实验2 多个逻辑段的汇编源程序编写与调试
多个逻辑段的汇编源程序编写与调试
实验任务1
-
任务1-1
对程序task1_1.asm进行汇编、连接,用debug加载、跟踪调试,基于结果,回答问题。
assume ds:data, cs:code, ss:stack data segment db 16 dup(0) data ends stack segment db 16 dup(0) stack ends code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 16 mov ah, 4ch int 21h code ends end start问题1:
查看寄存器值
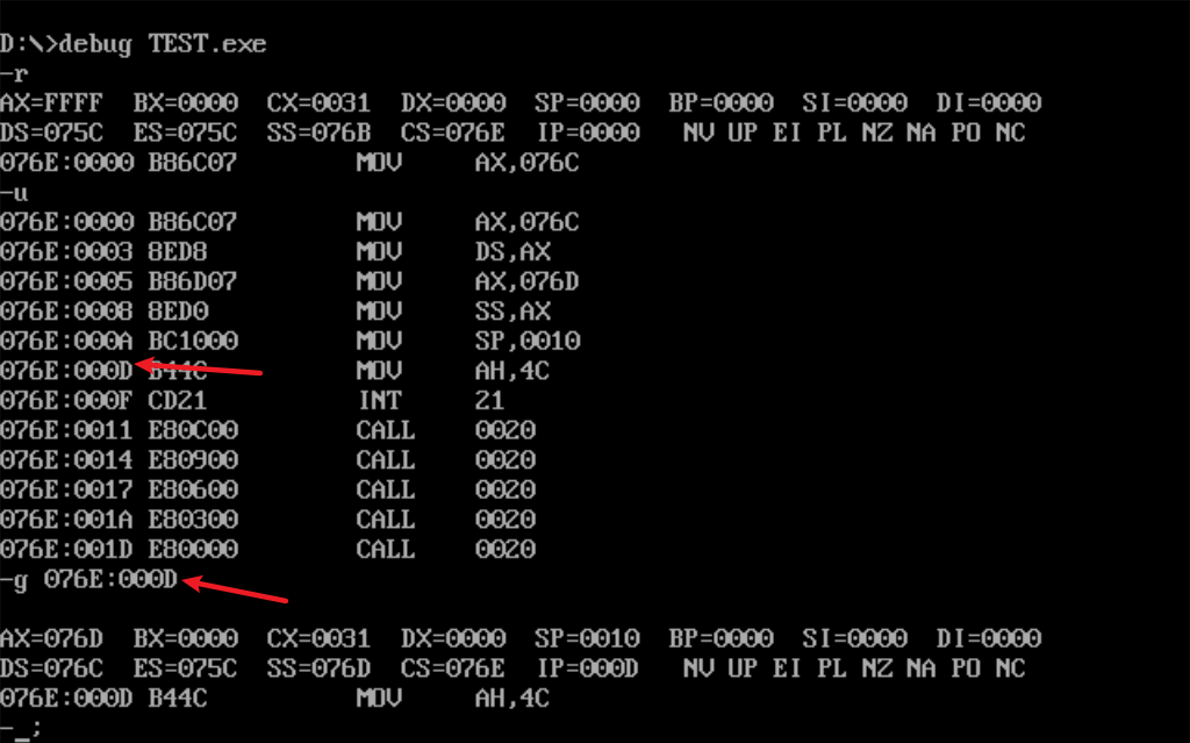
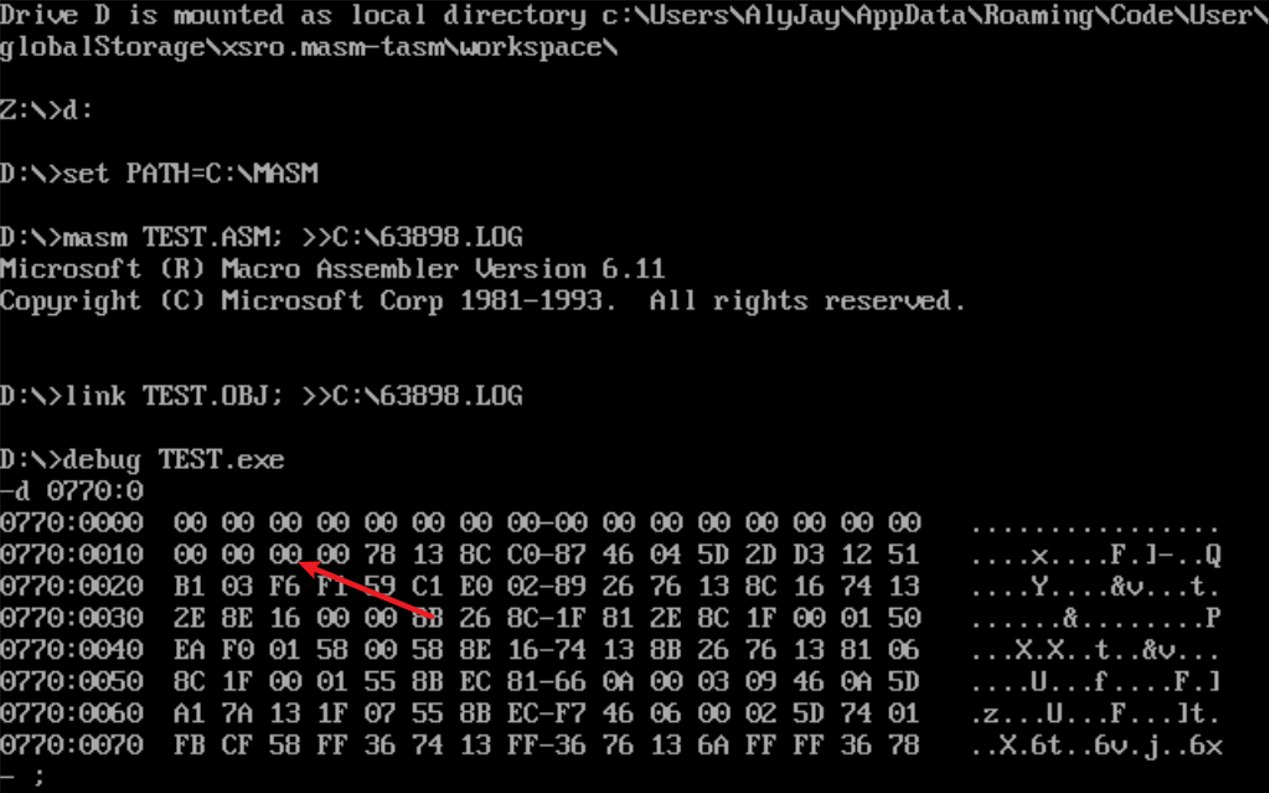
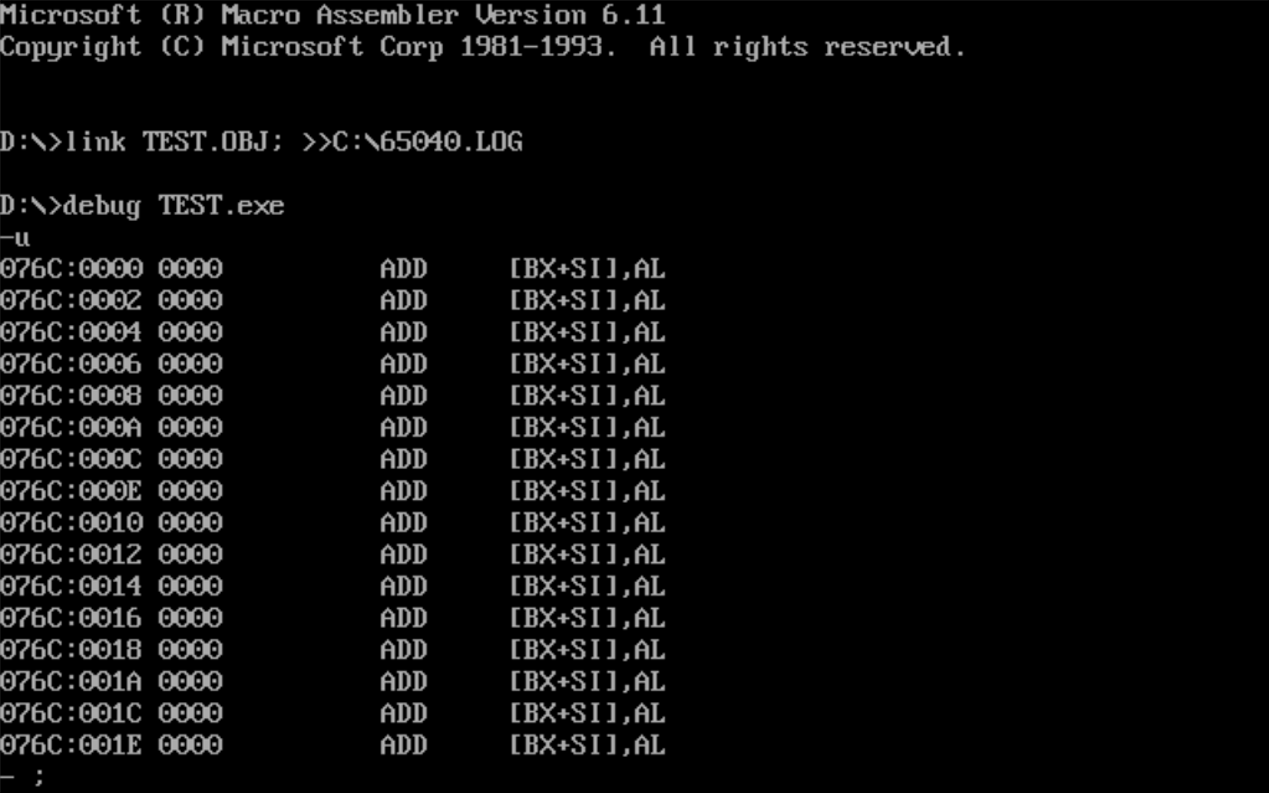
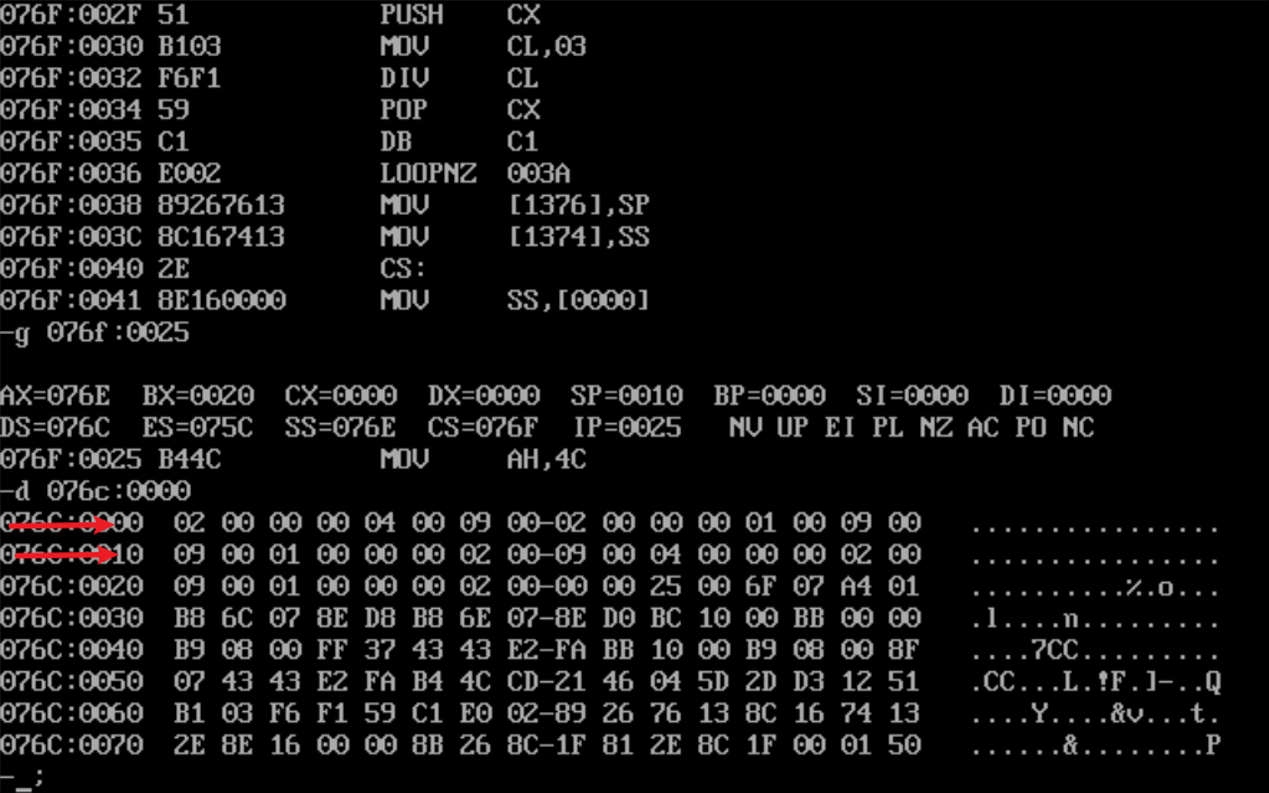
使用U命令查看反汇编代码,找到mov ah,4ch这一代码的内存地址,并使用G命令快速执行到这条命令之前。
![]()
(DS)=076C
(SS)=076D
(CS)=076E
问题2:
假设程序加载后,CODE段地址为X,则data段地址为X-2,stack段地址为X-1
由于程序占用的内存空间是连续的,又由于段大小占16字节的整数倍,所以如果按照task1-1.ASM的代码,data紧挨着程序段前缀,stack紧挨着data,code紧挨着stack。 -
任务1-2
对程序task1_2.asm进行汇编、连接,用debug加载、跟踪调试,基于结果,回答问题。assume ds:data, cs:code, ss:stack data segment db 4 dup(0) data ends stack segment db 8 dup(0) stack ends code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 8 mov ah, 4ch int 21h code ends end start问题1:
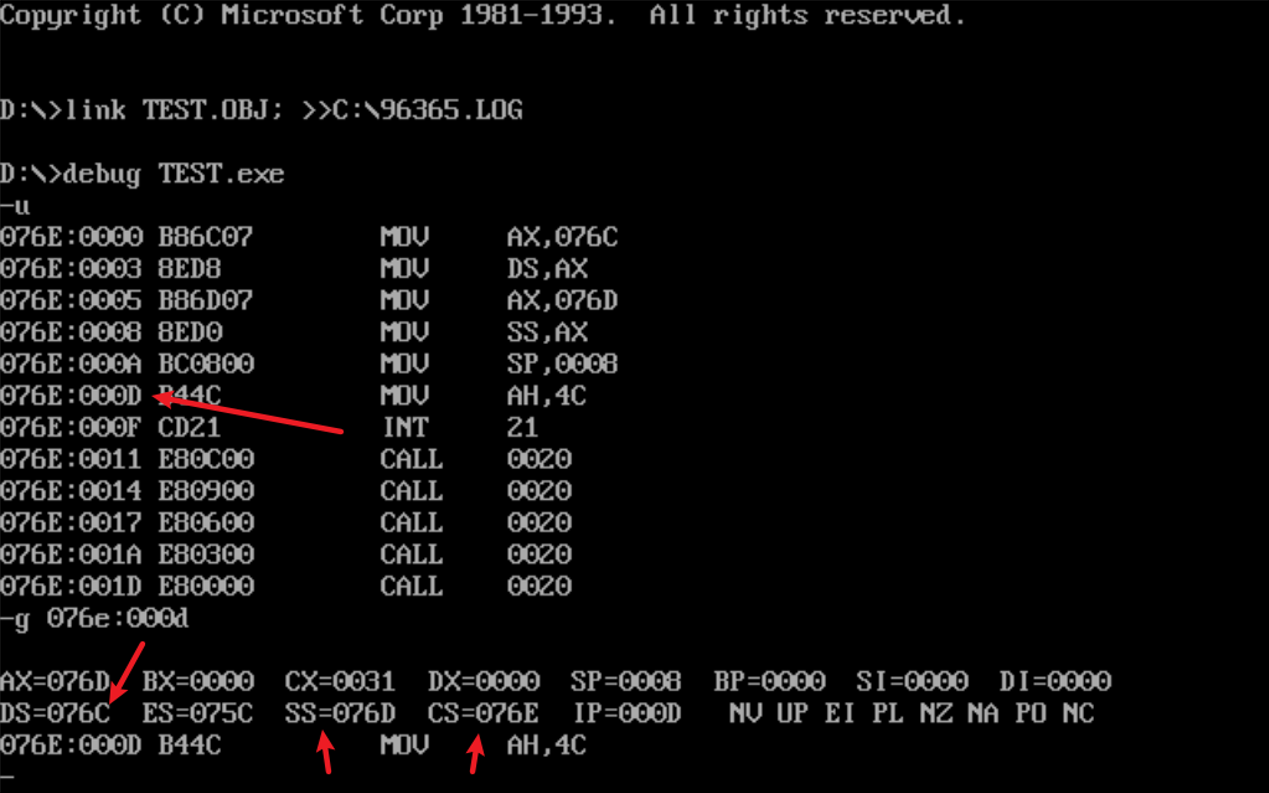
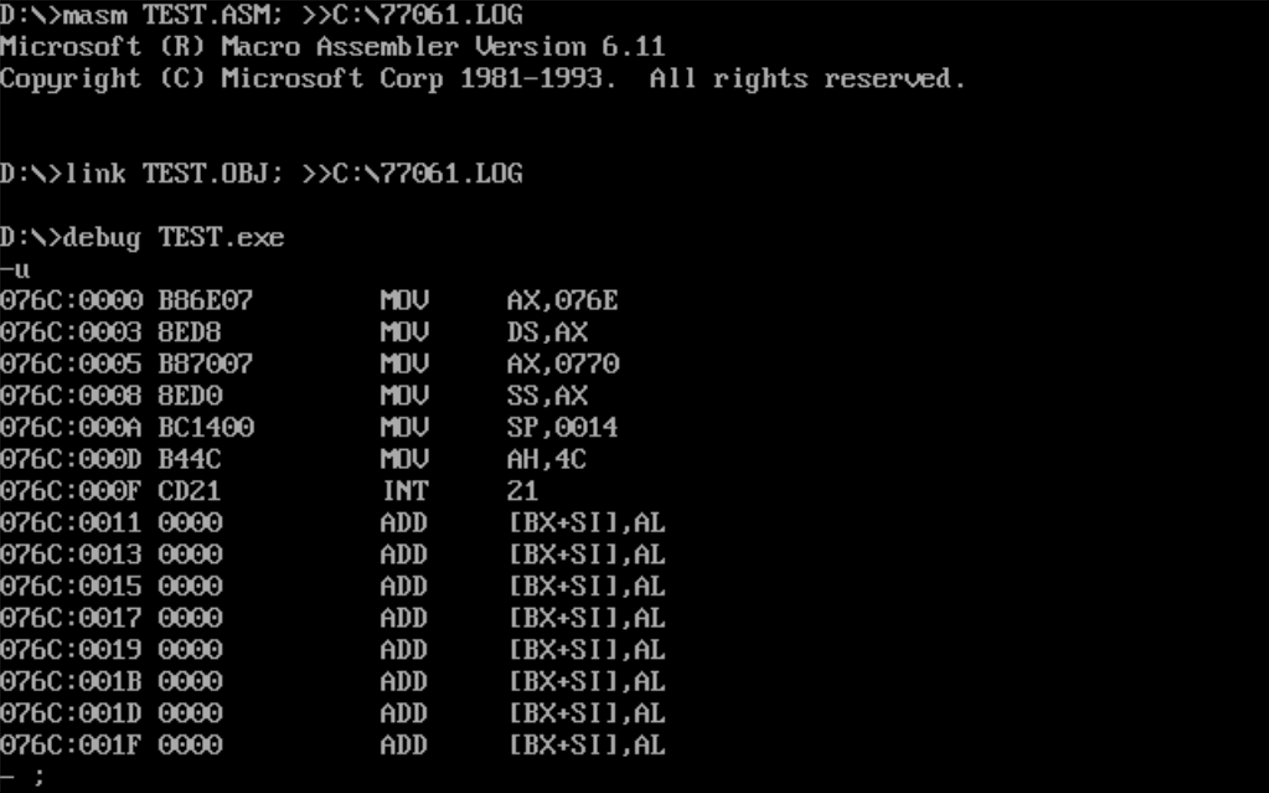
重复task1-1的问题1的操作,查看寄存器值
![]()
(DS)=076C
(SS)=076D
(CS)=076E
问题2:
假设程序加载后,CODE段地址为X,则data段地址为X-2,stack段地址为X-1
由于程序占用的内存空间是连续的,又由于段大小占16字节的整数倍,所以如果按照task1-2.ASM的代码,data紧挨着程序段前缀,stack紧挨着data,code紧挨着stack。 -
任务1-3
对程序task1_3.asm进行汇编、连接,用debug加载、跟踪调试,基于结果,回答问题。assume ds:data, cs:code, ss:stack data segment db 20 dup(0) data ends stack segment db 20 dup(0) stack ends code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 20 mov ah, 4ch int 21h code ends end start问题1:
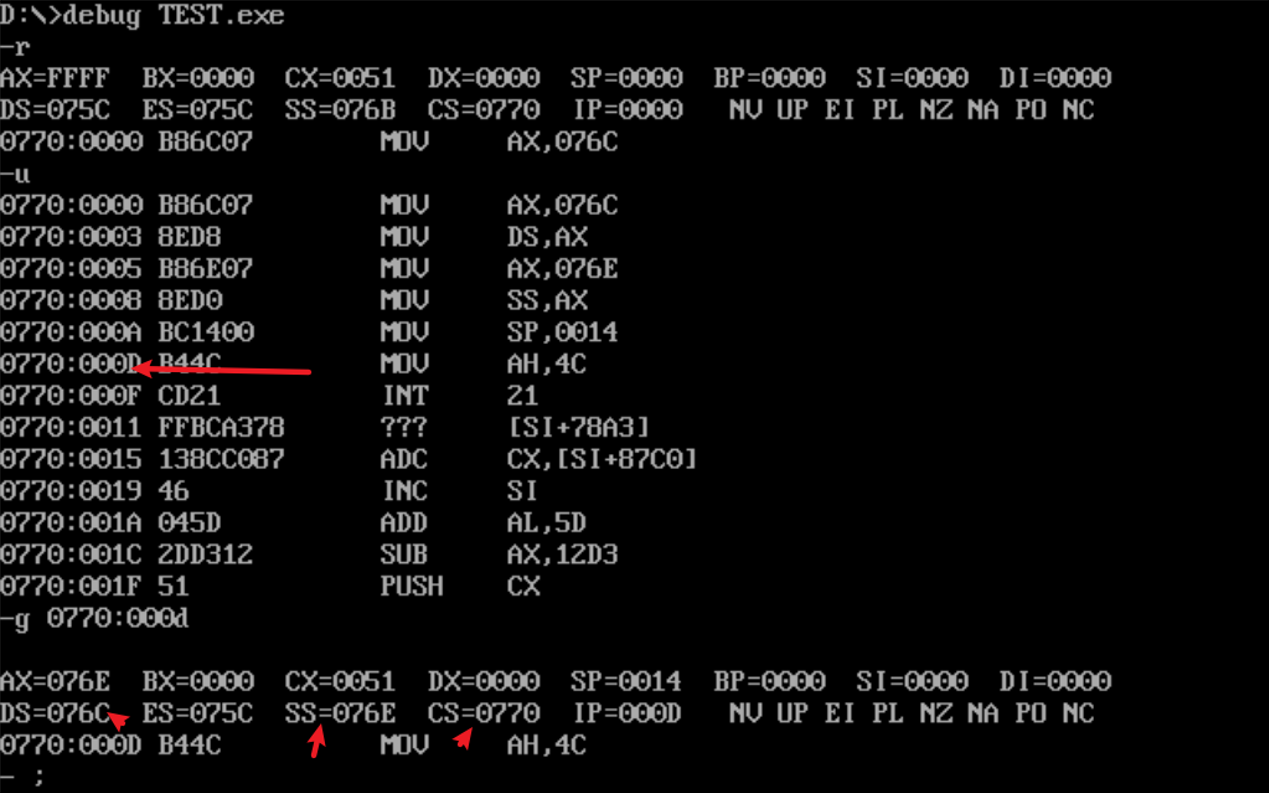
重复task1-1和task1-2的操作,结果如下
![]()
(DS)=076C
(SS)=076E
(CS)=0770
问题2:
假设程序加载后,CODE段地址为X,则data段地址为X-4,stack段地址为X-2
由于程序占用的内存空间是连续的,又由于段大小占16字节的整数倍,所以如果按照task1-3.ASM的代码,data紧挨着程序段前缀,stack紧挨着data,code紧挨着stack。 -
任务1-4
对程序task1_4.asm进行汇编、连接,用debug加载、跟踪调试,基于结果,回答问题。assume ds:data, cs:code, ss:stack code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 20 mov ah, 4ch int 21h code ends data segment db 20 dup(0) data ends stack segment db 20 dup(0) stack ends end start问题1:
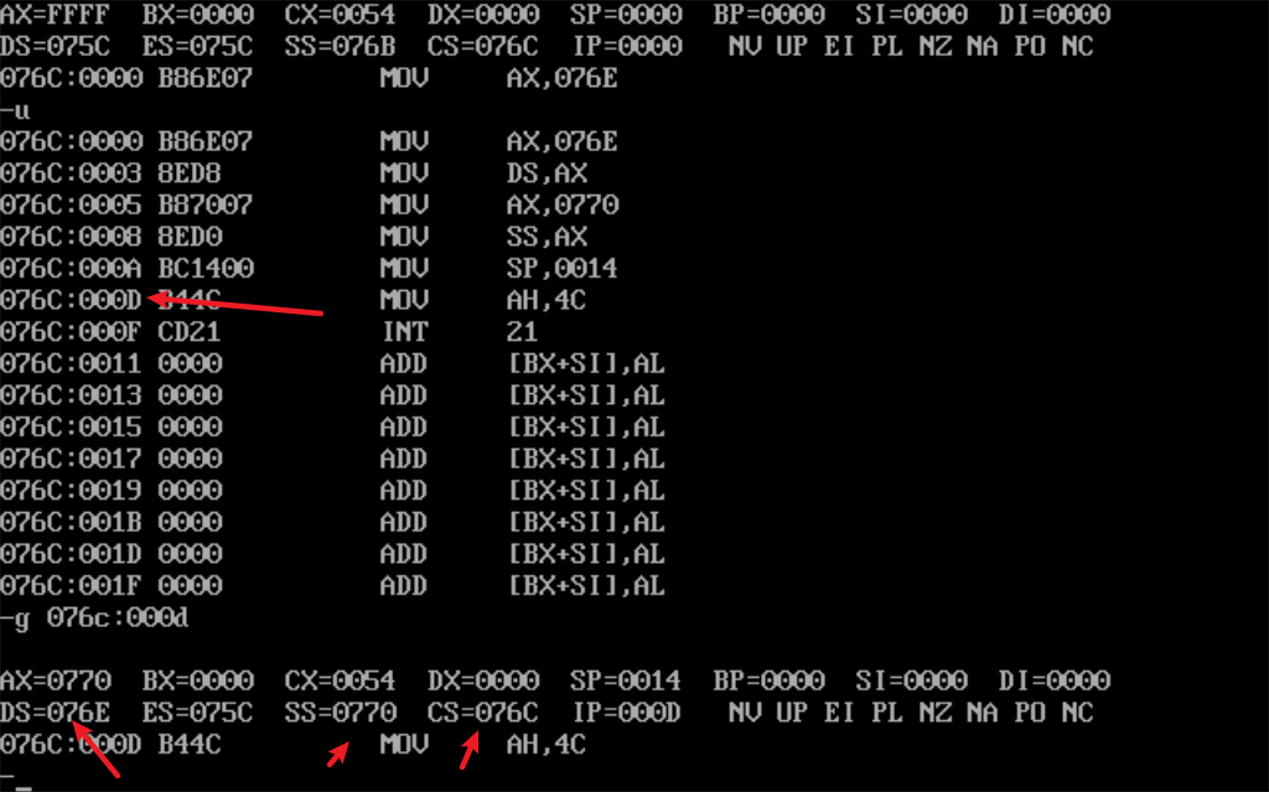
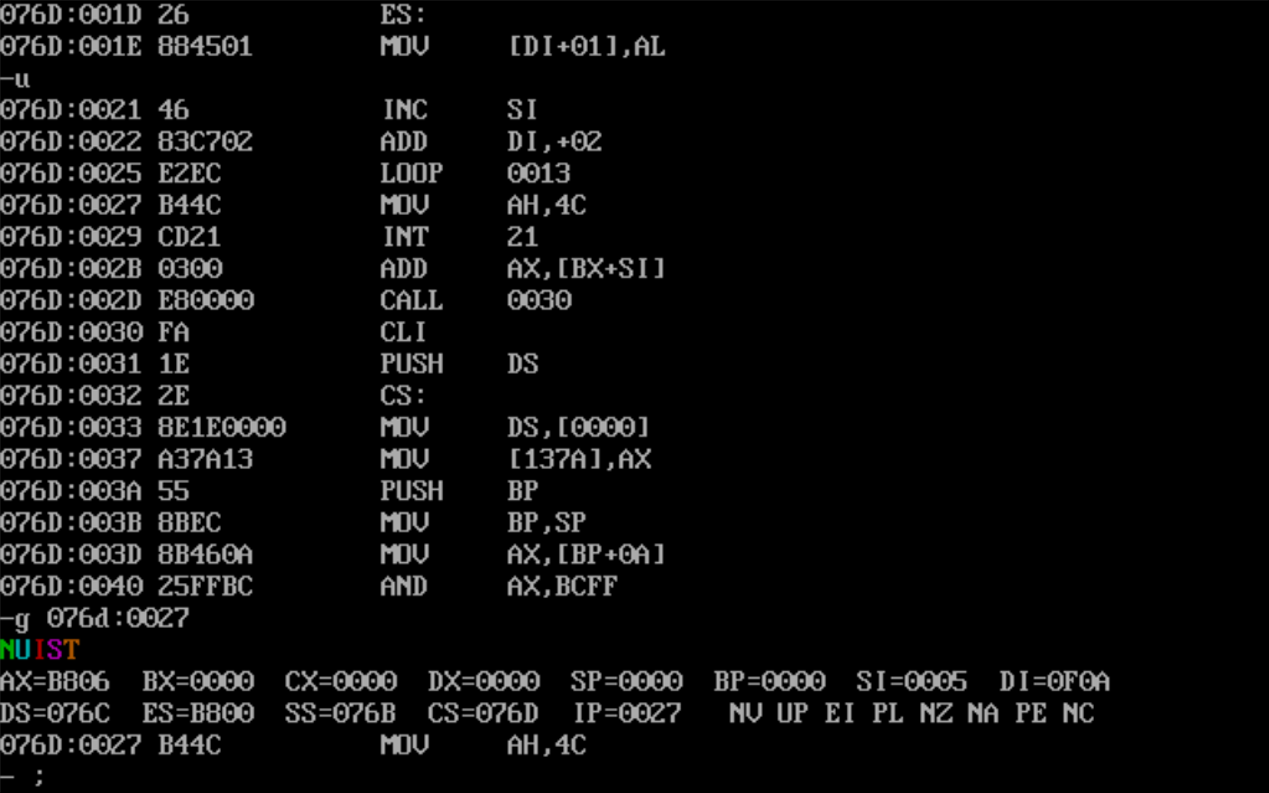
重复操作,查看寄存器值
![]()
(DS)=076E
(SS)=0770
(CS)=076C
问题2:
假设程序加载后,CODE段地址为X,则data段地址为X+2,stack段地址为X+4
由于程序占用的内存空间是连续的,又由于段大小占16字节的整数倍,所以如果按照task1-4.ASM的代码,code紧挨着程序段前缀,data紧挨着code,stack紧挨着data。
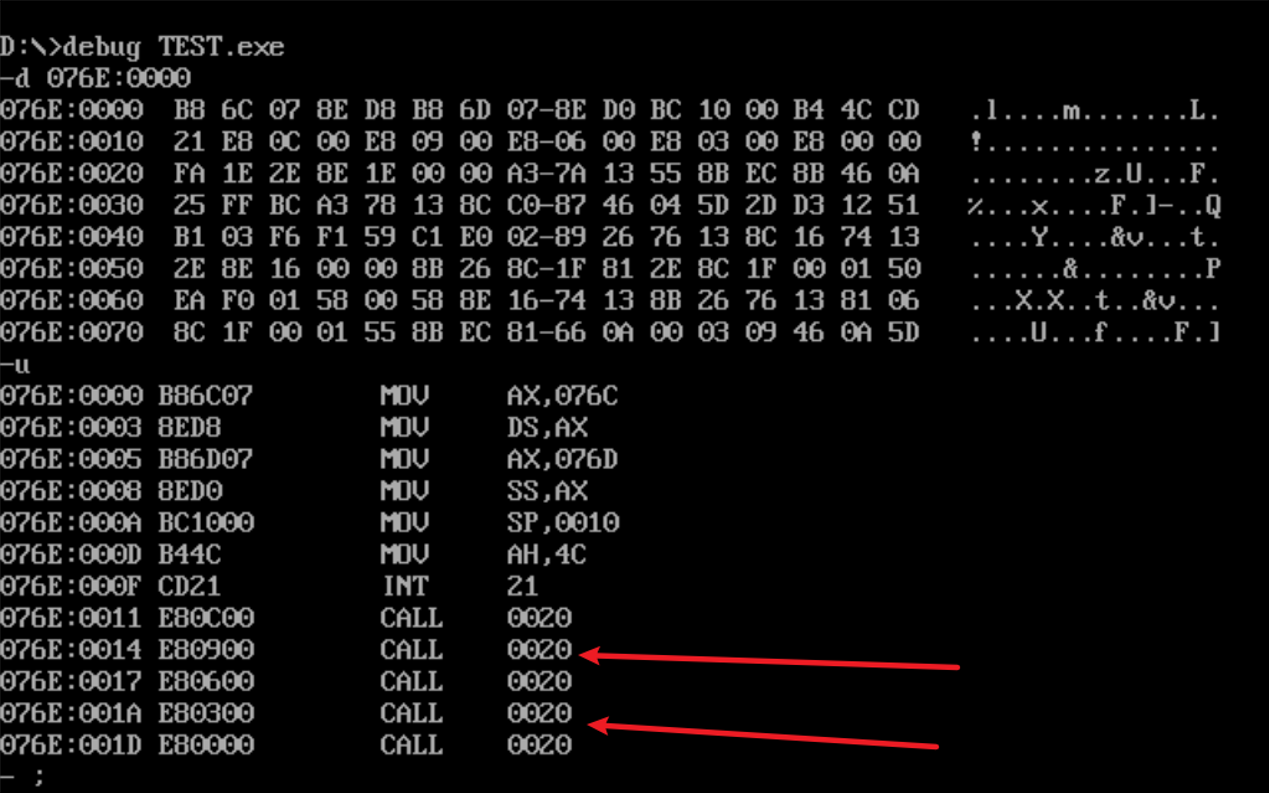
这里的情况很特殊,一般的段空间,由于8086寻址的特性,都是16的整数倍,但是这里的stack段,由于stack下面没有其他段,猜测当时为了节省内存空间,没有分配16的整数倍空间,而是要多少分配多少。具体实践如下图- 查看最后段的段空间分配情况
![]()
- 查看task1-1,task1-2,task1-3 code段后的内存分配情况
![]()
可以看到并非为0
- 查看最后段的段空间分配情况
-
任务1-5
基于上述四个实验任务的实践、观察,总结并回答:
问题1:
对于如下定义的段,程序加载后,实际分配给该段的内存空间大小是
当本段不是程序的最后一段时: \(\lceil \frac{N}{16} \rceil \times 16\)。
当本段是程序的最后一段时: \(N\)xxx segment db N dup(0) xxx ends问题2:
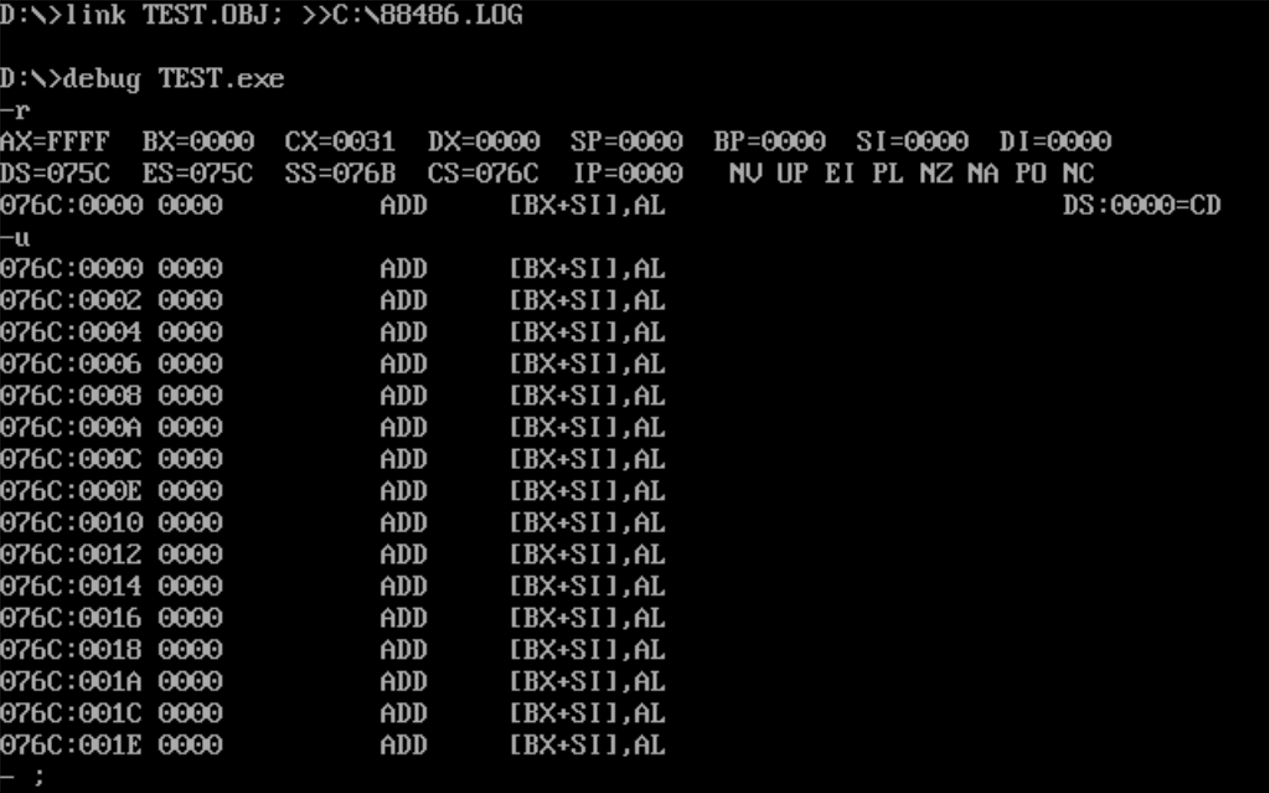
如果将程序task1_1.asm, task1_2.asm, task1_3.asm, task1_4.asm中,伪指令end start改成end, 哪一个程序仍然可以正确执行?结合实践观察得到的结论,分析、说明原因。
注意:本处正常执行指的是从start标号处开始执行,没从start标号处执行均视为不能正常执行- 程序task1-1.ASM
![]()
不能正常执行 - 程序task1-2.ASM
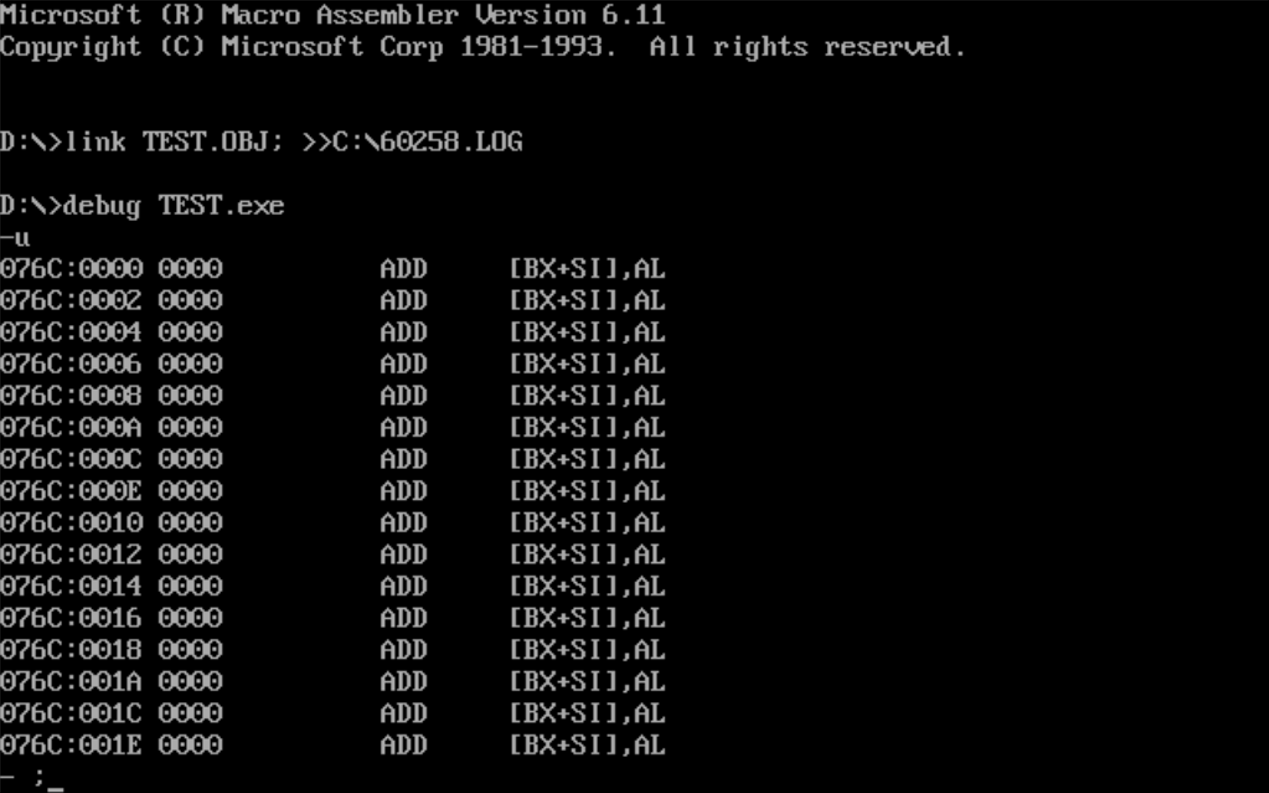
![]()
不能正常执行 - 程序task1-3.ASM
![]()
不能正常执行 - 程序task1-4.ASM
![]()
可以正常执行 - 分析
汇编器在处理汇编源程序的时候会先处理伪指令。start伪指令表示程序段从此处开始,会将code segment给CS段寄存器。由于start和end start需要成对出现,汇编器找到start后,却没找到end start,所以start无效,因此从程序段前缀之后开始执行程序,由于1,2,3个子任务的程序段前缀之后都是数据段,因为在8086汇编环境下,数据和指令处于同等地位,所以CPU无法辨别内存中的是指令还是数据,所以1,2,3个子任务不能正确完成期望的代码的执行。
- 程序task1-1.ASM
实验任务2
编写一个汇编源程序,实现向内存单元
b800:0f00~b800:0f9f连续160字节,依次重复填充十六进制数据03 04。
代码如下:
assume cs:code
code segment
start:
mov ax,0b800h
mov ds,ax
mov bx,0f00h
mov cx,80
p:
mov ds:[bx],0403h
inc bx
inc bx
loop p
mov ah,4ch
int 21h
code ends
end start
运行结果如下:
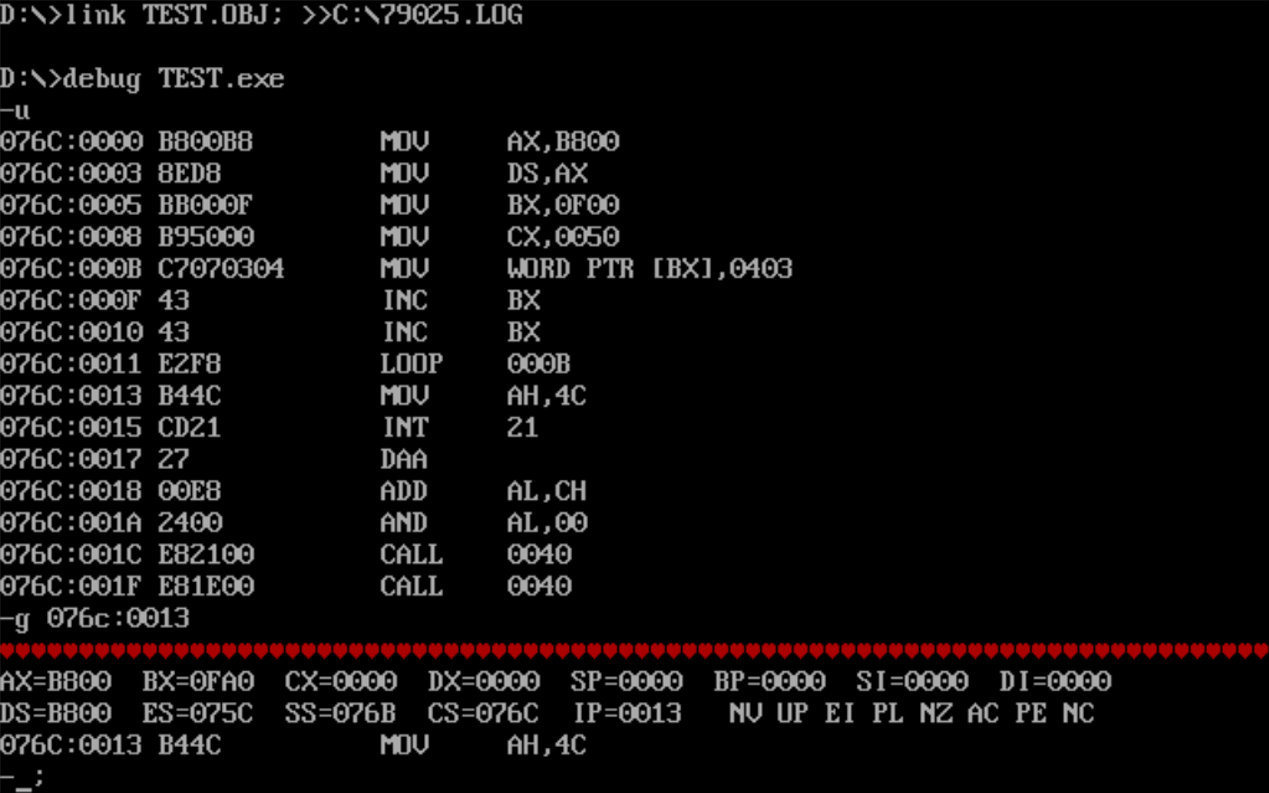
注意事项:
数字要以数字开头,所以b800h要写成0b800h,f00h同理,要写成0f00h
03 04 也需要注意,03是低位,04是高位,所以应该存0403h。
实验任务3
已知8086汇编源程序task3.asm代码片段如下。
assume cs:code
data1 segment
db 50, 48, 50, 50, 0, 48, 49, 0, 48, 49 ; ten numbers
data1 ends
data2 segment
db 0, 0, 0, 0, 47, 0, 0, 47, 0, 0 ; ten numbers
data2 ends
data3 segment
db 16 dup(0)
data3 ends
code segment
start:
; ×××
code ends
end start
要求:
① 编程实现把逻辑段data1和逻辑段data2的数据依次相加,结果保存到逻辑段data3中。
② 在debug中加载、反汇编、调试。在数据项依次相加前,和相加后,分别查看三个逻辑段data1,
data2, data3对应的内存空间,确认逐一相加后,结果的确保存在了逻辑段data3中。
问题1:
源代码如下:
assume cs:code
data1 segment
db 50, 48, 50, 50, 0, 48, 49, 0, 48, 49 ; ten numbers
data1 ends
data2 segment
db 0, 0, 0, 0, 47, 0, 0, 47, 0, 0 ; ten numbers
data2 ends
data3 segment
db 16 dup(0)
data3 ends
code segment
start:
mov ax,data1
mov ds,ax
mov cx,16
mov bx,0
s:
mov al,ds:[bx]
add al,ds:[bx+16]
mov ds:[bx+32],al
inc bx
loop s
mov ah,4ch
int 21h
code ends
end start
问题2:
运行结果如下,相加成功
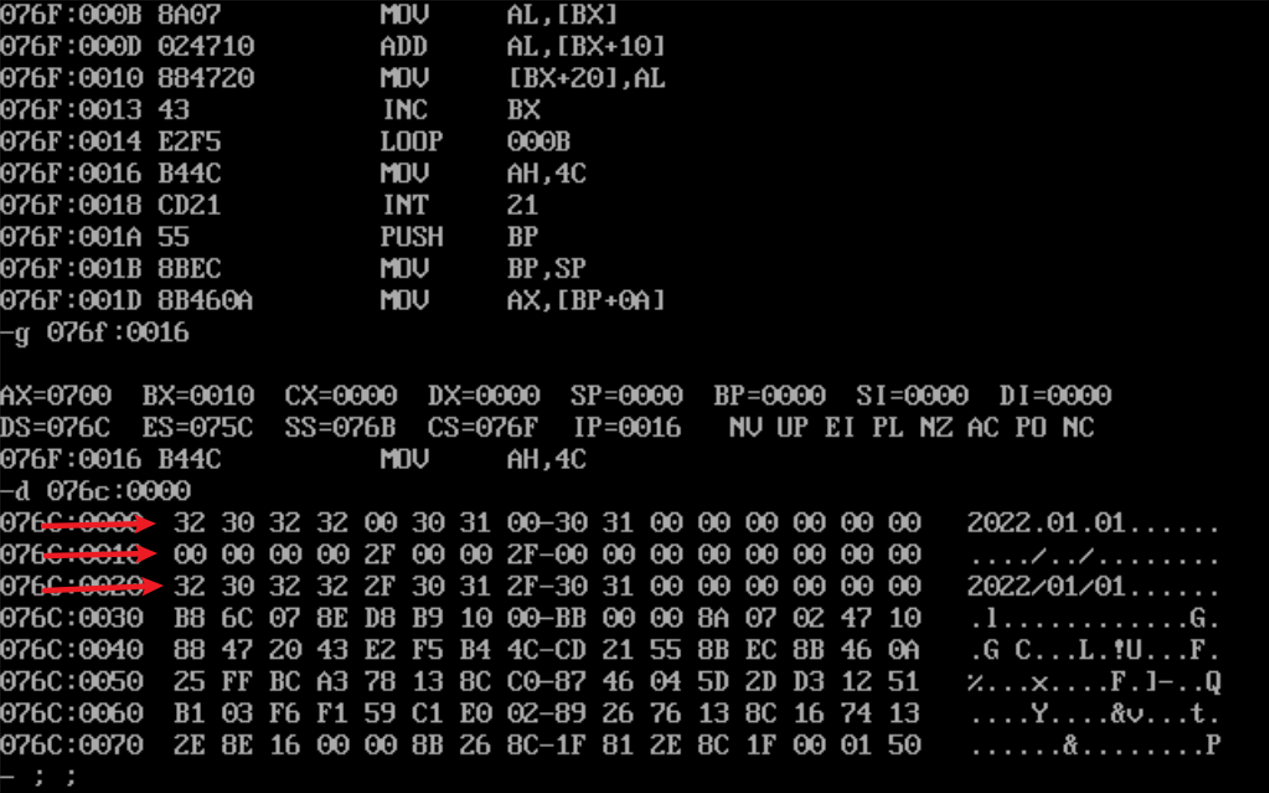
实验任务4
代码如下:
assume cs:code
data1 segment
dw 2, 0, 4, 9, 2, 0, 1, 9
data1 ends
data2 segment
dw 8 dup(?)
data2 ends
stack segment
db 16 dup(0)
stack ends
code segment
start:
mov ax,data1
mov ds,ax
mov ax,stack
mov ss,ax
mov sp,16
mov bx,0
mov cx,8
s1:
push ds:[bx]
inc bx
inc bx
loop s1
mov bx,16
mov cx,8
s2:
pop ds:[bx]
inc bx
inc bx
loop s2
mov ah, 4ch
int 21h
code ends
end start
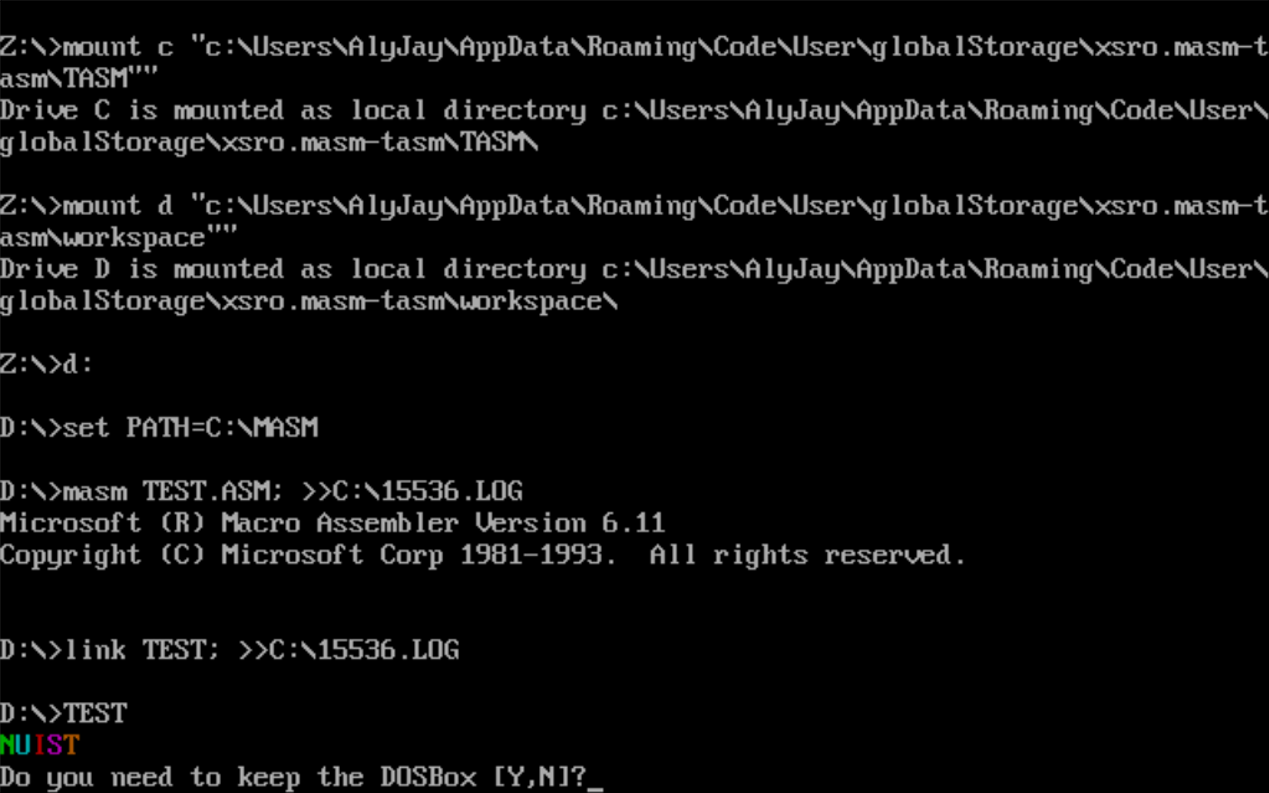
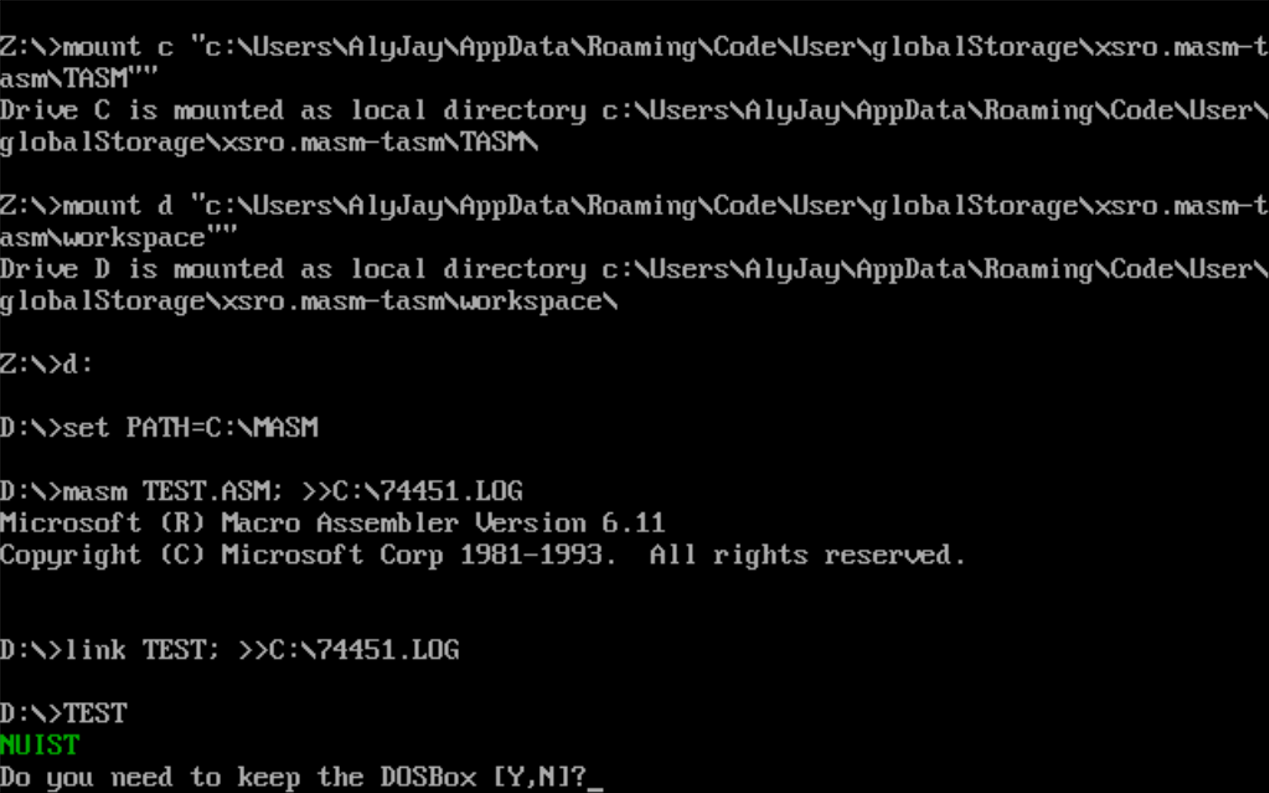
运行结果如下
分析:
使用栈先进后出的特性,完成逆序存放。因为栈每次放入一个字,数据也是一个字,非常完美的配合起来了。
实验任务5
-
问题1运行结果
![]()
-
问题2测试结果(line 25 line 27之前)
![]()
-
代码line19的作用是将所有字母转换为大写字母
将0dfh转换为二进制可得
11011111
大写字母ASCII码
0100 0001~0101 1010
小写字母ASCII码
0110 0001~0111 1010
可以观察得出,相差的位数就是第三位(从高到低,从1开始数)。
所以只需要将第三位置零,其他位保持不变即可。
所以只需要与上11011111即可,因为任意位数与上0得0,任意数字与上1不变。 -
问题4测试结果
![]()
分析以及猜测:
显示一个字符占一个字,低位字节表示是什么字母(ASCII码),第二个字节表示字符的显示参数,高四位表示字符的底色,低四位表示字符得颜色。
实验任务6
-
程序源代码
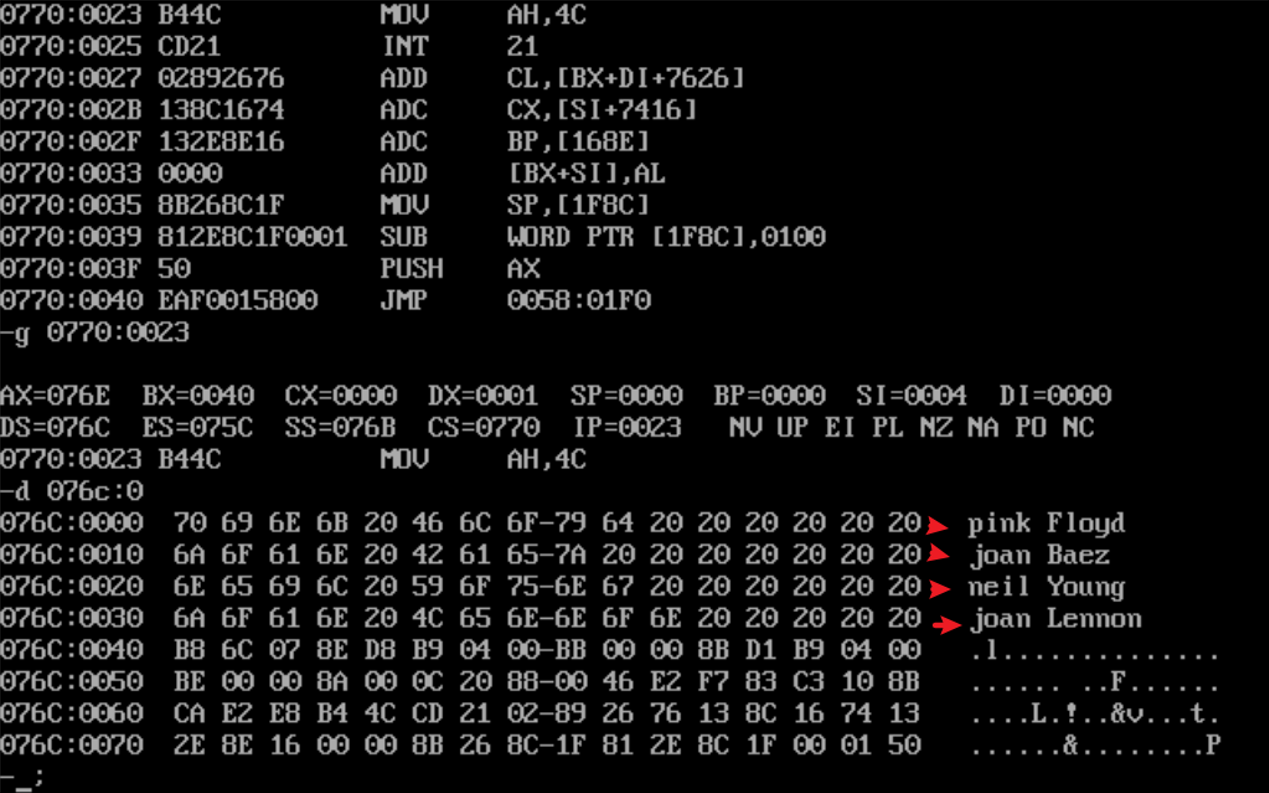
assume cs:code, ds:data data segment db 'Pink Floyd ' db 'JOAN Baez ' db 'NEIL Young ' db 'Joan Lennon ' data ends code segment start: mov ax,data mov ds,ax mov cx,4 mov bx,0 s: mov dx,cx mov cx,4 mov si,0 p: mov al,ds:[bx+si] or al,00100000B mov ds:[bx+si],al inc si loop p add bx,16 mov cx,dx loop s mov ah, 4ch int 21h code ends end start -
运行结果
![]()
分析:使用二重循环,dx用来暂存cx的值。此处也可以用栈来保存,但是由于只需要保存cx,所以可以暂时不用栈
实验任务7
assume cs:code, ds:data, es:table
data segment
db '1975', '1976', '1977', '1978', '1979' ;一个数字占4个字节,0起步,每次偏移量为4
dw 16, 22, 382, 1356, 2390 ;一个数字占一个字,20起步,每次偏移2
dw 3, 7, 9, 13, 28 ;一个数字占一个字,30起步,每次偏移2
data ends
table segment
db 5 dup( 16 dup(' ') ) ;
table ends
code segment
start:
mov ax,data
mov ds,ax
mov ax,table
mov es,ax
mov cx,5
mov bx,0
mov si,0
s:
mov ax,[bx+2]
mov es:[di+2],ax
mov ax,[bx]
mov es:[di],ax
mov ax,[si+20]
mov es:[di+5],0
mov es:[di+7],ax
mov ax,[si+30]
mov es:[di+11],ax
mov es:[di+9],0
mov ax,es:[di+7]
div byte ptr es:[di+11]
mov byte ptr es:[di+13],0
mov es:[di+14],al
add bx,4
add si,2
add di,16
loop s
mov ah, 4ch
int 21h
code ends
end start
程序运行截图
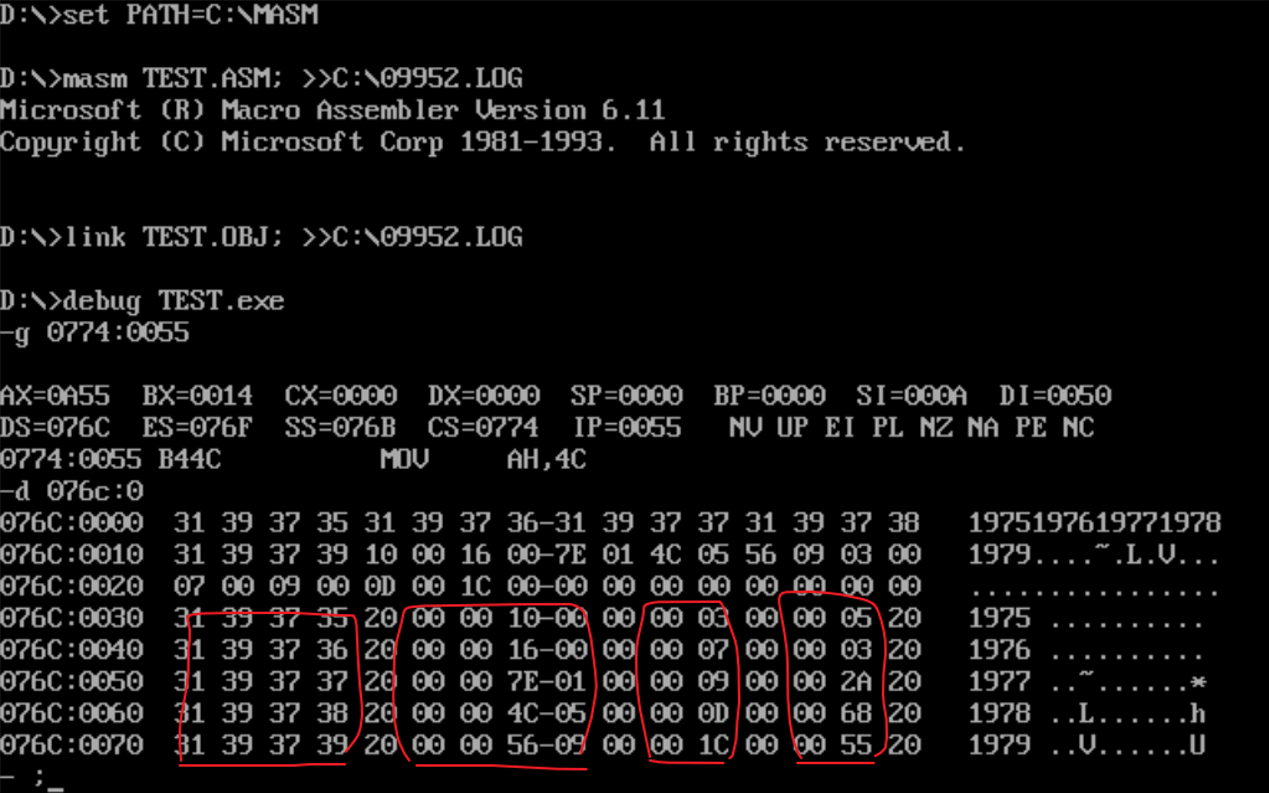
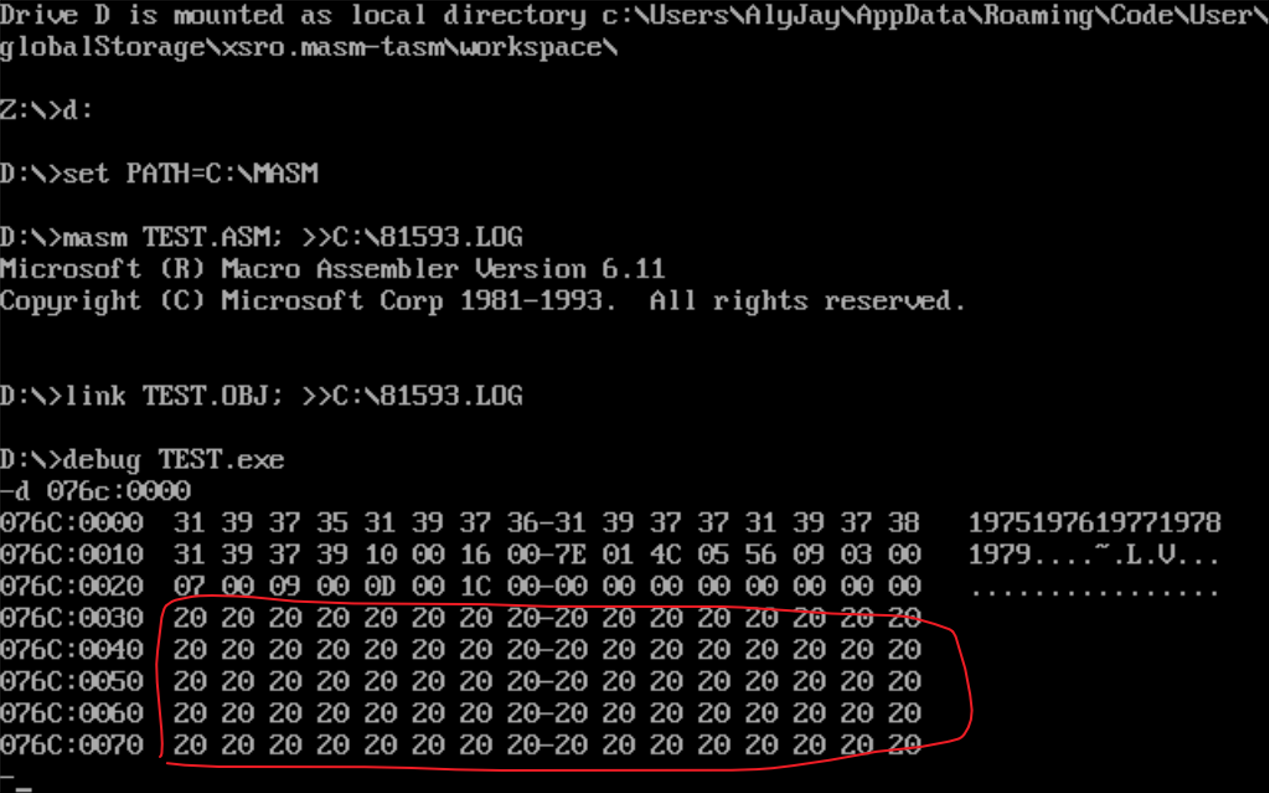
原始数据截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号