作业①:
import requests
from bs4 import BeautifulSoup
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
# 发送GET请求
response = requests.get(url)
response.encoding = 'utf-8'
# 解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 找到包含大学排名信息的表格
table = soup.find('table', class_='rk-table')
# 打印表头
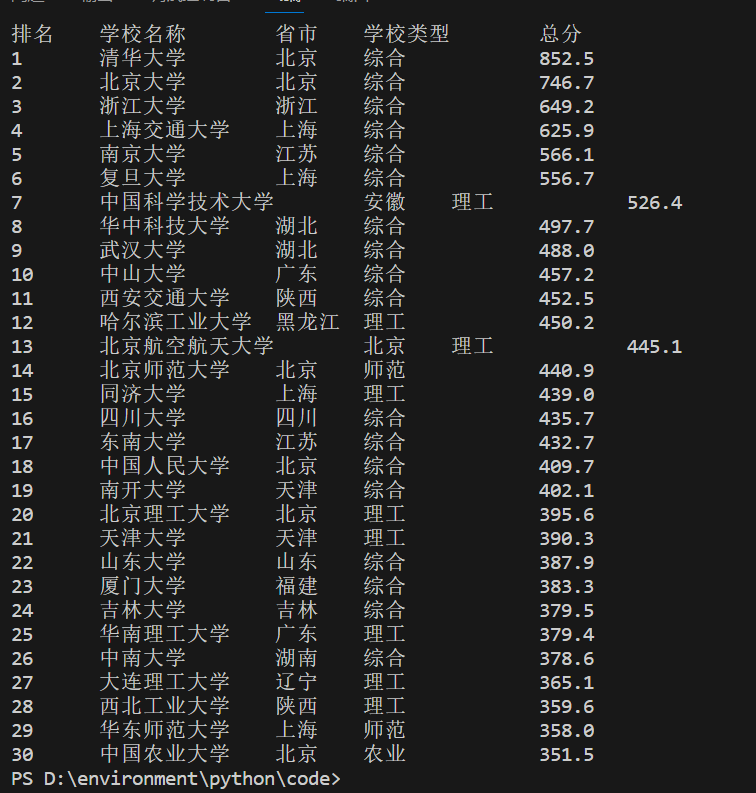
print("排名\t学校名称\t省市\t学校类型\t总分")
# 打印每一行的大学排名信息
for row in table.find_all('tr')[1:]:
cols = row.find_all('td')
rank = cols[0].text.strip()
name = cols[1].find('div',attrs={'class': 'tooltip'}).text.strip()
location = cols[2].text.strip()
university_type = cols[3].text.strip()
total_score = cols[4].text.strip()
print(f"{rank}\t{name}\t{location}\t{university_type}\t\t{total_score}")
-
2)、心得体会
- 通过这个实验我学习到了request请求页面的方式和beatifulsoupfind_all功能运用,第一次实现了爬虫。
作业②:
-
1)、用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。(我爬取了“电脑”搜索页面数据)
import threading
import urllib.request
from bs4 import BeautifulSoup
from urllib.parse import quote
import string
cookie = "unpl=JF8EAK5nNSttCEtUV04AThMRQltRW1laGUQEaTVXXA9QSgMFGQMbRUR7XlVdXxRKHx9vYRRXXFNJUQ4eASsSEXteXVdZDEsWC2tXVgQFDQ8VXURJQlZAFDNVCV9dSRZRZjJWBFtdT1xWSAYYRRMfDlAKDlhCR1FpMjVkXlh7VAQrChITFUNZVF5bOEonBF9XNVxVXEtRAysDKxMgCQkIWFoLThMAIm8MVVhQT1QFHTIaIhM; o2State={%22webp%22:true%2C%22avif%22:true}; areaId=16; ipLoc-djd=16-1303-0-0; PCSYCityID=CN_350000_350100_0; __jdu=980495117; shshshfpa=458b243c-e909-5ddb-3e05-ec8f3a8fd9f6-1694954086; shshshfpx=458b243c-e909-5ddb-3e05-ec8f3a8fd9f6-1694954086; pinId=juzGayRrpDLIl75g7SEhxbV9-x-f3wj7; pin=jd_57798e924c1ae; unick=%E6%9C%A8%E5%B7%B2%E6%88%90%E7%B2%A5_; _tp=JXCcZ2cIhfx9PzPXQDXHut8SKMGor5R2m9MMn51QOvk%3D; _pst=jd_57798e924c1ae; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_a11cd3d0087445ccb67cc9c90f1301fe|1694954216375; 3AB9D23F7A4B3CSS=jdd03DTYKTNQ35MSFG23JFXXQWY7A36YWCSO3VZJWLNHIO2GNK5RBZTLQOL2U35FF2FRK3MC5ZXQNQI6J4TLTTTSB7QR2VIAAAAMKW2VLRMAAAAAACJK72EOAOOG7MEX; _gia_d=1; shshshfpb=AAhLbqraKEoskPOkJXds-BeyPOo_Z9haUlUCGQgAAAAA; 3AB9D23F7A4B3C9B=DTYKTNQ35MSFG23JFXXQWY7A36YWCSO3VZJWLNHIO2GNK5RBZTLQOL2U35FF2FRK3MC5ZXQNQI6J4TLTTTSB7QR2VI; wlfstk_smdl=7xqbb9alctfzm4j1u8wrdzk1y604n8bu; ceshi3.com=000; TrackID=14VXMwnrAwritht3XGEE8UpDWzHkK2HCb_32rYz75asU7cmLuoCqDqgTvkj8AvvAT9VK5Jl5kAcgWxCJnCRRnnlQSdLlYkDwGtfB_Debe2RY; thor=CC38ECB5D65E19DC4C4AF893D5700688764CAB52485D42D2E4DB5D3A050A3B65A7E73796ABACAB5D9123C6EF711E7953574EF93388A0B689636A7B31208A3440A8102EC136E5B1AD7BABB1E890A59ABE9C893C8476F275299C83026DBB0A76FB0C644DF697D4D43B6D8BB16FEFD400DB96E7371165C9FDE1793AF8FFE275F2AAA068200B1109D6F9A1183DF88D7D9D33AD6BCA157BADC1A00095202A751F7E40; flash=2_3WL9ZBDmS_9ZNmmffmR65R-iy4dHp2QPBIY5KIEsVhmTEAf4vnixkmEvismX33j9jxVTAndQQLYiTt57w1saO30k3pwdHjZ4WX36lL6pcCD*; __jda=76161171.980495117.1694954083.1694954084.1695281755.2; __jdb=76161171.3.980495117|2.1695281755; __jdc=76161171"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.81"
}
headers['cookie'] = cookie
# 设置需要的变量
goods = []
lock = threading.Lock()
max_threads =2
# 定义函数search_output,用于搜索商品并将结果存储在goods列表中
def search_output(url):
global goods
url = quote(url,safe=string.printable)
req = urllib.request.Request(url,headers=headers)
req = urllib.request.urlopen(req)
req = req.read().decode('utf-8')
response = req
html = response
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('li', class_='gl-item')
for item in items:
name = item.find('div',attrs = {'class': "p-name p-name-type-2"}).text.strip()
price = item.find('div',attrs = {'class': 'p-price'}).text.strip()
goods.append((name, float(price[1:])))
# 主函数
if __name__ == '__main__':
keyword = '电脑' # 设置关键字
url = 'https://search.jd.com/Search?keyword='+str(keyword)+'&enc=utf-8'
ts = [] # 线程列表
# 搜索第一页的4商品,并添加到线程列表中
t = threading.Thread(target=search_output, args=[url])
ts.append(t)
t.start()
# 循环创建多个线程用于搜索其他页面的商品,并添加到线程列表中
for i in range(2, max_threads+1):
next_url = url + '&page=' + str(i)
t = threading.Thread(target=search_output, args=(next_url,))
ts.append(t)
t.start()
# 启动所有线程并等待它们完成
for t in ts:
t.join()
# 按价格对goods列表进行排序,并逐个输出商品名称和价格
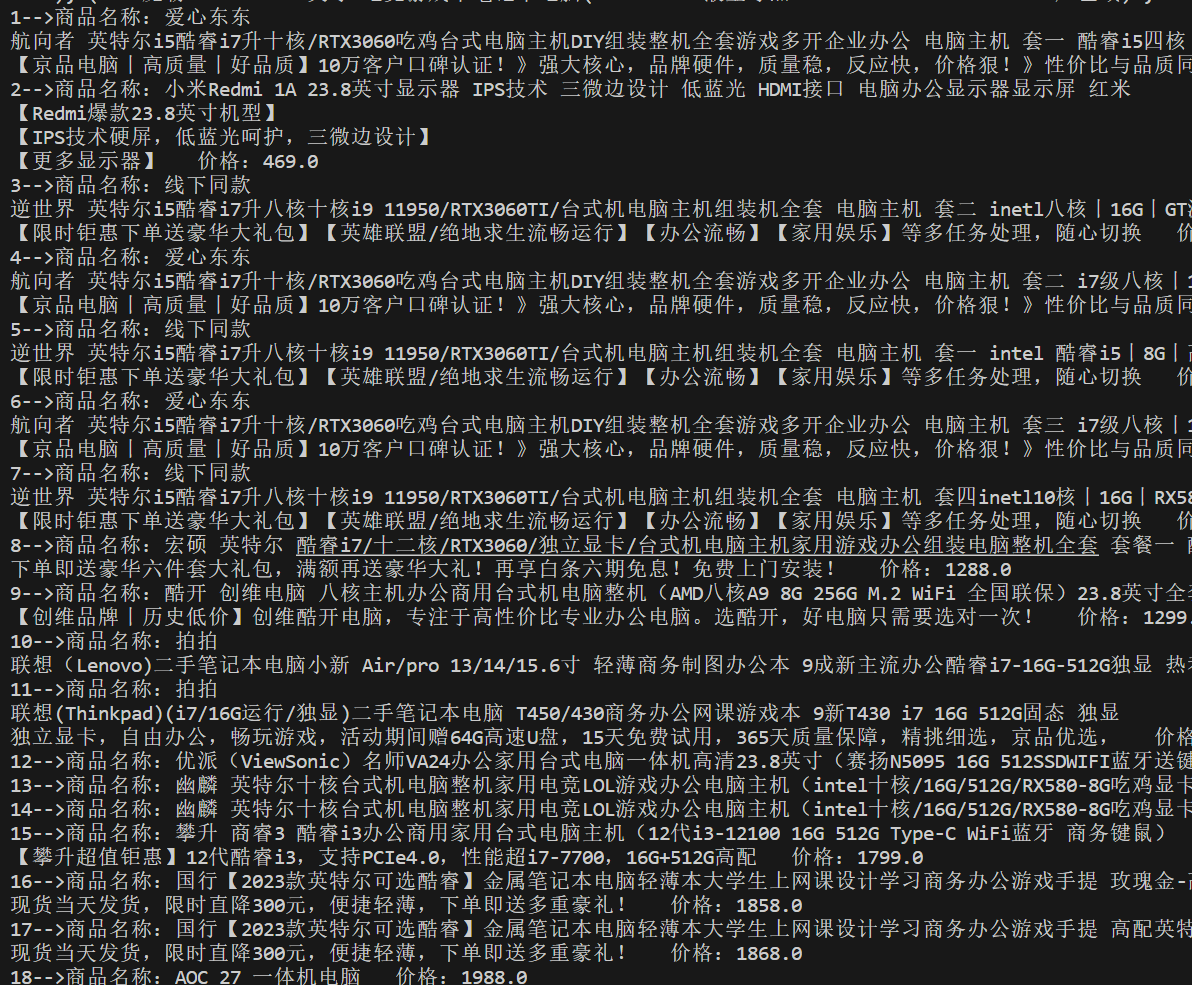
goods.sort(key=lambda x: x[1])
print(goods)
count = 1
for name, price in goods:
print(f'{count}-->商品名称:{name} 价格:{price}')
count+=1
-
2)、心得体会
- 通过这个实验我进一步学习了request方式的运用,并尝试了re库的使用,学到了cookie的相关运用,完成了对常用的京东商城进行爬虫。
作业③:
import urllib.request
import re
import os
from random import randint as ri
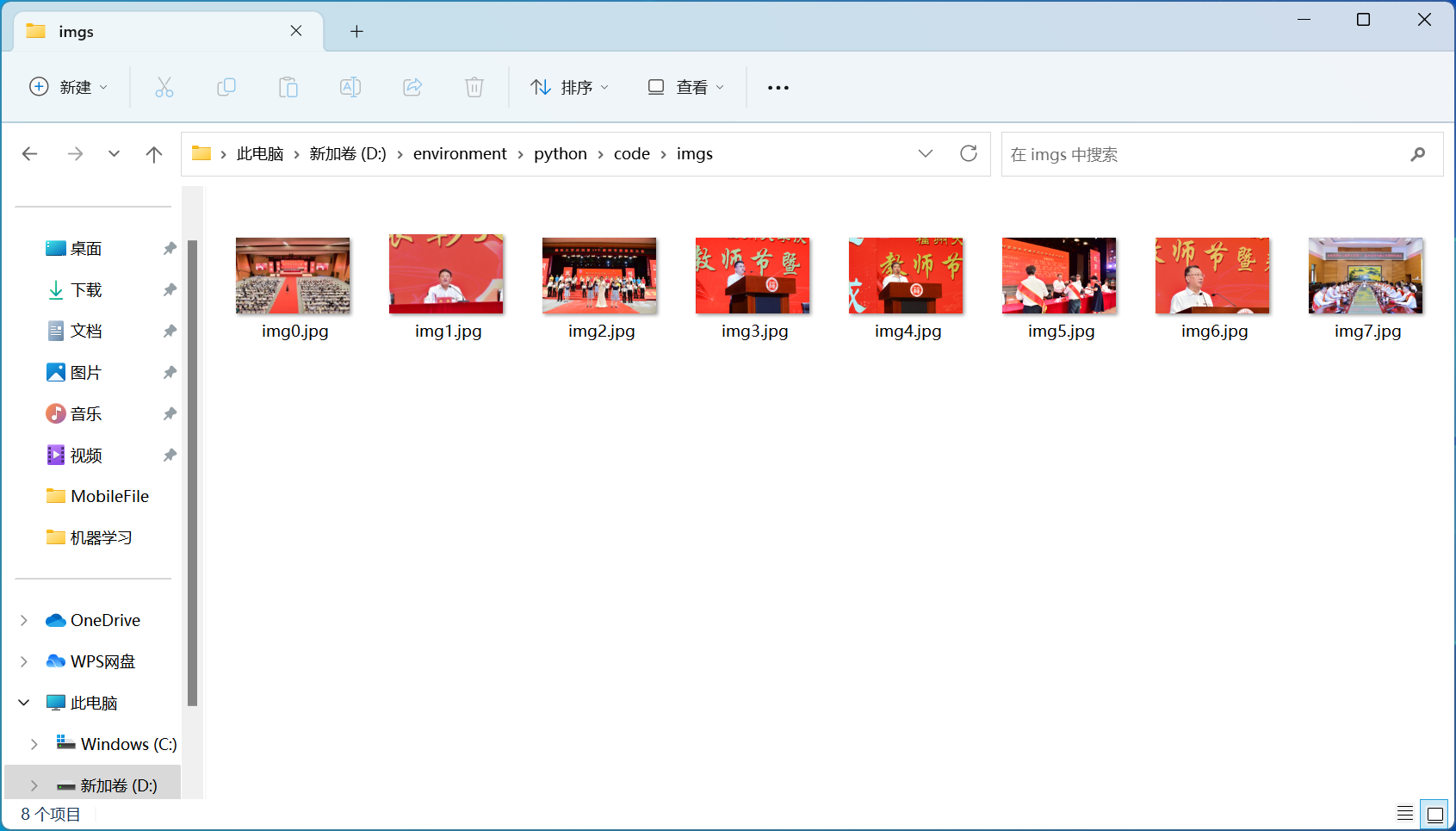
def download_images(url, save_dir):
# 创建保存图片的文件夹
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 发送HTTP请求,获取网页内容
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
# 使用正则表达式提取所有的JPEG和JPG图片链接
image_urls = re.findall('img .*?src=["\'](.*?)["\']', html)
# 下载保存图片
for image_url in image_urls:
img_name = str(ri(1,9999)) + '.jpg'
image_path = 'images/' + img_name
urllib.request.urlretrieve('https://xcb.fzu.edu.cn/'+image_url, image_path)
# 测试代码
url = 'https://xcb.fzu.edu.cn/info/1071/4481.htm'
save_dir = 'images'
download_images(url, save_dir)
-
2)、心得体会
- 在这个实验中,先发送HTTP请求,获取网页内容,再用正则表达式提取所有的JPEG和JPG图片链接,丰富了我对正则表达式的使用。


