


python面试题
一、利用递归,列出某目录下所有文件
给定一个目录,如果目录下有文件,则打印出文件,如果是目录,则列出目录下的文件
import os
def print_directory_contents(sPath):
for sChild in os.listdir(sPath):
sChildPath = os.path.join(sPath,sChild)
if os.path.isdir(sChildPath):
print_directory_contents(sChildPath)
else:
print sChildPath
二、*args,**kwargs参数的区别
*args:将实参以元组的形式呈现
**kwargs:将关键词参数以字典形式呈现
def f(*args, **kwargs):
print args
print kwargs
f() #() {}
f(1,2,3) #(1, 2, 3) {}
f(1,2,3,"hello") #(1, 2, 3, 'hello') {}
f(a=1, b=2, c=3) #() {'a': 1, 'c': 3, 'b': 2}
f(1, 2, 3, a=1, b=2, c=3) #(1, 2, 3) {'a': 1, 'c': 3, 'b': 2}
def f(x, *args, **kwargs):
print args
print kwargs
f(1, 2, 3, a=1, b=2, c=3) #1传给x,args=(2, 3),kwargs={'a': 1, 'c': 3, 'b': 2}
三、Python中的可变对象和不可变对象
Python 在heap中分配的对象分成两类:可变对象和不可变对象。所谓可变对象是指,对象的内容是可变的,例如 list。而不可变的对象则相反,表示其内容不可变。
- 不可变对象:int,string,float,tuple
- 可变对象 :list,dictionary
1. 不可变对象
由于 Python 中的变量存放的是对象引用(reference),所以对于不可变对象而言,尽管对象本身不可变,但变量的对象引用是可变的。运用这样的机制,有时候会让人产生糊涂,似乎可变对象变化了。如下面的代码:

由上可知, 不可变的对象的特征没有变,依然是不可变对象,变的只是创建了新对象,改变了变量的对象引用,指向新的不可变对象。作如下验证:
a = 1 id(a) #16224600 b = 1 id(b) #16224600 #id函数返回对象的内存地址,可以看出a和b同为1,内存地址相同,这也是python的一个优点,同样的变量内容,节约地址,同时有个缺点,给a赋新值,需要解除原引用,再开辟新内存,所以效率低 a += 1 id(a) #16224576 id(b) #16224600
2.可变对象
其对象的内容是可以变化的。当对象的内容发生变化时,变量的对象引用是不会变化的(直接上原始内存空间处进行修改)。如下面的例子

n = [5,9] id(n) #139823627230384 #对象的内容虽然变了,但是内存并未变 n += [6] id(n) #139823627230384
四、列表,字典排序,下面的lambda k可以指定元组-sorted(listInput, key=lambda k: (k[1], k[5], k[6]), reverse=False)
#给定一个嵌套列表,如何根据每个元素的第一个元素排序
list_1 = [(1,'a'), (3,'c'), (2,'b')]
sorted(list_1, key=lambda k: k[0], reverse=True)#注:其实可以不用key的,sorted默认就是根据第一个元素排序
#[(3, 'c'), (2, 'b'), (1, 'a')]
#如果此题需要根据每个元素的第二个元素排序,则需要key参数了
list_1 = [(1,'c'), (3,'b'), (2, 'a')]
sorted(list_1, reverse=False, key=lambda k: k[1])
#[(2, 'a'), (3, 'b'), (1, 'c')]
#如果要操作的对象是字典的话,可以先调用dict.items()变成上述数据类型,然后排序
a = {'1': 'c', '3': 'a', '2': 'b'}
sorted(a.items(), key=lambda k: k[0], reverse=True)
#[('3', 'a'), ('2', 'b'), ('1', 'c')]
五、python中的e符号代表什么意思?
如me-5代表10的负5次方再乘以m
x = 0.1e-3
print("%f" %x)
#10的-3次方再乘以0.1 = 0.000100
x = 5e6
print("%f" %x)
#10的6次方再乘以5 = 5000000.000000
六、解释一下python中的and-or
与C表达式 bool ? a : b类似,但是注意:bool and a or b,当 a 为假时,不会象C表达式 bool ? a : b 一样工作
1 and 'hello a' or 'hello b'
#'hello a'
0 and 'hello a' or 'hello b'
#'hello b'
1 and '' or 'hello b'
#'hello b'
#上面未按照C语言的逻辑输出'',怎么回事?因为''在python中被当作False了
0 and '' or 'hello b'
#'hello b'
#python中的and-or要想实现C语言中的bool?a:b,可以这样做
def choose(bool, a, b):
return (bool and [a] or [b])[0]
#因为 [a] 是一个非空列表,它永远不会为假。甚至 a 是 0 或 '' 或其它假值,列表[a]为真,因为它有一个元素。
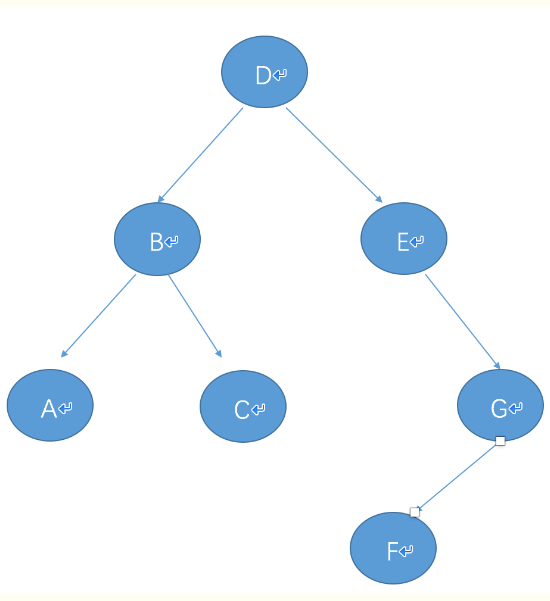
七、二叉树的遍历
构建二叉树:
class Node:
def __init__(self,value=None,left=None,right=None):
self.value=value
self.left=left #左子树
self.right=right #右子树
前序遍历/中序遍历/后序遍历:
def preTraverse(root):
'''
前序遍历
'''
if root==None:
return
print(root.value)
preTraverse(root.left)
preTraverse(root.right)
def midTraverse(root):
'''
中序遍历
'''
if root==None:
return
midTraverse(root.left)
print(root.value)
midTraverse(root.right)
def afterTraverse(root):
'''
后序遍历
'''
if root==None:
return
afterTraverse(root.left)
afterTraverse(root.right)
print(root.value)
验证一下程序:
if __name__=='__main__':
root=Node('D',Node('B',Node('A'),Node('C')),Node('E',right=Node('G',Node('F'))))
print('前序遍历:')
preTraverse(root)
print('\n')
print('中序遍历:')
midTraverse(root)
print('\n')
print('后序遍历:')
afterTraverse(root)
print('\n')

八、以下代码输出
def f(x, l=[]):
for i in range(x):
l.append(i * i)
print(l)
f(2)
f(3, [3,2,1])
f(4)
代码示例结果:
[0, 1] [3, 2, 1, 0, 1, 4] [0, 1, 0, 1, 4, 9]
理解: def f( l=[] ) 这种函数参数写法叫参数默认值,只会在函数声明是初始化一次。之后不会再变了
九、简述对venv(virtual environment)的理解
Python 的第三方包成千上万,在一个 Python 环境下开发时间越久、安装依赖越多,就越容易出现依赖包冲突的问题
为了解决这个问题,开发者们开发出了 virtualenv,可以搭建虚拟且独立的 Python 环境。这样就可以使每个项目环境与其他项目独立开来,保持环境的干净,解决包冲突问题
安装(python从 3.3 开始包含了 venv 程序,无需单独安装。 如果使用的是老版本的 Python, 需要额外安装 virtualenv):
pip install virtualenv
#python从 3.3 开始就提供了此工具 python3 -m venv my_project_venv
十、简述对python的scope以及Closure闭包的理解

