论文笔记[5] BERT论文梳理&模型原理详解
论文题目:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文传送门: BERT
论文团队:Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova - Google AI Language
Github:https://github.com/google-research/bert
目录
Introduction
-
Bidirectional Encoder Representations from Transformers
-
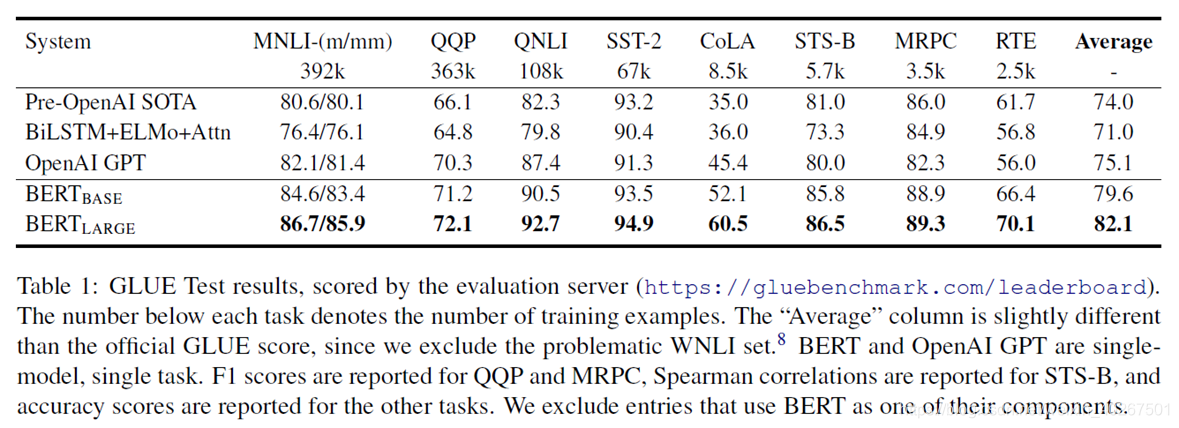
GLUE 80.5% (7.7% absolute improvement)
MultiNLI 86.7% (4.6%)
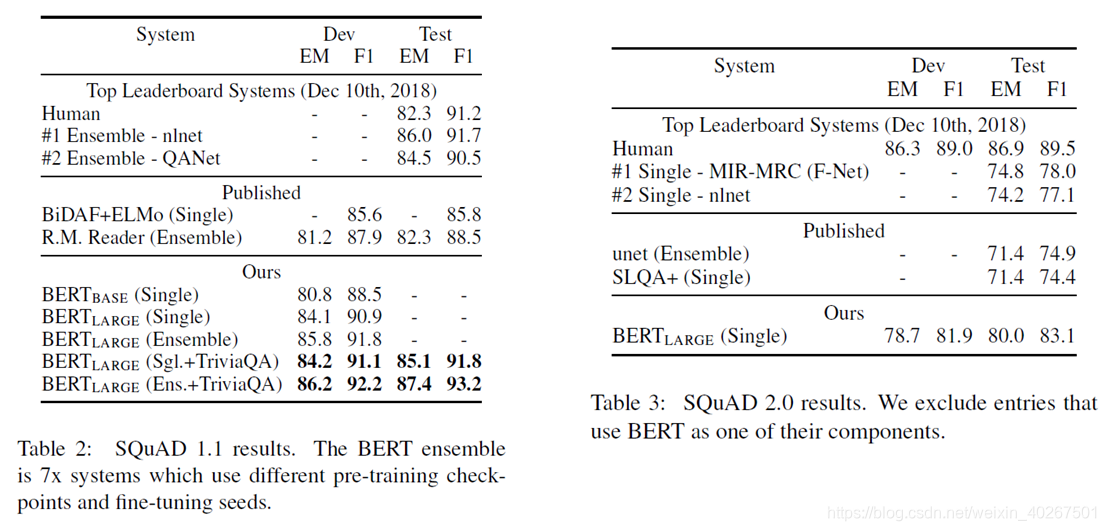
SQuAD v1.1 F1: 93.2 (1.5, 2 over human)
SQuAD v2.0 F1: 83.1(5.1)
QQP、QNLI、SST-2、CoLA、STS-B、MRPC、RTE、WNLI… -
Deep & Bidirectional & Transformer & Pre-training & Language Understanding
-
Pre-trained LRM to downstream tasks: feature based & fine-tuning based
-
Limits of standard LM: unidirectional
Sentence-level √ Token-level ×
Related Work
-
Unsupervised Feature-based Approaches
- non-neural & neural methods
- pre-trained embeddings
- eg. ELMo -
Unsupervised Fine-tuning Approaches
- pre-trained word embedding parameters from unlabeled text
- eg. GPT -
Transfer Learning from Supervised Data
- eg. fine-tune models pre-trained with ImageNet
- 学习广泛适用的words representations是活跃的研究领域。从语料中提取信息得到embeddings作为预先训练的向量。从头开始学。从左到右,或者Elmo或2个LSTMs;是基于feature的,不是深度双向结构。
- 从大量未标记的文本中预训练得到词向量,有监督的下游任务进行微调。好处是需要从头开始学的参数很少
- 大型数据集上监督任务的迁移学习
The BERT Model
1)Pre-training: unlabeled data
2)Fine-tuning: labeled data
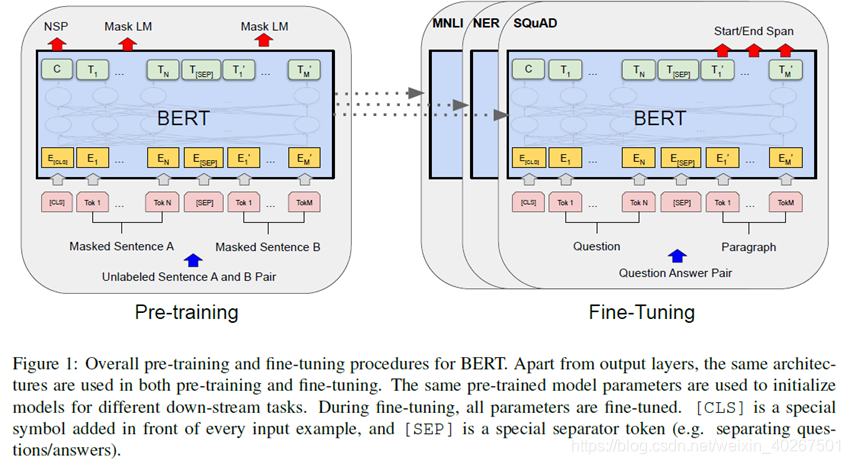
- 根据不同训练前的任务对未标记的数据进行预训练
- 对于微调,使用下游任务中标记的数据对所有参数进行微调

- Masked: attend on the generated sequence

- Trm = Transformer Block
- E N E_{N} EN = Token Embeddings + Position Embeddings + Segment Embeddings
Input Embeddings

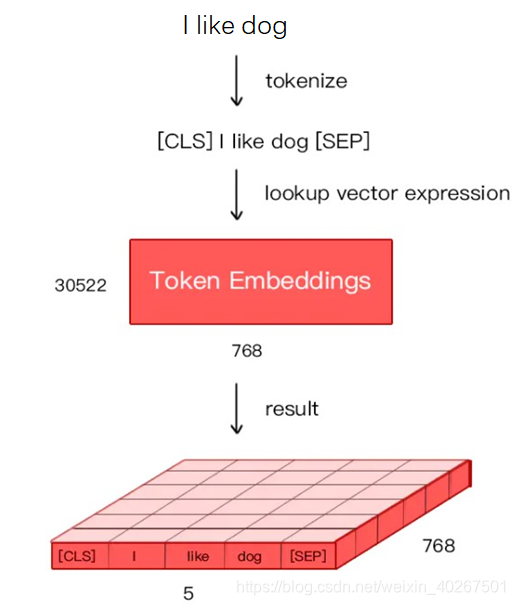
Token Embeddings
TE: 通过建立字向量表将每个字转换成一个一维向量,作为模型输入。英文词汇会做更细粒度的切分,比如playing 或切割成 play 和 ##ing,中文目前尚未对输入文本进行分词,直接对单字构成文本的输入单位。将词切割成更细粒度的 Word Piece 是为了解决未登录词的常见方法。
在tokenlization之后Bert 在处理英文文本时只需要存储 30522 个词,Token Embeddings 层会将每个词转换成 768 维向量,例子中 5 个Token 会被转换成一个 (5, 768) 的矩阵或 (1, 5, 768) 的张量。
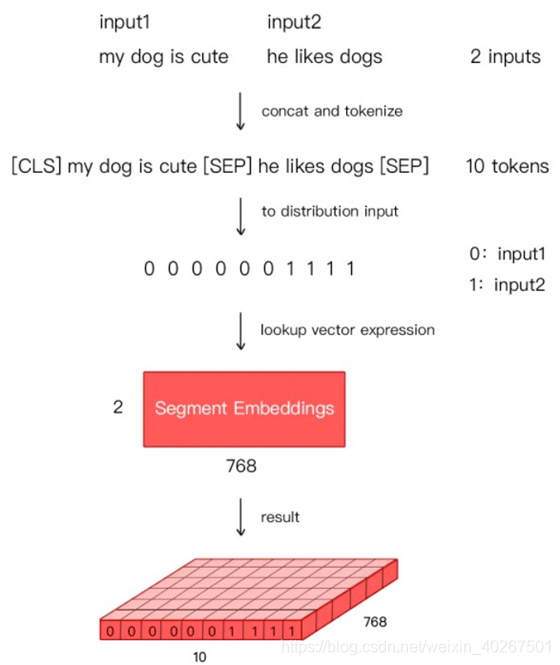
Segment Embeddings
SE:Bert 能够处理句子对的分类任务,这类任务就是判断两个文本是否是语义相似的。问答系统等任务要预测下一句,因此输入是有关联的句子。而文本分类只有一个句子,那么 Segement embeddings 就全部是 0。
Position Embeddings
PE:由于出现在文本不同位置的字/词所携带的语义信息存在差异。Transformer 中通过植入关于 Token 的相对位置或者绝对位置信息来表示序列的顺序信息。作者测试用学习的方法来得到 Position Embeddings,最终发现固定位置和相对位置效果差不多,所以最后用的是固定位置的。而正弦可以处理更长的 Sequence,且可以用前面位置的值线性表示后面的位置。

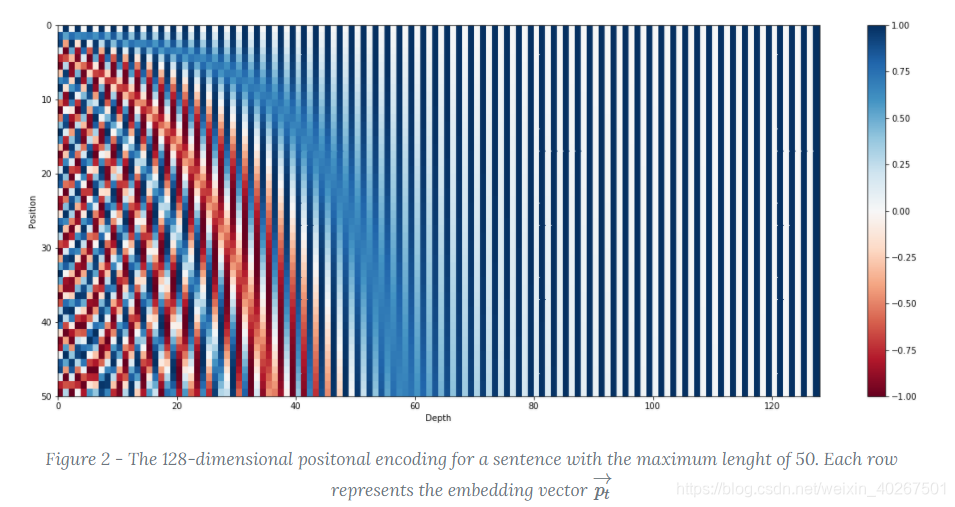
这样设计的好处是位置pos+k的positional encoding可以被位置pos线性表示,反应其相对位置关系。其实就是做了三角函数的变换,后者可以由前面的位置线性表出,从而学习到前后位置上的关系。
One-head Self-attention
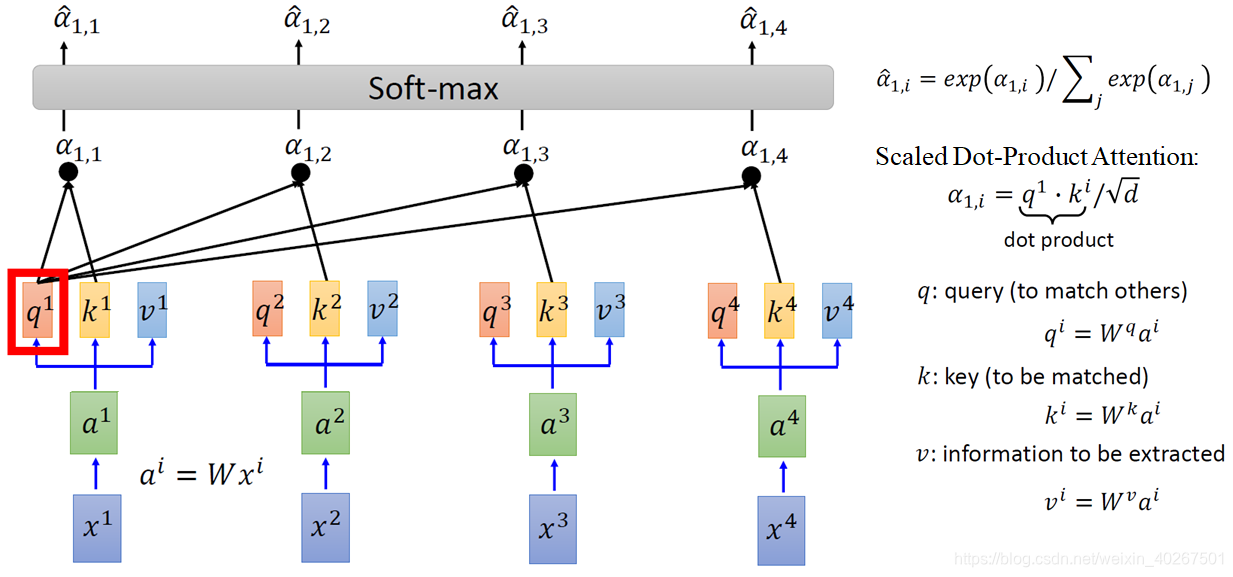
- Attention:吃两个向量 ouput一个分数
- q 和 k 做attention得到α
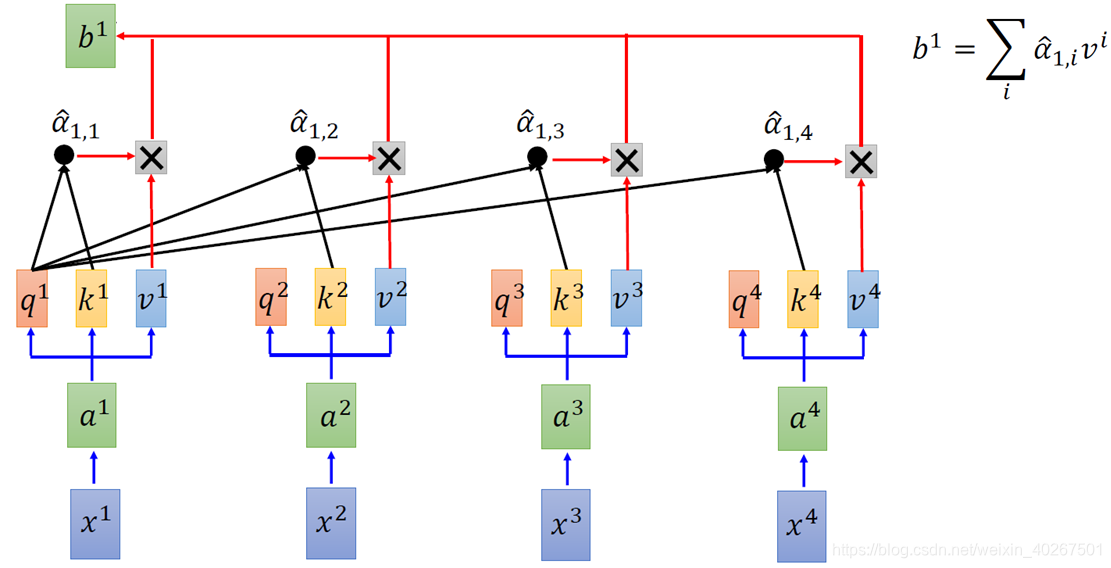
对b来说,想要得到全局信息,只需要学习到让attention的α有值;局部信息让远处的α为0即可。

Multi-head Self-attention
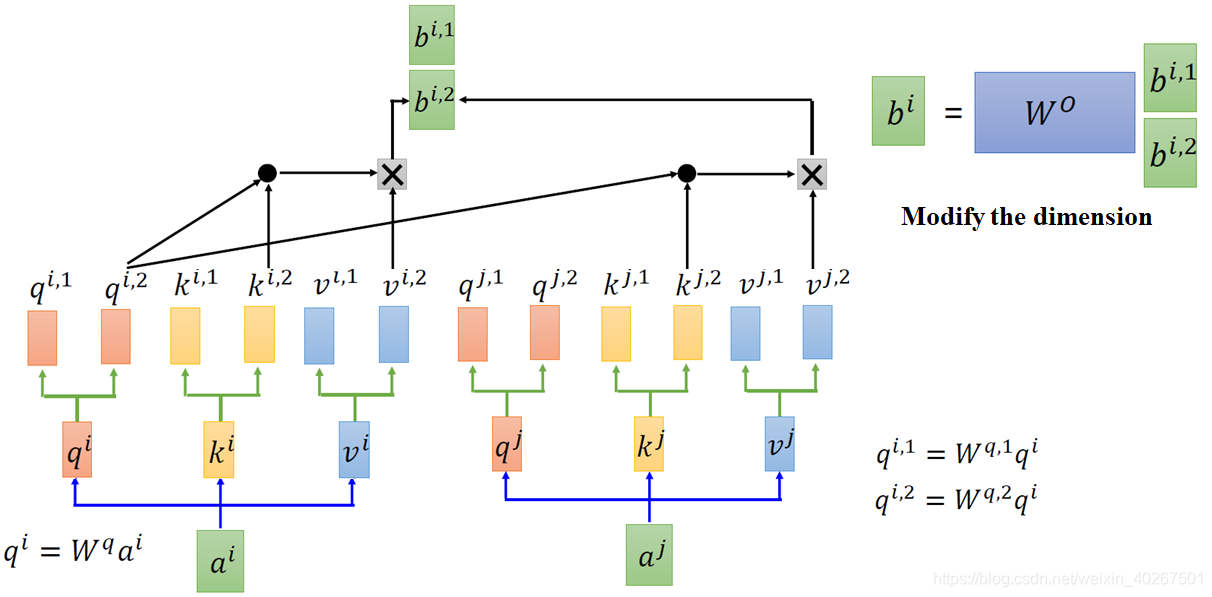
不同的head关注的点不一样。有的head看的就是local的,有的看的是global的。
Architecture
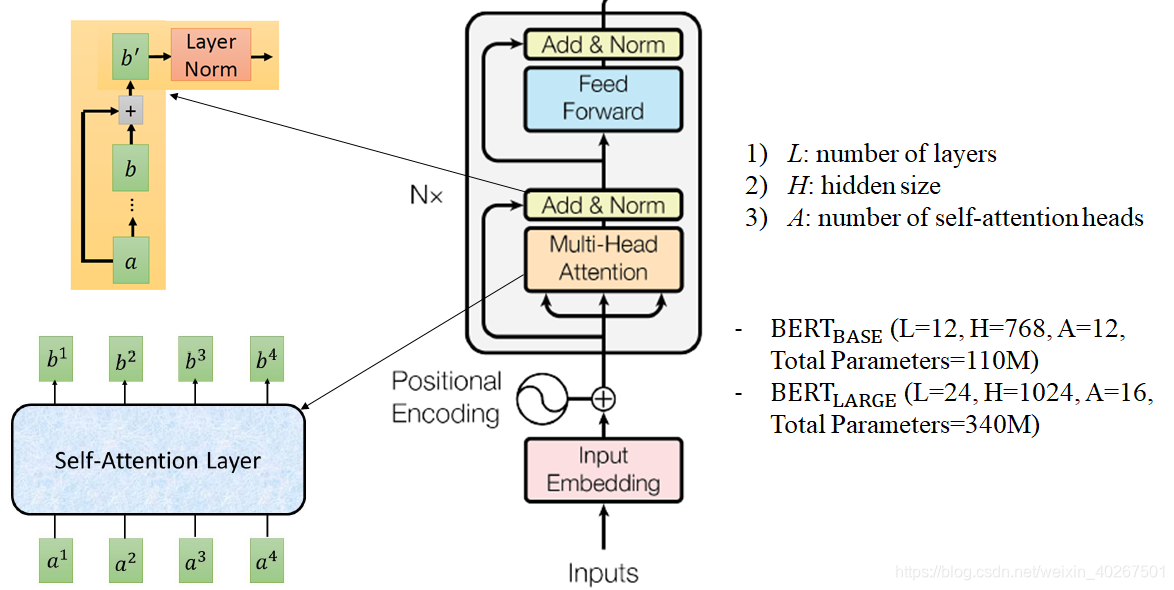
- Add操作借鉴了ResNet模型的结构,其主要作用是使得transformer的多层叠加而效果不退化。
- Layer Normalization操作对向量进行标准化,可以简化学习难度。
- Feed-Forward Layer:这里就是将Multi-Head Attention得到的提炼好的向量再投影到一个更大的空间(论文里将空间放大了4倍)在那个大空间里可以更方便地提取需要的信息(使用Relu激活函数),最后再投影回token向量原来的空间(借助SVM来理解,投影到更高维空间用超平面解决)
Pre-trained & Fine-tune
Pre-trained Methods
1) Task #1: Masked LM
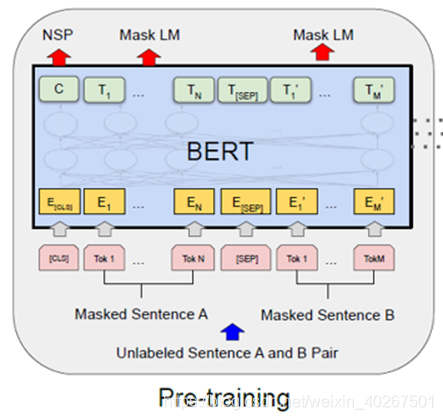
- left-to-right & right-to-left => to use bidirectional information
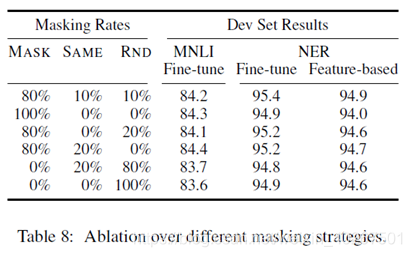
- MLM: Cloze => 15% to be masked
(1) the [MASK] token 80% of the time:my dog is hairy → my dog is [MASK]
(2) a random token 10% of the time:my dog is hairy → my dog is apple
(3) the unchanged i-th token 10% of the time:my dog is hairy → my dog is hairy
- Maked LM 是为了解决单向信息问题,现有的语言模型的问题在于,没有同时利用双向信息,如 ELMO 号称是双向LM,但实际上是两个单向 RNN 构成的语言模型的拼接,由于时间序列的关系,RNN模型预测当前词只依赖前面出现过的词,对于后面的信息无从得知。
- 全部mask会使得预训练期间会记住这些信息,但在fine-tune阶段从未看到过[mask] token,导致预训练和fine-tune信息不匹配。
2) Task #2: Next Sentence Prediction (NSP)
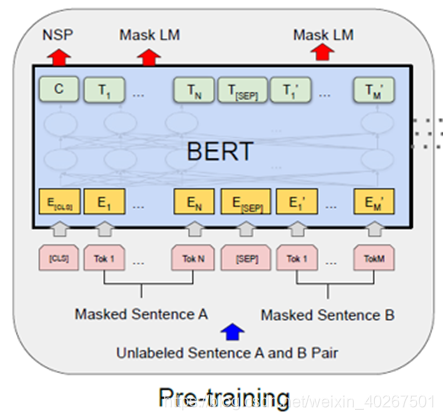
- To understands sentence relationships
- A binarized task
- sentences A and B
50% B is the actual next sentence (labeled asIsNext)
50% B is random sentence (labeled asNotNext) - very beneficial to both QA and NLI.
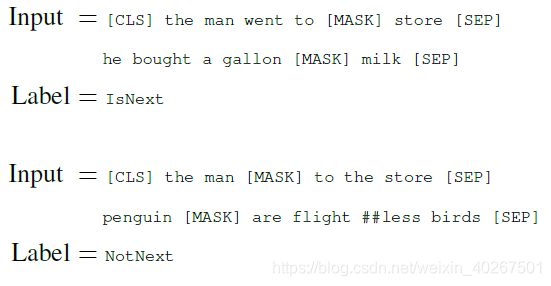
- 在许多下游任务中,如问答系统 QA 和自然语言推理 NLI,都是建立在理解两个文本句子之间的关系基础上,这不是语言模型能直接捕捉到的。
- 模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字 / 词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
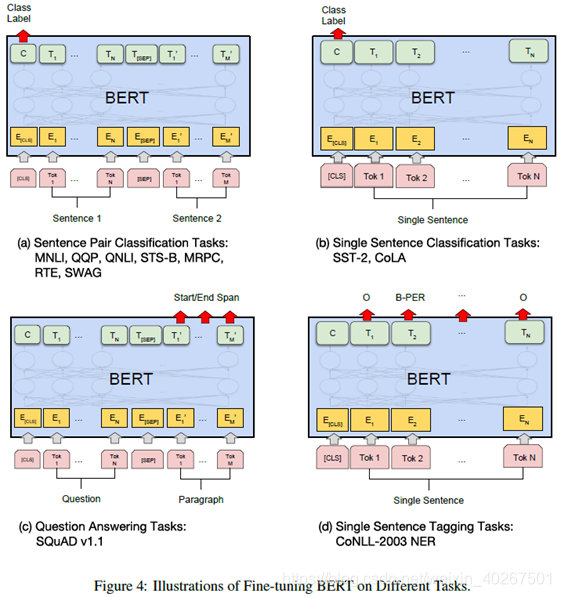
Fine-tuning BERT
Input:
(1) sentence pairs in paraphrasing
(2) hypothesis-premise pairs in entailment
(3) question-passage pairs in question answering
(4) a degenerate text-∅ pair in text classification or sequence tagging
- E: input embedding
- T i T_{i} Ti: contextual representation of token i i i
- [CLS]: special symbol for classification output
- [SEP]: special symbol to separate non-consecutive token sequences
Experiments & Results
- On GLUE
- On SQuAD v1.1 & SQuAD v2.0
Ablation Studies
- Effect of Pre-training Tasks
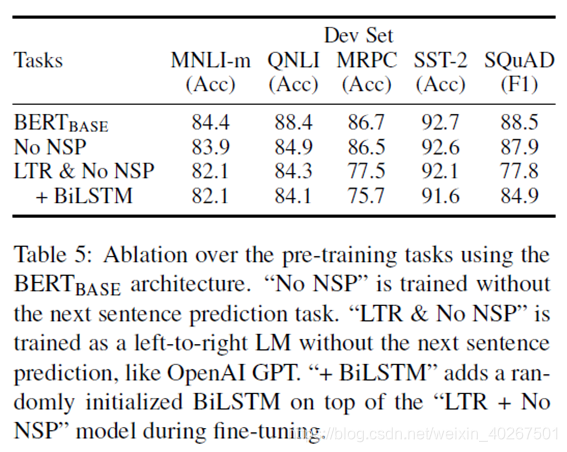
- Effect of Model Size
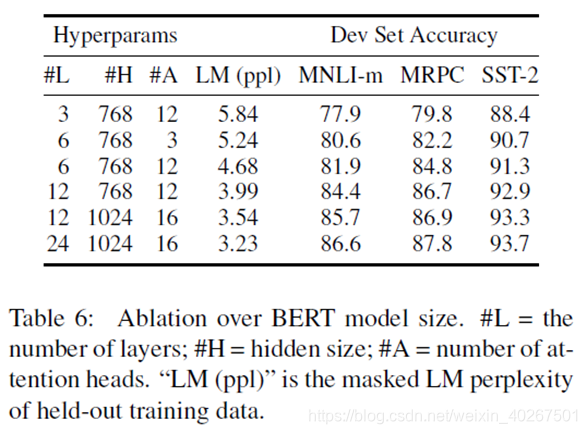
- +BiLSTM是因为LTR(left-to-right) & No NSP在SQuAD上表现得很差
- 不像ELMo那样训练单独的LTR和RTL是因为,代价是训练一个双向模型的两倍,在QA等任务上不直观(无法从右往左获取答案),不如深度双向模型强大,因为其可以在每一层同时使用左右上下文
- Feature-based Approach with BERT
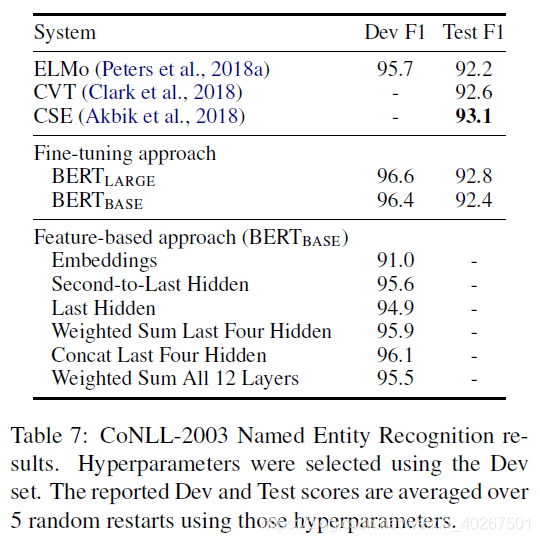
Conclusion
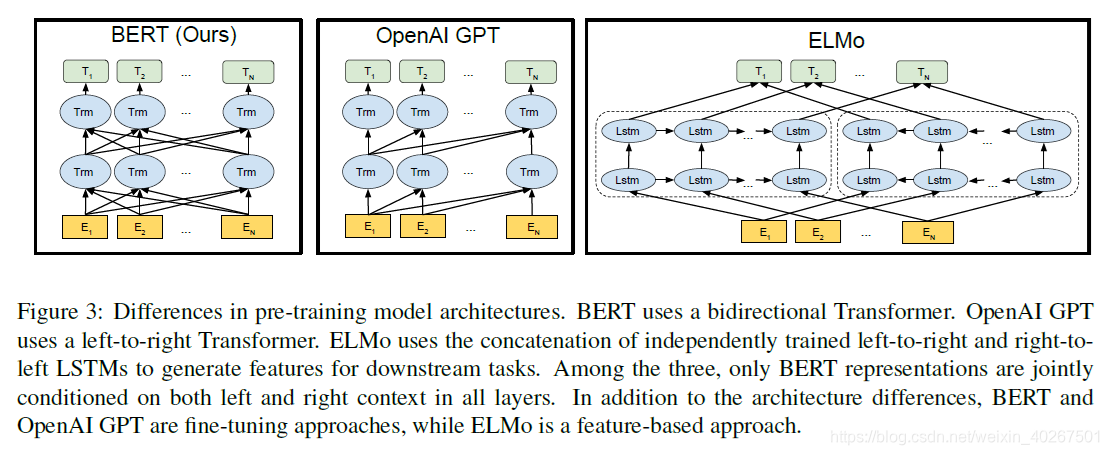
Contributions:
- Introduce Masked LM, use a bidirectional structure
- Introduce NSP, which can learn relationships of sentences
- 12L => 24L is better
- General frame for downstream tasks
Cons:
- Converge slowly
- Expensive
- etc…
Ref:
[1] 一文读懂BERT(原理篇)
[2] 全面超越人类!Google称霸SQuAD,BERT横扫11大NLP测试
[3] 论文解读:Bert原理深入浅出
[4] 深度学习:ELMO、GPT和BERT模型
[5] Transformer 详解
[6] BERT大火却不懂Transformer?读这一篇就够了
[7] Transformer Architecture: The Positional Encoding
[8] 如何优雅地编码文本中的位置信息?三种positional encoding方法简述
[9] 李宏毅老师机器学习讲义

 浙公网安备 33010602011771号
浙公网安备 33010602011771号