
MIT 6.5840 2023 Spring Lab2 Raft (2A,2B,2C,2D) Summary
MIT 6.5840 2023 Spring Lab2 Raft (2A,2B,2C,2D) Summary
前言
自从4月10号写完lab1的map reduce以来,就因为毕业设计的原因,鸽了接近整整两个月。这不,大概10天前开始写lab2了。lab2总体分为四个task,难度分别为moderate,hard,hard,hard。其实吧,我个人认为难度是逐级上升的。task-A,也就是实现选举的那一部分,主要目的是熟悉代码框架及测试用例。task-B,也就是实现log复制,主要目的是为了更加熟悉raft的日志复制流程及其实现。task-C,也就是实现持久化,在这个任务中,测试用例更加复杂,可能会出现task-A和task-B都经过上万次的测试并通过,到了task-C这里会直接FAIL。因此task-C主要目的就是正确实现基本的Raft。到task-C为止,基本所有内容以及部分细节均可在论文上的figure-2中找到。接下来就是最后一个task-D,实现日志的压缩,也就是通过实现快照(snapshot)来实现日志压缩功能。这一部分论文中基本是一笔带过,然后放了个RPC的结构图就结束了。
其实本次lab我认为难点就是在task-D。由于task-D中的snapshot在论文中的篇幅很短,snapshot的大部分操作也会侵入之前的代码块,因此需要对Raft的各种细节了如指掌,也需要对之前自己写的代码了如指掌,需要了解每一行到底在做什么,会有什么影响。task-D也对snapshot的实现要求做了简化,即不用分块传输snapshot,而是一次传输一整个snapshot。
总的来说,从task-A做到task-D,就感觉是在一步一步糊屎。写task-A以及task-B的时候定的代码框架不行,导致task-C糊小屎,task-D糊大屎。折磨啊。作为过来人,建议各位同学小伙伴,如果下决心要写完这个lab,一定一定要深入理解raft。同时在写代码之前,最好过一遍四个task,然后想一下整体架构(而不是像我一样在task-A就把整体框架定了下来了了,呜呜呜,然后到了task-D就直接开始糊屎了)。
万事开头难
刚开始面对这个lab的时候,我也是比较手足无措的,不知从何下手。其实面对这种任务式的编程,并且还十分抽象的东西,确实很难找到切入点。我觉得吧,首先还是要搞明白,Raft这个东西是干啥的。千万不能为了写Raft而写Raft。。那么问题来了,Raft是干啥的?其实要找到这个答案,第一直觉就是是看论文的摘要(Abstract)。对于本次lab,还有另外一个地方可以找到答案,那就是测试用例。通过测试用例,你可以了解到,你所需要实现的这个Raft,能够干啥,实现了什么功能,给予了什么保障,这是一个很好的切入点。但是首次看测试用例也不用全部看懂,不要深究,看看顶层代码实现了什么逻辑即可,浅尝辄止即可。后续的task如果出现了奇怪的bug(特别是task-D),可以再回过头来深入看看测试用例及其框架在干什么,从而得出我们实现的raft需要给予什么样的保障。当然,也不能完全按照测试用例的逻辑来设计,尽量搞一个更加“通用”的Raft,同时兼容测试用例的情况即可。
利用好工具
-
由于这篇博客是我在完成lab2的所有task后写的,因此某些细节可能会遗忘。不过还好,由于使用了git版本控制,因此遗忘的细节可以通过每次commit的对比来进行回忆。
![]()
-
由于本次lab涉及并发编程以及模拟RPC调用,因此正常的单步调试非常难受。在初期依靠Print大法是十分有效的,但是到了后期,Print很多的时候,还是比较难受的。代码框架提供了DPrint这个函数,可以通过一个布尔值来进行开关的切换。每次DPrint,都需要打印,谁,在什么时候,干什么事,干的这件事的程度如何。简单的来说,就是需要输出Raft本身的状态及其详细的动作(jyy:程序就是状态机)。在这里建议参考Debugging by Pretty Printing这篇博文,实现直观的日志打印及parse。
-
由于本次lab涉及并发编程,程序的执行存在不确定性,因此实际上需要执行测试用例成百上千次才可以基本放心,必要时刻可以执行上万次。由于到了后期,一个测试循环可能要花费数分钟,因此需要并发测试,利用CPU的多核性能。可以利用Debugging by Pretty Printing这篇博文中提供的Python测试脚本进行并发测试。测试采用多进程模型,因此推荐在Linux环境下进行测试。而且由于windows存在windows defender这玩意,如果进程开太多,会给你扫描每个程序的,非常占内存以及CPU(我的7950X甚至都能吃到50%,巨夸张,我就开了200个进程而已)。Linux下进程创建及销毁的开销没有windows那么大,而且也没windows defender这个猪队友。
![]()
-
推荐使用Goland,JB家的IDE还是不错的,就是比较吃内存。函数跳转,变量读写标识等一系列小细节还是能够提升一定的编写效率的。最近公司搞的Rust项目也用的Clion,个人感觉比VSC+RA要好用一些。我有学生认证,所以用的是免费正版哈哈,如果有小伙伴也还在上学并且有校园邮箱,可以去搞个学生认证,很香的。
-
go-deadlock死锁检测工具。如果小伙伴的代码中出现了死锁问题,可以尝试使用该
适用于所有Task的建议及细节
- 能用一把锁就只用一把锁,一把大锁保平安(CMU-15445 lab2 并发B+ Tree血的教训),先简单且正确实现了基本逻辑再考虑更加细粒度的锁以及锁的拆分吧。
- 好好利用go提供的channel机制。同时还要注意每个goroutine的生命周期。
- reset timeout的时机尤为重要,具体可以参考6.5840中的guidance。
- 熟读Raft论文,了解其所有机制是为了解决什么问题的。(term解决了什么问题,给予了什么保障;为什么是majority;Raft论文中的5.4小节所阐述的机制解决了什么问题,以及给予了什么保障;等等等)
- 注重幂等性的设计及实现。
- 任何RPC(包括投票请求,日志复制,快照安装)均是不稳定且阻塞的。因此发送RPC之前要解锁,发送失败需要重新尝试。
- 原论文中的 \(Figure2\),需要严格遵守其阐述及判断顺序。部分额外逻辑可以添加。
- 注意所有goroutine的graceful shutdown。
- 涉及 \(slice\) 的拷贝均需要采用深拷贝,防止数据竞争。
- 防御式编程,多用panic。
- TODO(想到了再补充)。
TASK-A
具体要求这里不再赘述,到官网去看即可。这里主要讲一下一些细节上的东西。(其实,做完task-D之后,回头看在task-A中的一些细节上的东西也称不上细节了)。
部分实现细节
task-A需要实现选举流程。具体来说,就是要实现节点之间的投票逻辑、部分状态转移逻辑、超时逻辑以及部分的HeartBeat实现。
- 选举投票:当成功投出票时,投票者reset timeout(提高candidate竞选成为leader的成功率,减少election时间),相反的,如果全是拒绝投票,那么一定有其拒绝的理由,此时不应该reset timeout(加速过滤不能成为leader的candidate,加速选举出leader,自己比candidate更优,加速让自己成为candidate)。
- ticker:我个人的实现,全局只有这一个timer。leader不会被timer的超时影响。
- HeartBeat:可以先简单实现一个,不要太复杂,因为到task-B肯定要改的。
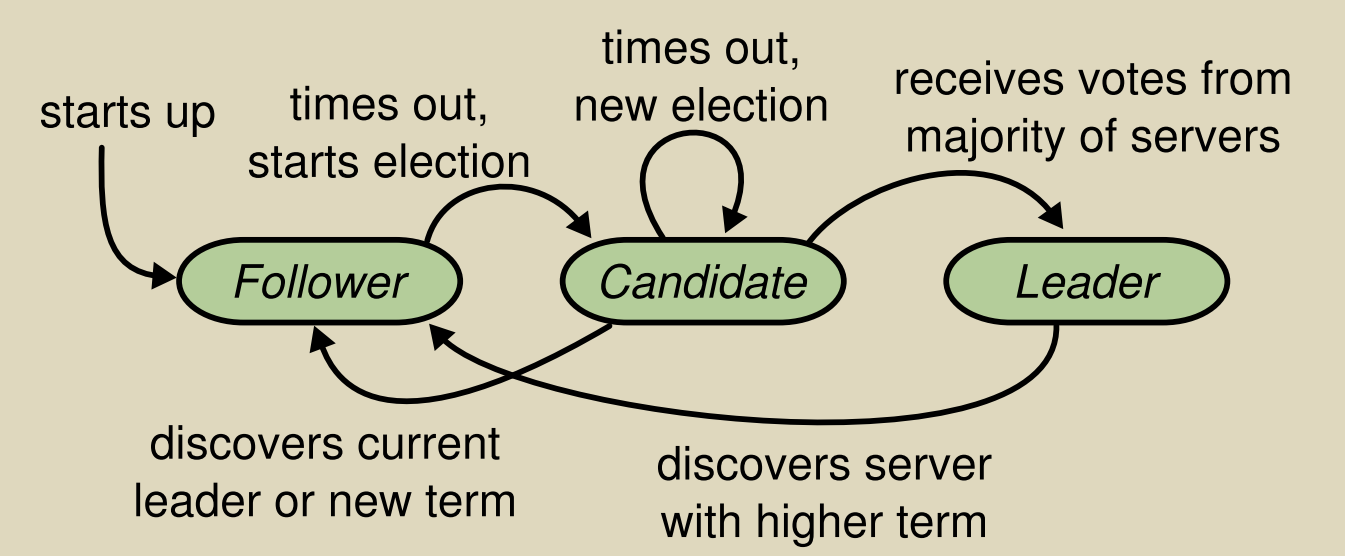
- 状态转移:根据term,进行转移。当转为follower时,需要重置票数。
具体状态转移如论文中的状态转移图所示。![]()
TASK-B
该任务需要实现日志复制。
部分实现细节
- $ Leader$ 线性接收日志,并发异步发送日志复制请求到所有 \(Follower\) 。我的实现为每个 \(Follower\) 分配一个生命周期为当前 \(term\) 的goroutine,通过channel来进行日志复制的触发。统一了HeartBeat与普通日志复制请求。同时,为了防止RPC数量过多,以及尽量一次复制多个log而不是一个一个log复制。发送规则如下:
- HeartBeat请求必须发送
- Leader每次获取一个log,会尝试触发日志复制请求,当且仅当 $nextIndex[peerId] <= LastLogIndex $时,发送日志复制请求
- 每次日志复制请求中的日志均为 $ log[nextIndex[peerId]-1:] $,即Leader中剩下的所有日志。
- 每个请求单独维护一个goroutine,在其中进行各种逻辑操作,同时以当前 \(term\) 为生命周期。
- 由于是并发的发送日志复制请求,因此对于 \(nextIndex\) 的更新需要作出特殊处理,当且仅当发送完成后的 \(nextIndex\),与发送前的 \(nextIndex\) 相同时,才允许更改 \(nextIndex\)。
- 对于接收日志,别忘了如果当前为Candidate或者term落后,需要转为Follower。
- 每次锁定时,需要判定当前goroutine的生命周期是否到期,是否为 \(Leader\)。我的判断实现如下:
func (rf *Raft) needQuitForLeaderNoneLock(term int) bool { return rf.killed() || rf.state != Leader || rf.term != term } // 首先假设当前的raft是一个leader,然后上锁,检查是否应该继续保持上锁 // 如果不满足本routine的原则,那么就直接解锁,然后返回false // 成功通过检测,则继续持有锁,然后返回true func (rf *Raft) lockWithCheckForLeader(term int) bool { rf.mu.Lock() if rf.needQuitForLeaderNoneLock(term) { rf.mu.Unlock() return false } return true }
Task-C
该任务需要实现持久化从而应对节点的崩溃。
实现细节
- 需要持久化的内存变量:
- 持久化 \(VoteFor\),防止多次投票从而违反Raft的一致性规则(主要是防止违反5.4的规则)。
- 持久化 \(term\)
- 持久化 \(logs\)
- 持久化 \(state\)(我的实现实现了state的持久化,为了快速恢复)
- 幂等性的实现尤为重要。由于RPC的不稳定性,因此可能会出现发送成功,且peer处理完成,但是peer的响应并没有成功返回,这时候请求者就会重传,但是由于之前peer已经处理过相同的逻辑了,因此需要peer返回上一次同样的reply。这时候就需要注重幂等性的设计与实现。
- TODO(想起来了再补充吧)
Task-D
这一部分也是最近才完成的,因此部分细节会记得比较清楚。
-
死锁的产生。如果你和我一样,采用一把大锁保平安,那么在Task-D中有较大概率产生死锁。这是因为测试用例的特殊性,会导致锁的顺序的问题 ( \(ApplyCh\) 和 \(rf.mu\) 之间的顺序),从而导致类似哲学家进餐问题的出现。那么选择如下:
- 当应用ApplyCh时,先解锁,然后将ApplyMsg发送到Channel,然后再上锁。这样做的优点很明显,不需要添加额外的锁。但是再次上锁之后的逻辑处理较为复杂
- 拆分锁,较为复杂。
- 使用自定义的带缓冲区的channel。
我选择的时采用带缓冲区的channel。虽然这并不能从根本上解决死锁问题,但是也算是能缓解一下吧。把channel的缓冲区开大一点就可以了。
-
\(logs\) 中逻辑 \(Index\) 与实际 \(Index\) 的转换。当没有 \(snapshot\) 时,\(snapshotLastIndex\) 就是0,以此类推,存在 \(snapshot\) 时,就需要进行 \(Index\) 的转换。这里不再赘述。
-
测试用例的特殊性。在 \(src/raft/config.go\) 的第205行,可以看到,每次应用一个snapshot时,会更改 \(lastApplied\) 变量,又由于我的实现采用缓冲区channel来进行snapshot的apply,因此会出现提交不匹配的commitIndex的情况。为了解决这个问题,每次应用snapshot的时候,均会将当前raft的commitIndex转为snapshotLastIndex。
-
leader在发送任何复制请求包括heartbeat之前,都需要检查follower是否落后,即 \(nextIndex[peerId] <= rf.snapshotIndex\), 如果落后,则需要以阻塞的形式发送snapshot。
-
同时,还会出现新的Commit晚于旧的snapshot的情况出现。为了避免这种情况造成的commit失效,我的实现保证当且仅当所有snapshot均被应用时,才允许commit index。(通过一个计数器实现,独立的goroutine维护一个计数器)。代码如下:
func (rf *Raft) solveApplyMsg(me int) { for m := range rf.MineApplyCh { if !m.CommandValid && !m.SnapshotValid || rf.killed() { return } rf.CallerApplyCh <- m if m.SnapshotValid { rf.snapshotApplyOkChan <- true } } } func (rf *Raft) solveSnapshotPendingOkChan() { for _ = range rf.snapshotApplyOkChan { rf.mu.Lock() rf.snapshotApplyPendingNum -= 1 rf.mu.Unlock() } } . . . rf.MineApplyCh <- ApplyMsg{ CommandValid: false, SnapshotValid: true, Snapshot: clone(rf.snapshot), SnapshotIndex: rf.snapshotLastIndex, SnapshotTerm: rf.snapshotLastTerm, } rf.snapshotApplyPendingNum += 1 . . .
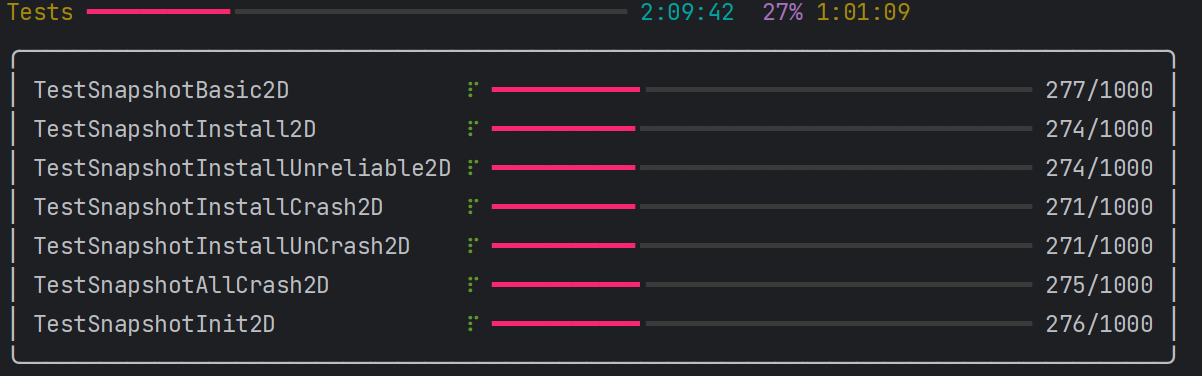
写博客的过程中,正好跑了一波task-D的1000次测试。结果如下图所示。
修改及补充
taskA
taskB
taskC
taskD
本次修改主要对taskD进行修改,舍弃了基于缓冲区channel的applier实现,转而使用基于条件变量(cond)的applier实现。彻底解决了死锁问题,替换了缓冲区channel这一临时方案。
在之前的基于buf的实现中,snapshot的install与snapshot的applier是完全同步的,CommitIndex的变化与实际CommandApply也是完全同步的。在这种双同步的设计下,产生了一个非常畸形且奇怪的设计。。在新的设计中,我取消了这两种同步。对于taskD的修改基本上可以说是重写了,折磨阿,更折磨的是还得重新debug。
在新的applier实现中,使用基于条件变量的方案,commitIndex的变化与apply不同步,snapshot的install与apply不同步。基于非同步的设计,我实现了一个统一command apply与snapshot apply的goroutine。
之前根本没用上的lastApplied变量也在新的方案中用上了。
一些细节:
- snapshot的apply中,snapshotLastIndex应该是单调递增的。通过一个 \(LastAppliedSnapshotIndex\) 来进行控制。\(LastAppliedSnapshotIndex\) 的初始值应该是 持久化中 的snapshotLastIndex值(如果直接使用rf.snapshotIndex, 有可能这个snapshotIndex小于持久化中的snapshot,最后导致lastApplied与snapshotIndex不同步,从而导致数组下标为负数。总的来说就是,snapshotIndex应该是单调递增的,从持久化中的snapshot相关参数开始递增)。我的实现通过applier的参数传入实现 \(LastAppliedSnapshotIndex\) 初始化,保证递增从 \(持久化\) 中的snapshotIndex开始。
- 每次将applyMsg 传入 ApplyCh时,不能持有锁。
- lastApplied应该与apply同步而不是与commitIndex与snapshot install同步。
- 由于测试要求apply的oerder需要严格按照单增顺序,且在测试中,要求 \(nowApplyIndex == lastApplied + 1\) ,不能出现乱序及跳过某个index或者产生回退[不然会产生类似错误
apply error: server x apply out of order, expected index n, got m](snapshot apply造成的回退是可以接受的)。 - command apply 与 snapshot apply 应该严格串行实现。我通过applier,实现了统一的apply,从而实现了串行。
总结
基于缓冲区channel并发循环测试10000遍通过图
(碎碎念:Linux下的截图好糊啊)
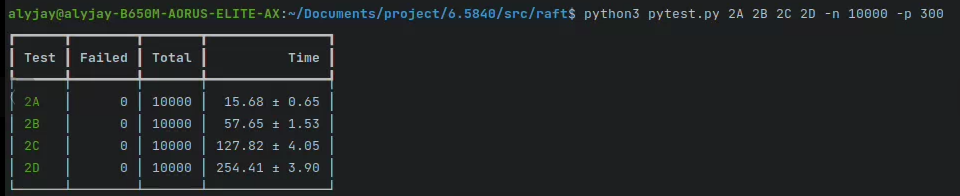
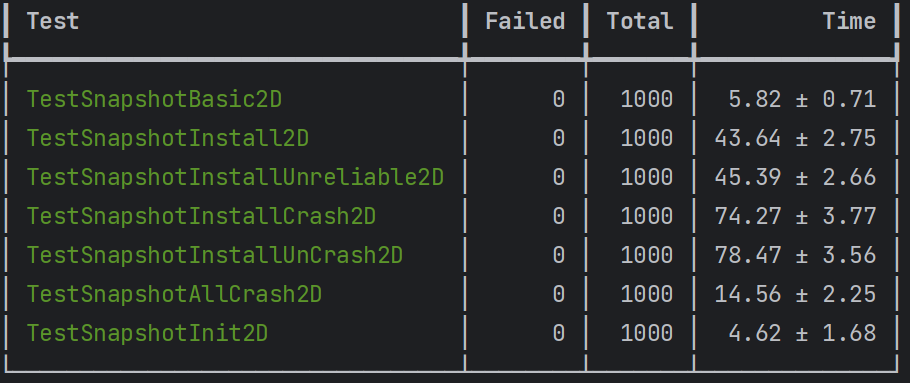
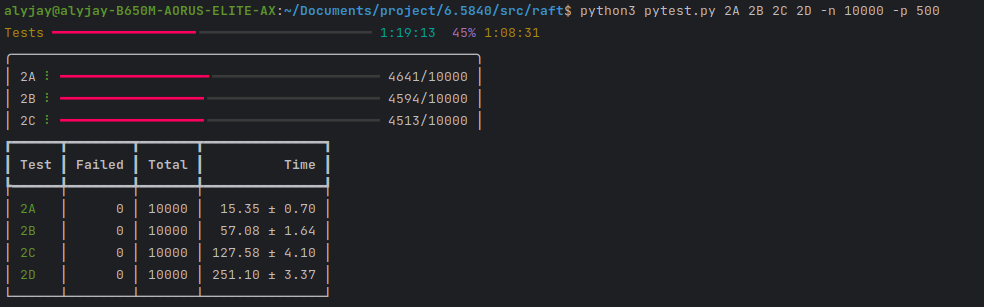
统一snapshot apply 与 command apply 的新applier并发循环测试10000遍通过图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号