Fine-tuning
MLM(Masked Language Model) -
Motivation
Language generation: data-hungry, low/zero-source training data.
Unsupervised, if train encoder & decoder separately => different distribution.
Then Train It Jointly!
对于文本生成任务(机器翻译、文本摘要、生成问答),由于语料对较少,更需要使用pretrain的模型来减少标注代价。
如果我们的语料是unsupervised,就要分开预训练encoder和decoder,可能会导致两者的分布不一致。
MASS希望能够兼顾两点:
- 仍然采取文本生成类任务表现最优秀的编码-注意力-解码模型。
- 为了在少样本甚至零样本的任务中取得好成绩,也为了表现出很好的迁移学习的能力,同时容纳GPT和BERT的预训练方式。
利用Seq2Seq的结构同时把GPT和BERT两种不同的pretrain方法容纳在一个计算框架之下。
The MASS

- Pre-training: unlabeled data
- Fine-tuning: paired data
- Works for any NN based encoder-decoder frameworks
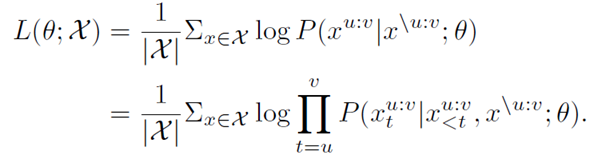
(1)decoder端其它词(在encoder端未被屏蔽掉的词)都被屏蔽掉,以鼓励decoder从encoder端提取信息来帮助连续片段的预测,这样能促进encoder - 注意力 - decoder结构的联合训练;
(2)为了给decoder提供更有用的信息,encoder被强制去抽取未被屏蔽掉词的语义,以提升encoder理解源序列文本的能力;
(3)让decoder预测连续的序列片段,以提升decoder的语言建模能力。
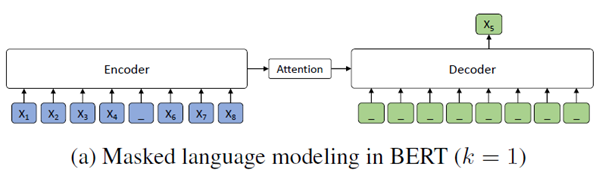
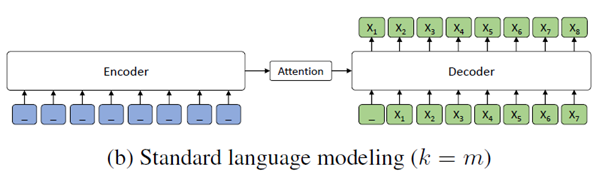

Experiments & Analysis




在Unsupervised NMT,Text Summarization 以及 Conversational Response Generation上和 BERT+LM 以及 DAE(降噪自编码器) 相比较,均优于两种方法。同时也通过实验验证了在更大的数据集上效果更好。同时也实验得出了当超参数k取50%的时候效果最好,此时相当于较好地平衡了encoder和decoder获取信息的能力。
Conclusion
- New SOTA on Machine Translation
- MASS is better than BERT + LM
- Better language modeling capability than just predicting discrete tokens
- Encourage the decoder to extract more useful information from the encoder side, rather than leveraging the abundant information from the previous tokens
Ref:
[1] BERT生成式之MASS解读
[2] 预训练模型系列-通用预训练MASS
[3] MASS: 一统GPT和BERT的Seq to Seq框架

